XML
XML(Extensible Markup Language)是可扩展标记语言的缩写,它是一种数据表示格式,可以描述复杂的数据结构,常用于传输和存储数据
作用:
- 用于进行存储数据和传输数据
- 作为软件的配置文件
第一行是文档声明
<?xml version="1.0" encoding="UTF-8" ?>
version:XML默认的版本号码、该属性是必须存在的
encoding:本XML文件的编码
特殊字符
< < 小于
> > 大于
& & 和号
' ' 单引号
" " 引号
注释
<!-注释内容-->
文档约束
限定xml文件中的标签和属性
- DTD文档约束
- schema文档约束(约束能力更强大)
XML解析
使用程序读取XML内容
常用的解析工具
| JAXP |
SUN公司提供的一套XML的解析的API |
| JDOM |
JDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作。 |
| dom4j |
是JDOM的升级品,用来读写XML文件的。具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom 技术,同时它也是一个开放源代码的软件,Hibernate也用它来读写配置文件。 |
| jsoup |
功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便 |
dom4j解析XML元素
思想:得到文档对象document,从获取元素对象和内容
| List<Element> elements() |
得到当前元素下所有子元素 |
| List<Element> elements(String name) |
得到当前元素下指定名字的子元素返回集合 |
| Element element(String name) |
得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个 |
| String getName() |
得到元素名字 |
| String attributeValue(String name) |
通过属性名直接得到属性值 |
| String elementText(子元素名) |
得到指定名称的子元素的文本 |
| String getText() |
得到文本 |
XML检索:Xpath
Dom4j需要对文件进行全部解析,然后再寻找数据
Xpath技术更适合做信息检索
绝对路径
| /根元素/子元素/孙元素 |
从根元素开始,一级一级向下查找,不能跨级 |
public void parse01() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、直接检索:
List<Node> nodes = document.selectNodes("/contactList/contact/name");
for (Node node : nodes) {
Element nameEle = (Element) node;
System.out.println(nameEle.getTextTrim());
}
}相对路径
| ./子元素/孙元素 |
从当前元素开始,一级一级向下查找,不能跨级 |
public void parse02() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
Element root = document.getRootElement();
// c、直接检索:.代表的就是当前相对的根元素
List<Node> nodes = root.selectNodes("./contact/name");
for (Node node : nodes) {
Element nameEle = (Element) node;
System.out.println(nameEle.getTextTrim());
}
}全文搜索(直接全文搜索所有的name元素并打印)
| //contact |
找contact元素,无论元素在哪里 |
| //contact/name |
找contact,无论在哪一级,但name一定是contact的子节点 |
| //contact//name |
contact无论在哪一种,name只要是contact的子孙元素都可以找到 |
public void parse03() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、直接检索:
// List<Node> nodes = document.selectNodes("//name");
// List<Node> nodes = document.selectNodes("//contact/name");
List<Node> nodes = document.selectNodes("//contact//name");
for (Node node : nodes) {
Element nameEle = (Element) node;
System.out.println(nameEle.getTextTrim());
}
}属性查找(在全文中搜索属性或带属性的元素)
| //@属性名 |
查找属性对象,无论是哪个元素,只要有这个属性即可。 |
| //元素[@属性名] |
查找元素对象,全文搜索指定元素名和属性名。 |
| //元素//[@属性名=‘值’]文章来源:https://www.toymoban.com/news/detail-667948.html |
查找元素对象,全文搜索指定元素名和属性名,并且属性值相等。文章来源地址https://www.toymoban.com/news/detail-667948.html |
public void parse04() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索属性信息
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute attribute = (Attribute) node;
System.out.println(attribute.getName() + "=" + attribute.getValue());
}
// 检索元素的
List<Node> nodes1 = document.selectNodes("//contact[@id]");
for (Node node : nodes1) {
Element nameEle = (Element) node;
System.out.println(nameEle.elementTextTrim("name"));
}
// 检索元素
Node node = document.selectSingleNode("//contact[@id='3']");
Element conEle = (Element) node;
System.out.println(conEle.elementTextTrim("name"));
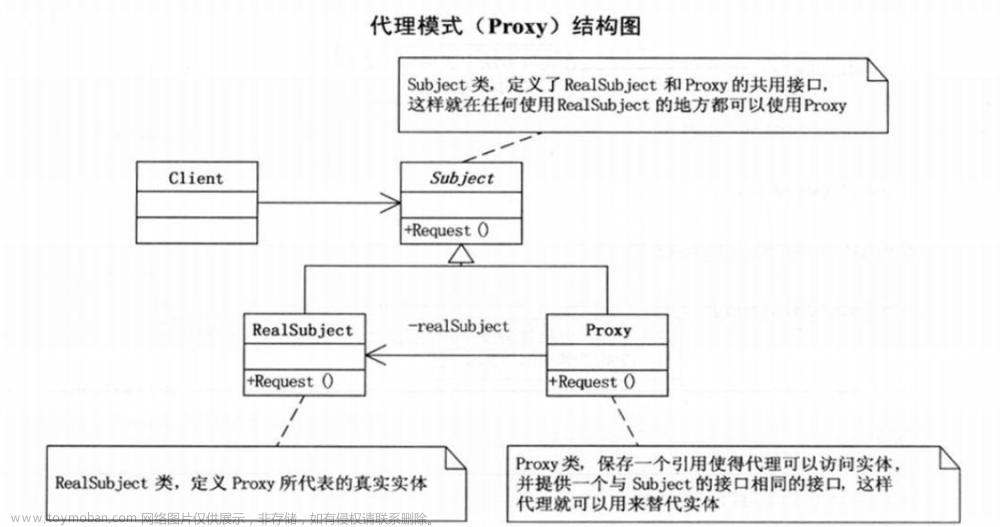
}设计模式
- 工厂模式:对象通过工厂的方法创建返回,工厂的方法可以为该对象进行加工和数据注入(可以实现类与类之间的解耦操作)
- 装饰模式:创建一个新类,包装原始类,从而在新类中提升原来类的功能(在不改变原类的基础上,动态的扩展一个类的功能)
到了这里,关于【JAVA】XML及其解析技术、XML检索技术、设计模式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!