语言:python 3
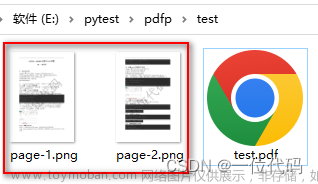
用法:选择PDF文件所在的目录,点击 确定 后,自动将该目录下的所有PDF转换成单个图片,图片名称为: pdf文件名.page_序号.jpg
如运行中报错,需要自行根据报错内容按照缺失的库
例如:
#安装库
pip install pyautogui
#安装库
pip install pillow这里提供两种源码,第一种是在代码中手动添加pdf所在目录文章来源:https://www.toymoban.com/news/detail-667287.html
import os
import glob
from PyPDF2 import PdfReader
from pdf2image import convert_from_path
pdf_dir = "path/to/pdf_dir/" #pdf目录
# 遍历目录中的PDF文件
pdf_files = glob.glob(os.path.join(pdf_dir, "*.pdf"))
# 遍历每个PDF文件,并将其转换为图片
for pdf_file in pdf_files:
# 创建PdfReader对象
pdf = open(pdf_file, 'rb')
pdf_reader = PdfReader(pdf)
# 遍历PDF的页面并将其转换为图片
for page_num in range(len(pdf_reader.pages)):
# 获取页面对象
page = pdf_reader.pages[page_num]
# 将PDF页面转换为图像
images = convert_from_path(pdf_file, first_page=page_num+1, last_page=page_num+1)
# 定义图像保存路径
filename = os.path.splitext(os.path.basename(pdf_file))[0]
image_path = os.path.join(pdf_dir, f"{filename}_page_{page_num+1}.jpg")
# 保存图像
for i, image in enumerate(images):
if i == 0:
image.save(image_path, "JPEG")
else:
image_path = os.path.join(pdf_dir, f"{filename}_page_{page_num+1}_{i+1}.jpg")
image.save(image_path, "JPEG")
# 关闭PDF文件
pdf.close()
第二种是点击运行后,弹出窗口选择PDF所在文件夹,程序运行对该文件夹下的所有PDF文件转换成图片文章来源地址https://www.toymoban.com/news/detail-667287.html
#手动选择目录下的pdf文件
import os
from tkinter import Tk
from tkinter.filedialog import askdirectory
from PyPDF2 import PdfReader
from pdf2image import convert_from_path
# 打开选择目录的对话框
Tk().withdraw() # 隐藏Tkinter根窗口
pdf_dir = askdirectory(title="选择PDF所在目录")
# 遍历目录中的PDF文件
pdf_files = [f for f in os.listdir(pdf_dir) if f.endswith(".pdf")]
# 遍历每个PDF文件,并将其转换为图片
for pdf_file in pdf_files:
# 创建PdfReader对象
pdf_path = os.path.join(pdf_dir, pdf_file)
pdf = open(pdf_path, 'rb')
pdf_reader = PdfReader(pdf)
# 遍历PDF的页面并将其转换为图片
for page_num in range(len(pdf_reader.pages)):
# 获取页面对象
page = pdf_reader.pages[page_num]
# 将PDF页面转换为图像
images = convert_from_path(pdf_path, first_page=page_num+1, last_page=page_num+1)
# 定义图像保存路径
filename = os.path.splitext(pdf_file)[0]
image_path = os.path.join(pdf_dir, f"{filename}_page_{page_num+1}.jpg")
# 保存图像
for i, image in enumerate(images):
if i == 0:
image.save(image_path, "JPEG")
else:
image_path = os.path.join(pdf_dir, f"{filename}_page_{page_num+1}_{i+1}.jpg")
image.save(image_path, "JPEG")
# 关闭PDF文件
pdf.close()
到了这里,关于python小脚本——批量将PDF文件转换成图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!