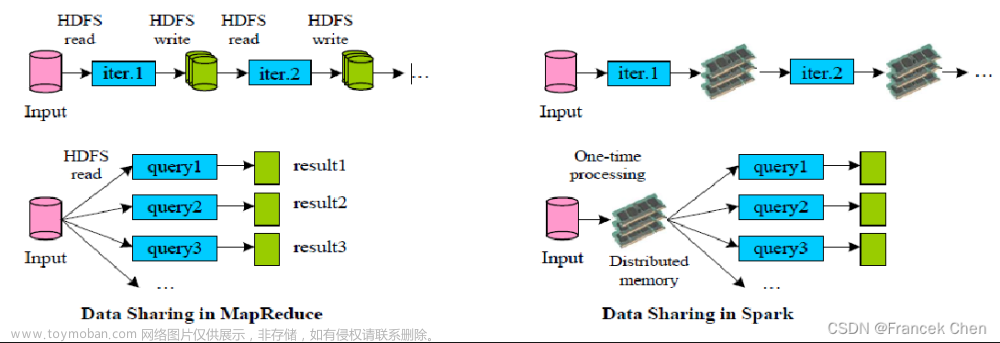
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解Spark的框架核心概念;
⚪ 掌握Spark的Spark集群模式安装;
⚪ 掌握Spark的Spark架构;
⚪ 掌握Spark的Spark调度模块;
一、Spark框架核心概念
1. RDD。弹性分布式数据集,是Spark最核心的数据结构。有分区机制,所以可以分布式进行处理。有容错机制,通过RDD之间的依赖关系来恢复数据。
2. 依赖关系。RDD的依赖关系是通过各种Transformation(变换)来得到的。父RDD和子RDD之间的依赖关系分两种:①窄依赖 ②宽依赖。
①针对窄依赖:父RDD的分区和子RDD的分区关系是:一对一。
窄依赖不会发生Shuffle,执行效率高,spark框架底层会针对多个连续的窄依赖执行流水线优化,从而提高性能。例如 map flatMap等方法都是窄依赖方法。
②针对宽依赖:父RDD的分区和子RDD的分区关系是:一对多。
宽依赖会产生shuffle,会产生磁盘读写,无法优化。
3. DAG。有向无环图,当一整条RDD的依赖关系形成之后,就形成了一个DAG。一般来说,一个DAG,最后都至少会触发一个Action操作,触发执行。一个Action对应一个Job任务。
4. Stage。一个DAG会根据RDD之间的依赖关系进行Stage划分,流程是:以Action为基准,向前回溯,遇到宽依赖,就形成一个Stage。遇到窄依赖,则执行流水线优化(将多个连续的窄依赖放到一起执行)。
5. task。任务。一个分区对应一个task。可以这样理解:一个Stage是一组Task的集合。
6. RDD的Transformation(变换)操作:懒执行,并不会立即执行。
7. RDD的Action(执行)操作:触发真正的执行。
二、Spark集群模式安装
1. 实现步骤
1. 上传解压spark安装包。
2. 进入spark安装目录的conf目录。
3. 配置spark-env.sh文件。
配置示例:
#本机ip地址
SPARK_LOCAL_IP=hadoop01
#spark的shuffle中间过程会产生一些临时文件,此项指定的是其存放目录,不配置默认是在 /tmp目录下
SPARK_LOCAL_DIRS=/home/software/spark/tmp
export JAVA_HOME=/home/software/jdk1.8
4. 在conf目录下,编辑slaves文件。
配置示例:
hadoop01
hadoop02
hadoop03
5. 配置完后,将spark目录发送至其他节点,并更改对应的 SPARK_LOCAL_IP 配置。
2. 启动集群
1. 如果你想让 01 虚拟机变为master节点,则进入01 的spark安装目录的sbin目录。
执行: sh start-all.sh
2. 通过jps查看各机器进程。
01:Master +Worker
02:Worker
03:Worker
3. 通过浏览器访问管理界面。
http://192.168.234.11:8080

4. 通过spark shell 连接spark集群。
进入spark的bin目录。
执行:sh spark-shell.sh --master spark://192.168.234.11:7077
5. 在集群中读取文件:
sc.textFile("/root/work/words.txt")
默认读取本机数据 这种方式需要在集群的每台机器上的对应位置上都一份该文件 浪费磁盘。
6. 所以应该通过hdfs存储数据。
sc.textFile("hdfs://hadoop01:9000/mydata/words.txt");
注:可以在spark-env.sh 中配置选项 HADOOP_CONF_DIR 配置为hadoop的etc/hadoop的地址 使默认访问的是hdfs的路径。
注:如果修改默认地址是hdfs地址 则如果想要访问文件系统中的文件 需要指明协议为file 例如 sc.text("file:///xxx/xx")。
三、Spark架构
1. 概述
为了更好地理解调度,我们先来鸟瞰一下集群模式下的Spark程序运行架构图。

1. Driver Program
用户编写的Spark程序称为Driver Program。每个Driver程序包含一个代表集群环境的SparkContext对象,程序的执行从Driver程序开始,所有操作执行结束后回到Driver程序中,在Driver程序中结束。如果你是用spark shell,那么当你启动 Spark shell的时候,系统后台自启了一个 Spark 驱动器程序,就是在Spark shell 中预加载的一个叫作 sc 的 SparkContext 对象。如果驱动器程序终止,那么Spark 应用也就结束了。
2. SparkContext对象
每个Driver Program里都有一个SparkContext对象,职责如下:
1. SparkContext对象联系 cluster manager(集群管理器),让 cluster manager 为Worker Node分配CPU、内存等资源。此外, cluster manager会在 Worker Node 上启动一个执行器(专属于本驱动程序)。
2. 和Executor进程交互,负责任务的调度分配。
3. cluster manager 集群管理器
它对应的是Master进程。集群管理器负责集群的资源调度,比如为Worker Node分配CPU、内存等资源。并实时监控Worker的资源使用情况。一个Worker Node默认情况下分配一个Executor(进程)。
从图中可以看到sc和Executor之间画了一根线条,这表明:程序运行时,sc是直接与Executor进行交互的。
所以,cluster manager 只是负责资源的管理调度,而任务的分配和结果处理它不管。
4.Worker Node
Worker节点。集群上的计算节点,对应一台物理机器
5.Worker进程
它对应Worder进程,用于和Master进程交互,向Master注册和汇报自身节点的资源使用情况,并管理和启动Executor进程
6.Executor
负责运行Task计算任务,并将计算结果回传到Driver中。
7.Task
在执行器上执行的最小单元。比如RDD Transformation操作时对RDD内每个分区的计算都会对应一个Task。
四、Spark调度模块
1. 概述

之前我们提到:Driver 的sc负责和Executor交互,完成任务的分配和调度,在底层,任务调度模块主要包含两大部分:
1. DAGScheduler
2. TaskScheduler
它们负责将用户提交的计算任务按照DAG划分为不同的阶段并且将不同阶段的计算任务提交到集群进行最终的计算。整个过程可以使用下图表示:

RDD Objects可以理解为用户实际代码中创建的RDD,这些代码逻辑上组成了一个DAG。
DAGScheduler主要负责分析依赖关系,然后将DAG划分为不同的Stage(阶段),其中每个Stage由可以并发执行的一组Task构成,这些Task的执行逻辑完全相同,只是作用于不同的数据。
在DAGScheduler将这组Task划分完成后,会将这组Task提交到TaskScheduler。TaskScheduler通过Cluster Manager 申请计算资源,比如在集群中的某个Worker Node上启动专属的Executor,并分配CPU、内存等资源。接下来,就是在Executor中运行Task任务,如果缓存中没有计算结果,那么就需要开始计算,同时,计算的结果会回传到Driver或者保存在本地。
2. Scheduler的实现概述

任务调度模块涉及的最重要的三个类是:
1. org.apache.spark.scheduler.DAGScheduler 前面提到的DAGScheduler的实现。
将一个DAG划分为一个一个的Stage阶段(每个Stage是一组Task的集合)。
然后把Task Set 交给TaskScheduler模块。
2. org.apache.spark.scheduler.TaskScheduler。
它的作用是为创建它的SparkContext调度任务,即从DAGScheduler接收不同Stage的任务。向Cluster Manager 申请资源。然后Cluster Manager收到资源请求之后,在Worker为其启动进程。
3. org.apache.spark.scheduler.SchedulerBackend。
是一个trait,作用是分配当前可用的资源,具体就是向当前等待分配计算资源的Task分配计算资源(即Executor),并且在分配的Executor上启动Task,完成计算的调度过程。
4. AKKA是一个网络通信框架,类似于Netty,此框架在Spark1.8之后已全部替换成Netty。文章来源:https://www.toymoban.com/news/detail-667667.html
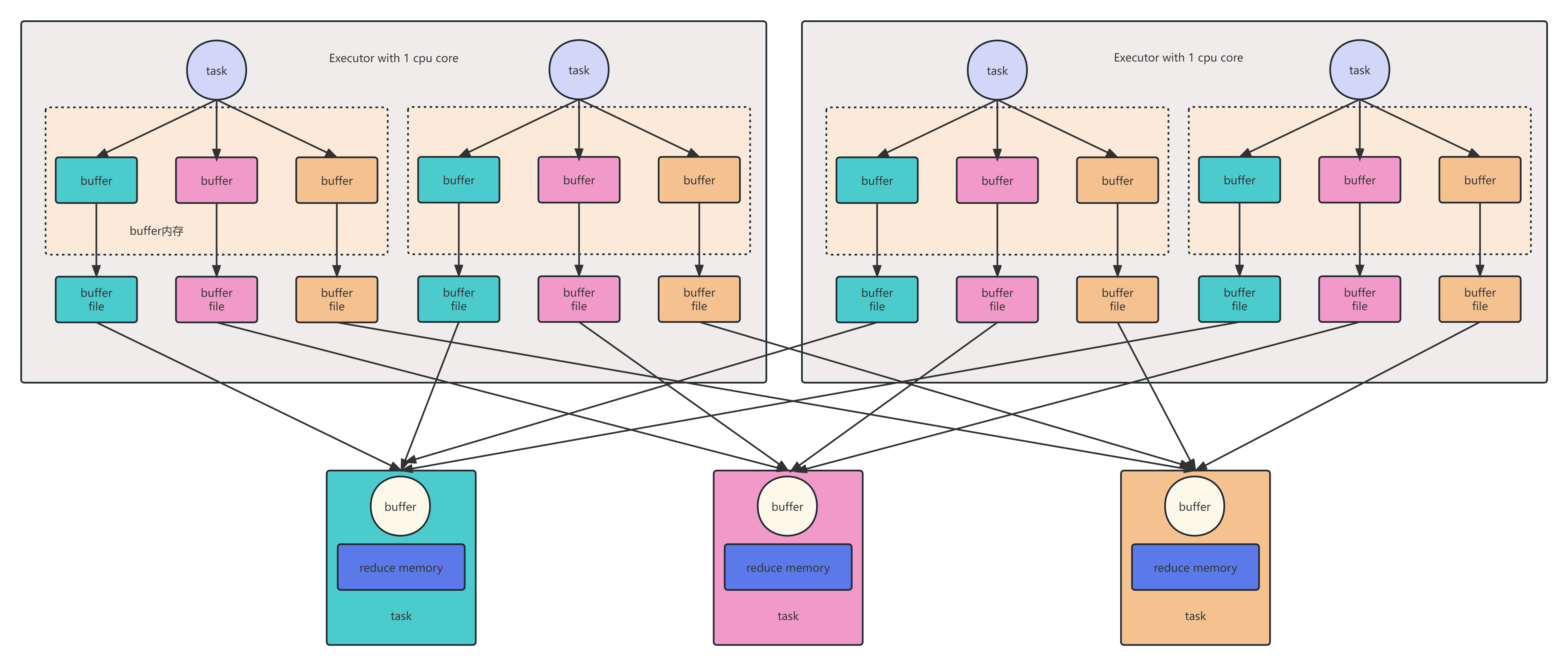
3. 任务调度流程图
 文章来源地址https://www.toymoban.com/news/detail-667667.html
文章来源地址https://www.toymoban.com/news/detail-667667.html
到了这里,关于大数据课程K5——Spark的框架核心概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!