前言
在前面的文章中,我们已经学习了STL中底层为红黑树结构的一系列关联式容器——set/multiset 和 map/multimap(C++98)
1. unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2 N log2N,即最差情况下需要比较红黑树的高度次。
在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本一样,只是其底层结构不同。
本文中只对unordered_map和unordered_set进行介绍,
unordered_multimap和unordered_multiset大家可自行查看文档介绍。
2. map、set系列容器和unordered_map、unordered_set系列容器的区别
首先我们来简单说一下前面学的不带unordered的几个容器和这篇文章学习的unordered系列的容器有什么区别。
首先,它们的底层结构是不一样的:
我们前面学习的那一系列关联式容器——
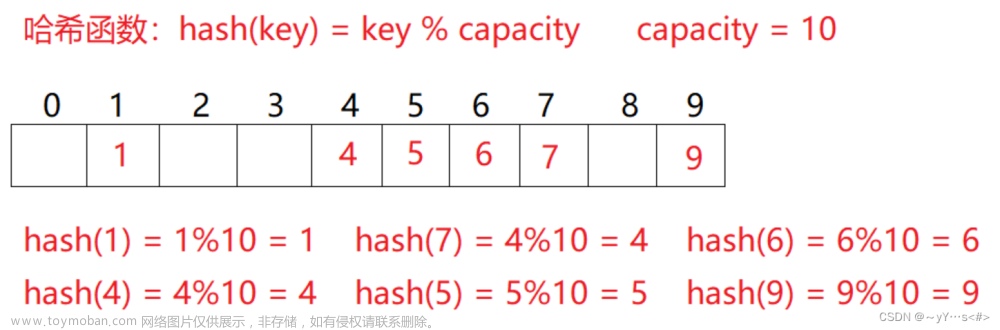
set/multiset 和 map/multimap它们的底层结构是红黑树,而我们这篇文章要学的unordered系列的——unordered_map/unordered_multimap、unordered_set/unordered_multiset它们的底层是哈希表,至于什么是哈希表,大家有的可能听说过,有的可能没有,没关系,我们后面会讲。
同样的,unordered系列中,带multi的和不带multi的区别也是允许键值重复出现和不允许重复出现的问题。
其次,从名字上我们其实就能得出它们的第二个区别:
unordered不就是无序的意思嘛。
所以,map和set我们用迭代器遍历,得到的是有序的序列,二unordered系列,我们去遍历的话,得到的是无序的。
其实单从使用上来说最大的区别就是这个。
那说到迭代器,它们的迭代器也是有区别的:
map和set系列它们的迭代器是双向迭代器,而unordered系列它们的迭代器是单向迭代器。
3. unordered_map和unordered_set的使用
其实单从使用来说,大家如果学会了我们之前讲的C++98的那几个关联式容器——set/multiset 和 map/multimap的使用的话,那C++11的这4个unordered系列的关联式容器其实大家就直接可以用了,因为它们的用法基本一致,常用的接口都差不多。
所以下面我们就简单介绍一下它们的使用,然后做一些练习,另外还有一些东西是需要我们学了它们的底层才能看懂的,这篇文章我们也先不做讲解。
首先我们可以看一下unordered_map的接口:
常用的接口还是那几个,跟map的用法一样,还有一些看不懂的,我们现在不用管,那些是跟他的底层结构哈希有关的。
另外我们会注意到它的迭代器没有rbegin、rend,因为它的迭代器是单向的嘛,都不支持反向遍历。

然后unordered_set我们也可以简单看一下:
接口也都差不多,只是set系列的没有[]和at接口

还是给大家简单演示一下它的使用吧:
这使用起来是不是跟set差不多啊,只不过我们看到它这里遍历是无序的。
当然也可以用迭代器遍历。
我们可以跟set对比一下


那unordered_map,也简单演示一下:
我们可以用unordered_map来跑一下那个统计次数的程序:
同样我们可以和map对比一下
其实还是有序无序的区别,只不过这里按照key排序,我们的key是汉字(水果名称),所以不太好看排序的效果。
当然这种场景的话其实顺序也不重要了。


那大家思考一下,既然它们好像跟map和set差不多,那为什么还要提高unordered系列呢?有什么优势吗?
其实在文档里面也有一些说明
比如我们看unordered_map
🆗,由于它底层使用的哈希结构,使得它们能够更快的按照键值去访问某个元素。

4. set与unordered_set性能对比
那我这里呢也提供了一段代码,以set和unordered_set为例来测试对比一下它们的性能:
因为unordered系列和非unordered系列它们底层的数据结构都是一样的,所以我们这里拿一组去对比就可以了
先看一下代码吧:
int main()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand((unsigned int)time(nullptr));
for (size_t i = 0; i < N; ++i)
{
v.push_back(rand());
//v.push_back(rand()+i);
//v.push_back(i);
}
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : v)
{
s.find(e);
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << endl;
size_t begin4 = clock();
for (auto e : v)
{
us.find(e);
}
size_t end4 = clock();
cout << "unordered_set find:" << end4 - begin4 << endl << endl;
cout << s.size() << endl;
cout << us.size() << endl << endl;;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
return 0;
}
简单解释一下这段代码:
其实就是搞了一个set和一个unordered_set,然后我们去控制产生一些随机数,先放到一个vector里面,再分别插入到set和一个unordered_set里面,对比它们插入、查找、删除的性能。
插入之后我们还统计了一下实际插入的个数,因为rand函数产生的随机数是有限的。
我们来测试几组:
先来10万个随机数
我们可以看到unordered_set三种操作都是比较快的,但是大家看到虽然我们产生10万个随机数,但是实际插入只有3万多个,因为rand产生的随机数会有大量重复值。

如果想减少数据有大量重复,可以用这个:
对每次产生的随机数加一个i,因为i每次是不同的嘛,这样重复数据肯定会减少
运行一下
大家自己对比一下


当然我们可以插入i,这样就没有重复值了

所以:
综合而言,unordered系列的效率是比较高的,尤其是find的效率(因为它底层的哈希结构,这个我们后面会讲)。
当然大家不要太关注我们上面的测试结果,因为可能在某些特定场景下unordered系列的插入删除这样操作不一定有map/set快(比如如果一直插入有序数据的话,set底层红黑树就会一直向一边旋转,最终就会比较平衡,那它的插入删除就不一定比unordered差了),但它的查找一定是很快的。
所以我们说的是综合各种场景而言,unordered系列的综合性能是较好的。
5. OJ练习
下面我们来做几道相关的OJ题
5.1 在长度 2N 的数组中找出重复 N 次的元素
题目链接: link
思路分析
这道题给我们一个长度为2n的数组,其中有一个元素恰好出现n次,我们要找到并返回这个元素。
那我们是不是统计出次数就好办了,统计出次数然后找到次数为n的返回就行了,那统计次数的话我们就可以用unordered_map(当然map也可以)。
AC代码
写一下代码:


class Solution {
public:
int repeatedNTimes(vector<int>& nums) {
int n=nums.size()/2;
unordered_map<int,int> m;
for(auto e:nums)
{
m[e]++;
}
for(auto e:m)
{
if(e.second==n)
return e.first;
}
return -1;
}
};
5.2 两个数组的交集
题目链接: link

这道题我们是不是前面刚做过啊,当时我们用set去搞的,set达到一个排序+去重的效果,然后就好办了(具体解法大家可以去看之前文章的讲解)。
那我们今天学的是unordered_set,它不会进行排序,那我们要怎么解决?
思路分析
那这道题其实只用unordered_set也能搞:
unordered_set虽然不能排序,但是也是可以去重的,首先我们先对两个数组进行去重。
然后,我们遍历其中一个数组,遍历的同时去依次判断当前元素在不在另一个数组中,如果在,就是交集。
AC代码


class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> s1(nums1.begin(),nums1.end());
unordered_set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
for(auto e:s1)
{
if(s2.find(e)!=s2.end())
{
ret.push_back(e);
}
}
return ret;
}
};
5.3 两个数组的交集 II
题目链接: link
来看这道题,是上一题的一个升级版,还是求交集,但是多了一些要去:
返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果在两数组中出现次数不一致,则考虑取较小值)。
但是它没有要去输出结果中每个元素是唯一的。
怎么搞?
思路分析
那这道题的关键其实在于控制这个次数:
最终返回的交集中,每个元素出现的次数要和它们在两个数组中出现的次数一样,如果在两个数组中出现次数不一样,则取较小值。
所以我们可以这样搞:
用unordered_map(当然map也可以)先统计出一个数组每个元素的个数。
然后遍历第二个数组,依次取每个元素判断其是否在map中存在等效键(用count接口),如果存在就是交集,放入vector里面并让其对应的次数–,如果次数减到0了,就从map中删除掉,因为此时它的个数已经等于它在两数组中出现次数的较小值了。
如果不删除,后面在第二个数组中再遇到的话,次数就会超。
如果但看思路不太理解的话可以结合下面的代码看。
AC代码


class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int,int> m;
vector<int> ret;
for(auto e:nums1)
{
m[e]++;
}
for(auto e:nums2)
{
if(m.count(e))
{
ret.push_back(e);
m[e]--;
if(m[e]==0)
{
m.erase(e);
}
}
}
return ret;
}
};
5.4 存在重复元素
题目链接: link
这道题给我们一个数组,如果存在任意一个值出现至少两次,就返回true,否则返回false。
思路分析
那这个太简单了,统计一下次数,判断有没有次数大于等于2的就行了
AC代码
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_map<int,int> m;
for(auto e:nums)
{
m[e]++;
}
for(auto e:m)
{
if(e.second>=2)
return true;
}
return false;
}
};

5.5 两句话中的不常见单词
题目链接: link
这道题其实就是让我们找出在两句话中只出现一次的那些单词。
思路分析
那其实思路很简单:
只要统计出这两句话中每个单词出现的次数就行了,次数为1的就是要找到不常用单词。
而这道题麻烦的是他给我们的是两个字符串,所以我们要统计单词次数的话可以先按空格把单词分割出来,放到一个vector里面,这样比较好统计。
AC代码
class Solution {
public:
vector<string> uncommonFromSentences(string s1, string s2) {
//加个空格,把两句话合二为一
string s=s1+' '+s2;
//按空格拆分句子中的单词放到vector里面
vector<string> v;
string word;
for(auto e:s)
{
if(e!=' ')
{
word+=e;
}
else
{
v.push_back(word);
word.clear();
}
}
//最后结束没有空格,所以要多push一次
v.push_back(word);
//统计次数
unordered_map<string,int> m;
vector<string> ret;
for(auto e:v)
{
m[e]++;
}
//只出现一次的单词就是不常用单词
for(auto e:m)
{
if(e.second==1)
{
ret.push_back(e.first);
}
}
return ret;
}
};
 文章来源:https://www.toymoban.com/news/detail-667100.html
文章来源:https://www.toymoban.com/news/detail-667100.html
6. 代码
#include <iostream>
using namespace std;
#include <unordered_map>
#include <unordered_set>
#include <vector>
#include <set>
#include <map>
void test_unordered_set()
{
unordered_set<int> s;
s.insert(1);
s.insert(5);
s.insert(3);
s.insert(8);
s.insert(2);
s.insert(3);
for (unordered_set<int>::iterator it = s.begin(); it != s.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
}
void test_unordered_map()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
unordered_map<string, int> m;
for (auto e : arr)
{
m[e]++;
}
for (auto& e : m)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
}
//int main()
//{
// const size_t N = 1000000;
//
// unordered_set<int> us;
// set<int> s;
//
// vector<int> v;
// v.reserve(N);
// srand((unsigned int)time(nullptr));
// for (size_t i = 0; i < N; ++i)
// {
// //v.push_back(rand());
// //v.push_back(rand()+i);
// v.push_back(i);
// }
//
// size_t begin1 = clock();
// for (auto e : v)
// {
// s.insert(e);
// }
// size_t end1 = clock();
// cout << "set insert:" << end1 - begin1 << endl;
//
// size_t begin2 = clock();
// for (auto e : v)
// {
// us.insert(e);
// }
// size_t end2 = clock();
// cout << "unordered_set insert:" << end2 - begin2 << endl;
//
//
// size_t begin3 = clock();
// for (auto e : v)
// {
// s.find(e);
// }
// size_t end3 = clock();
// cout << "set find:" << end3 - begin3 << endl;
//
// size_t begin4 = clock();
// for (auto e : v)
// {
// us.find(e);
// }
// size_t end4 = clock();
// cout << "unordered_set find:" << end4 - begin4 << endl << endl;
//
// cout << s.size() << endl;
// cout << us.size() << endl << endl;;
//
// size_t begin5 = clock();
// for (auto e : v)
// {
// s.erase(e);
// }
// size_t end5 = clock();
// cout << "set erase:" << end5 - begin5 << endl;
//
// size_t begin6 = clock();
// for (auto e : v)
// {
// us.erase(e);
// }
// size_t end6 = clock();
// cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
//
// return 0;
//}
 文章来源地址https://www.toymoban.com/news/detail-667100.html
文章来源地址https://www.toymoban.com/news/detail-667100.html
到了这里,关于【C++】unordered_map和unordered_set的使用 及 OJ练习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![【C++入门到精通】哈希 (STL) _ unordered_map _ unordered_set [ C++入门 ]](https://imgs.yssmx.com/Uploads/2024/02/714971-1.jpeg)





