入门
安装
键入命令:
apt-get install -y mysql-server
中间会要求你输入root密码。
接着安装mysql客户端:
apt-get install -y mysql-client
用以下命令登录mysql:
mysql -uroot -p你的密码
允许从远程机器登录mysql
编辑文件/etc/mysql/mysql.conf.d/mysqld.cnf,注释掉bind-address = 127.0.0.1
之后重启mysql:service mysql restart
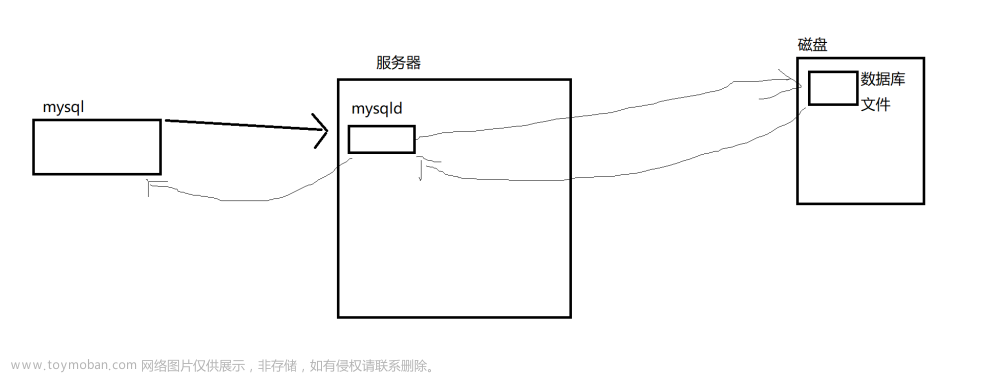
mysql的数据目录
mysqld.cnf里有一段:
basedir = /usr
datadir = /var/lib/mysql
windows下启动mysql
mysqld -install --defaults-file=D:\programs\mysql-5.7.32-winx64\my.ini
net start mysql
先将mysql安装为windows服务,再启动mysql。
–defaults-file指定启动的配置文件,若不指定,默认使用mysql根目录下的my.ini文件。
my.ini文件内容为:
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=D:\programs\mysql-5.7.32-winx64
# 设置mysql数据库的数据的存放目录
datadir=D:\programs\mysql-5.7.32-winx64\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8
启动失败,一是看datadir数据目录是否存在,二是在data目录下找到*.err文件,查看报错信息,再根据错误信息解决问题。
一些启动错误
查看报错信息如下:
2022-05-27T11:27:37.726092Z 0 [Warning] Failed to open optimizer cost constant tables
2022-05-27T11:27:37.728757Z 0 [ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.user' doesn't exist
2022-05-27T11:27:37.729532Z 0 [ERROR] Fatal error: Failed to initialize ACL/grant/time zones structures or failed to remove temporary table files.
2022-05-27T11:27:37.730635Z 0 [ERROR] Aborting
linux下键入如下命令解决:
mysql_install_db -user=mysql datadir=D:\programs\mysql-5.7.32-winx64\data
但windows下没法这么玩。
分析了一下,应该是mysql启动时库的初始化没做,先把datadir目录清空,再执行:
mysqld.exe --initialize --user=mysql --console
返回一个临时密码,记录下来。
接着使用
net start mysql
就能正常启动mysql了。
然后我们在mysql client里修改密码:
set password=password('新密码');
flush privileges;
注意:
password函数括号里是新的密码。password是一个专用的密码加密函数。
flush privileges是必须要的,否则下次重启后会报错。该命令本质上的作用是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。MySQL用户数据和权限有修改后,希望在"不重启MySQL服务"的情况下直接生效,那么就需要执行这个命令。通常是在修改ROOT帐号的设置后,怕重启后无法再登录进来,那么直接flush之后就可以看权限设置是否生效,而不必冒太大风险。
可以到mysql.user表里使用如下语句查询用户、密码信息:
select user,authentication_string from mysql.user;
authentication_string是加密过的登录密码。
设置新密码后,重启mysql会报错:
Access denied for user 'root'@'localhost' (using password: YES)
如前所述,我们改密码时要执行flush privileges命令。
常用命令
连接数据库
本地的:
mysql -u root -pXXX -P 3306 -D test
远程的加-h选项:
mysql -u admin -pXXXX -h XX.XX.XX.235 -P 3306 -D testdb
-D后跟数据库名。
查看版本
select version();
查看DB
show databases;
创建DB
create database testdb;
root用户赋予所有权限并允许从任意机器登录:
GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY "密码";
flush privileges;
注意:IDENTIFIED BY后跟的是root用户的密码。
创建用户并给用户授权
CREATE USER 'ares'@'%' IDENTIFIED BY '密码';
GRANT ALL ON aresdb.* TO 'ares'@'%';
flush privileges;
查看用户
select * from mysql.user
忘记用户密码
如果已登录但不记得用户密码,可使用如下语句修改密码:
update mysql.user set authentication_string=password('新密码') where user='root' and Host ='localhost';
flush privileges;
创建DB的用户,仅允许从本地登录
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER ON sdnctl.* TO sdnctl@localhost IDENTIFIED BY 'gamma';
flush privileges;
创建DB的用户,允许从任意机器登录
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER ON sdnctl.* TO sdnctl@'%' IDENTIFIED BY 'gamma';
flush privileges;
查看表
show tables;
查看用户可从哪台机器登录
select host,user from user;
查看表结构
desc 表名;
修改表结构
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
sleep函数
要这样写:
select sleep(15);
单位是秒。
sysdate和now函数
两者都是获得当前日期+时间,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值,后者会更精确。
要获得当前日期,用curdate()函数。
时间偏移
使用timestampadd,获取当前时间2小时前的时间:
select timestampadd(SECOND, -3600 , sysdate());
也可用DATE_SUB和DATE_ADD函数,这俩函数日期和时间都支持:
SELECT DATE_SUB(curdate(),INTERVAL 5 DAY);
SELECT DATE_SUB(sysdate(),INTERVAL 5 DAY);
SELECT DATE_SUB(sysdate(),INTERVAL 2 HOUR);
SELECT DATE_SUB(sysdate(),INTERVAL 7200 SECOND);
查看数据库连接
参考该文:
查看数据库连接
SHOW PROCESSLIST;
根据IP过滤数据库连接
select * from information_schema.processlist where Host like 'XX.XX.XX.127%';
数据库连接summary
show status like 'Threads%';
返回形如:
Variable_name Value
----------------- --------
Threads_cached 0
Threads_connected 49
Threads_created 160296
Threads_running 2
查看最大连接数
show variables like '%max_connections%';
设置最大连接数
临时设置:
mysql> SET GLOBAL max_connections = 250;
mysql一旦重启就会恢复默认值。
要永久生效,需修改/etc/mysql/mysql.conf.d/mysqld.cnf:
max_connections = 250
设置最大连接数的依据
我们得知道平均每个连接的内存消耗,网上有这么一段查询:
SELECT ( @@read_buffer_size
+ @@read_rnd_buffer_size
+ @@sort_buffer_size
+ @@join_buffer_size
+ @@binlog_cache_size
+ @@thread_stack
+ @@tmp_table_size
+ 2*@@net_buffer_length
) / (1024 * 1024) AS MEMORY_PER_CON_MB;
它表示的是一个连接最大可用的内存,在我的机器上这个值是18M。假设我们只用一半,四舍五入一下则每个连接的内存消耗是10M,一台16G内存的机器,至少可以同时开800个连接(差不多用8G的内存)。
参考原文。
作者统计每个连接内存占用的方法:
In general, I assume each connection, on average, will need about half of the available memory to it. That's been a pretty safe bet for a number of years now.
字符集和编码
查看mysql字符集
之前遇到过表的索引长度不能超过767字节限制的问题,这个是跟每个character的字节数相关的。
mysql字符集查看指令
show variables like 'character_set_%';
mysql字符集的支持细化到四个层次:
- 服务器(server)
- 数据库(database)
- 数据表(table)
- 连接(connection)
MySQL对于字符集的指定可以细化到一个数据库,一张表,一列应该用什么字符集。 但是,传统的程序在创建数据库和数据表时并没有使用那么复杂的配置,它们用的是默认的配置,那么,默认的配置从何而来呢?
(1)编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1;
(2)安装MySQL 时,可以在配置文件 (my.ini) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;
(3)启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时 character_set_server 被设定为这个默认的字符集;
(4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为character_set_server;
(5)当选定了一个数据库时,character_set_database 被设定为这个数据库默认的字符集;
(6)在这个数据库里创建一张表时,表默认的字符集被设定为 character_set_database,也就是这个数据库默认的字符集;
(7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集;
参考文章。
查看DB和表的字符集
SHOW CREATE DATABASE db_name;
SHOW CREATE TABLE tbl_name;
SHOW FULL COLUMNS FROM tbl_name;
mysql的charset和collate
charset用于给数据库确定使用哪种编码方式进行编码
collate叫做数据库的校验,就是一种对字符串进行比较的规则
stackoverflow上对charset和collate的解释:A character set is a set of symbols and encodings. A collation is a set of rules for comparing characters in a character set.
如何支持4字节emoji表情包
用utf8mb4编码代替utf8编码。
顺带说一下,一个库里的表最好是同一编码,因不同编码的表在做join时会有性能问题。
变量
用户定义变量
用户定义变量 是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用 “@变量 名” 使用就可以,其作用域为当前会话,即在会话1中定义的变量在会话2中是不能使用的; 注:之前讲的2个@符号是系统变量名,一个@符号是用户自定义变量 。
局部变量
局部变量 是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的 局部变量和输入参数,局部变量的范围是在其内声明的BEGIN … END块。
参考该文。
数据类型
bigint(20) 对应java里的long
括号里的数字代表字符显示宽度,跟存储字节数没多大关系。
显示宽度只是指明Mysql最大可能显示的数字个数,数值的位数小于指定的宽度时会由空格填充;
如果插入了大于显示宽度的值,只要该值不超过该类型的取值范围,数值依然可以插入,而且能够显示出来。
如果你不设置宽度,系统将添加默认的宽度tinyint(4)、smallint(6)、mediumint(9)、int(11)、bigint(20),这些默认的宽度是跟该类型的取值范围长度相关。
进阶
引擎
两种引擎:MyISAM和InnoDB。前者有两个缺点:
- 不支持事务
- 仅支持表锁,不支持行锁
因为上面的原因,实践中基本用的是InnoDB引擎。可用
show create table 表名;
来查看建表所用引擎。
主从和主备
主从模式和读写分离
MySQL Replication是MySQL官方提供的主从同步方案,用于将一个MySQL实例的数据,同步到另一个实例中。Replication为保证数据安全做了重要的保证,也是现在运用最广的MySQL容灾方案。Replication用两个或以上的实例搭建了MySQL主从复制集群,提供单点写入,多点读取的服务,实现了读的scale out。 该过程主要用到2个日志:
主库binlog:记录主库发生过的修改事件(默认针对所有的库和表,可以配置)
relay-log(中继日志):存储所有主库传输过来的binlog事件
配置主从模式可参考这里。
代码层面实现读写分离可参考这里。
核心思路是做多数据源,然后利用切面,对find、query、get等打头的函数走从库,对其他函数走主库。这样的话,业务层可以做到全无感知。
双主热备(双活)
MySQL双主复制,即互为Master-Slave,且只有一个Master提供写操作,可以实现数据库服务器的热备。但是一个Master宕机后不能实现动态切换。使用Keepalived,可以通过虚拟IP,实现双主对外的统一接口以及自动检查、失败切换机制,从而实现MySQL数据库的高可用方案。
双活对外呈现一个IP的候选方案:
keepalived:使用浮动ip,会遇到网关arp缓存不能及时更新的问题,导致切换时间较长(5min),暂搁置。
ProxySQL:数据库集群的代理节点。
互为主从下的必配参数
a、主库必须配置的参数
server-id (主从的server-id必须不同)、log_bin、binlog_format、relay-log、relay-log-index、relay_log_purge
auto-increment-offset、auto_increment_increment
b、log_slave_updates 意思是,中继日志执行之后,这些变化是否需要计入自己的bin-log。 当你的B服务器需要作为另外一个服务器的主服务器的时候需要打开。 就是双主互相备份,或者多主循环备份。 我们这里需要, 所以打开。
c、auto_increment_offset、auto_increment_increment 两个参数用于在 双主(多主循环)互相备份。 因为每台数据库服务器都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突。 解决这个问题的办法就是让每个数据库的自增主键不连续。 上图说是, 我假设需要将来可能需要10台服务器做备份, 所以auto_increment_increment设为10. 而 auto_increment_offset=1 表示这台服务器的序号。 从1开始, 不超过auto_increment_increment。这样做之后, 我在这台服务器上插入的第一个id就是 1, 第二行的id就是 11了, 而不是2.(同理,在第二台服务器上插入的第一个id就是2, 第二行就是12, 这个后面再介绍) 这样就不会出现主键冲突了。
为何要开启互为主从?
假设只有一台主A、一台从B,A宕机,B作为主机,由于B为从机,它不生成bin-log(只接收bin-log为relay-log),这时如果A修不好,要加入一台机器C,C就没办法从B那里获得bin-log了,需要人工转移数据。这种场景其实是一种链式场景:
A -> B -> C
B必须同时是A的从和C的主。
参考这里
主从和主备的区别
主从之间是通过mysql的replication来保证数据的一致性,replication是异步的,通过binlog和relay-log来做到。
主从可以是一主一从,也可是一主多从,后者可保证读的scale out,提高系统读效率。
主从的缺点是:不满足高可用,master宕机,需要手动切换才行,mysql可没有自动选举。
主备其实就是双主复制,互为主从,结合keepalived或proxysql对外以一个IP来访问。当其中的一个主down掉了,keepalived或proxysql自动会把请求切到备上,让备机成为新的主。因为之前已经设置了互为主从,所以备机有主机所有的数据。
主备针对的是高可用场景。
另外,主从下,从机是参与业务的(比如读扩展);主备下,备机是不参与业务的,只有主挂了,备才会变成主,接收主的业务。
主从复制
原理
步骤:
(1) Master的更新事件(update、insert、delete)会按顺序写入bin-log中。当Slave连接到Master后,Master机器会为Slave开启binlog dump线程,该线程会去读取bin-log日志;
(2) Slave连接到Master后,Slave库有一个I/O线程,到master上拉取bin-log日志,然后写入从库的relay log中;
(3) Slave还有一个 SQL线程,实时监控 relay-log日志内容是否有更新,并解析文件中的SQL语句,在Slave数据库中去执行。
说明:slave的SQL线程有可能是多个的,可用show variables like ‘%slave_parallel%’ 命令查看。
主从复制根据写入的可靠性,分为三种模式:
- 异步,默认模式,对一个写操作而言,主库写入自己的binlog就完了,不会等从库有没有写入成功;
- 同步, 主库写入自己的binlog还不算完,要等所有从库通知它说写入成功,才算成功。
- 半同步,折中方案,主库会等一个从库写入成功就算成功。
binlog详解
可使用如下命令查看主机binlog是否打开:
show global variables like 'log_bin%';
结果形如:
±--------------------------------±-------------------------------------------------+
| Variable_name | Value |
±--------------------------------±-------------------------------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/insts/ins01/blog/master-bin |
| log_bin_index | /var/lib/mysql/insts/ins01/blog/master-bin.index |
| log_bin_trust_function_creators | ON |
| log_bin_use_v1_row_events | OFF |
±--------------------------------±-------------------------------------------------+
如未打开,可在my.ini里配置:
[mysqld]
......
log-bin=mysql-bin
binlog-format=ROW
server_id=1
说明:即使单机模式,mysql也是可以开启binlog的,因为如前所述,binlog是主库写,从库拉取。主库只负责写就好了。
可用如下命令查看当前的binlog格式:
show global variables like 'binlog%';
返回结果形如:
+--------------------------------------------+--------------+
| Variable_name | Value |
+--------------------------------------------+--------------+
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | ABORT_SERVER |
| binlog_format | ROW |
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
| binlog_gtid_simple_recovery | ON |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_row_image | FULL |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | COMMIT_ORDER |
+--------------------------------------------+--------------+
binlog有三种格式:
- statement
- row
- mixed
所谓statement就是mysql把执行sql记到binlog里,row则是把受影响的row id记到binlog里,mixed是前面两者的混合。
statement有复制不准确的风险,因为sql语句的执行是有其上下文的。row格式就没有这个问题,但row格式可能产生大量的binlog。比如一条delete语句,删除10000行记录,用statement记的话,就一条binlog;但用row来记,就会有10000条binlog。
mixed类型是mysql自己来判断何时用statement、何时用row来记binlog。
在我们的系统中,mysql binlog一般使用的是row格式。这样,在删除大量记录的时候,会产生大量的binlog从而可能引发主从复制延迟。
查看所有的binlog文件:
show binary logs;
结果形如:
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 177 |
| mysql-bin.000002 | 550 |
+------------------+-----------+
可使用:
show binlog events in 'mysql-bin.000002';
查看文件里每条binlog的概要信息,结果形如:
+------------------+------+----------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+------+----------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------+
| mysql-bin.000002 | 550 | Anonymous_Gtid | 1 | 615 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000002 | 615 | Query | 1 | 715 | create database testdb |
| mysql-bin.000002 | 715 | Anonymous_Gtid | 1 | 780 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000002 | 780 | Query | 1 | 929 | use `testdb`; create table t_test(
id int,
desp varchar(255) null,
primary key (id)
) |
| mysql-bin.000002 | 929 | Anonymous_Gtid | 1 | 994 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000002 | 994 | Query | 1 | 1068 | BEGIN |
| mysql-bin.000002 | 1068 | Table_map | 1 | 1122 | table_id: 108 (testdb.t_test) |
| mysql-bin.000002 | 1122 | Write_rows | 1 | 1169 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 1169 | Xid | 1 | 1200 | COMMIT /* xid=19 */ |
| mysql-bin.000002 | 1200 | Anonymous_Gtid | 1 | 1265 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000002 | 1265 | Query | 1 | 1339 | BEGIN |
| mysql-bin.000002 | 1339 | Table_map | 1 | 1393 | table_id: 108 (testdb.t_test) |
| mysql-bin.000002 | 1393 | Write_rows | 1 | 1440 | table_id: 108 flags: STMT_END_F |
| mysql-bin.000002 | 1440 | Xid | 1 | 1471 | COMMIT /* xid=20 */ |
+------------------+------+----------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------+
若要看更细节的,使用mysqlbinlog命令看,形如:
mysqlbinlog --no-defaults data/mysql-bin.000002
–no-defaults选项建议加上,不然可能出现:
[ERROR] unknown variable 'default-character-set=utf8'
这样的错误。
每个Write_rows之前都有一个Table_map,用于描述表的内部ID和结构定义 。
每个Write_rows对应一条insert语句,通过mysqlbinlog看到的详情为:
#220528 9:39:33 server id 1 end_log_pos 1440 CRC32 0x41ad8b08 Write_rows: table id 108 flags: STMT_END_F
BINLOG '
VX2RYhMBAAAANgAAAHEFAAAAAGwAAAAAAAEABnRlc3RkYgAGdF90ZXN0AAIDDwL9AgLFZTiI
VX2RYh4BAAAALwAAAKAFAAAAAGwAAAAAAAEAAgAC//wCAAAABQBzd29yZAiLrUE=
'/*!*/;
# at 1440
一些更详细的信息都记录在BINLOG打头的一长串字符里,需要额外的工具(比如binlog2sql)来解析。但猜测,应该就是插入的记录详情。
Delete_rows则是删除记录,之前以为一个delete语句涉及到的每条记录都会产生一个Delete_rows事件,但实测下来,其实只有一个Delete_rows事件:
#220528 10:01:53 server id 1 end_log_pos 1723 CRC32 0xdaaea988 Delete_rows: table id 108 flags: STMT_END_F
BINLOG '
kYKRYhMBAAAANgAAAIAGAAAAAGwAAAAAAAEABnRlc3RkYgAGdF90ZXN0AAIDDwL9AgKcApWJ
kYKRYiABAAAAOwAAALsGAAAAAGwAAAAAAAEAAgAC//wBAAAABQBibGFkZfwCAAAABQBzd29yZIip
rto=
'/*!*/;
# at 1723
但,通过binlog2sql转化出的sql来看,在一个Delete_rows事件里,其实是记录了删除的每条记录信息的。
比如上述Delete_rows事件用binlog2sql转出的是多条sql:
DELETE FROM `testdb`.`t_test` WHERE `id`=1 AND `desp`='blade' LIMIT 1; #start 1471 end 1723 time 2022-05-28 10:01:53
DELETE FROM `testdb`.`t_test` WHERE `id`=2 AND `desp`='sword' LIMIT 1; #start 1471 end 1723 time 2022-05-28 10:01:53
Update_rows的情况跟Delete_rows一样,也是一条update语句对应一个Update_rows事件:
#220528 10:08:00 server id 1 end_log_pos 2870 CRC32 0x5b18c5d8 Update_rows: table id 108 flags: STMT_END_F
BINLOG '
AISRYhMBAAAANgAAAMkKAAAAAGwAAAAAAAEABnRlc3RkYgAGdF90ZXN0AAIDDwL9AgIc9Ihb
AISRYh8BAAAAbQAAADYLAAAAAGwAAAAAAAEAAgAC///8AQAAAAUAYmxhZGX8AQAAAAUAZHVtbXn8
AgAAAAUAc3dvcmT8AgAAAAUAZHVtbXn8AwAAAAYAYmFsb25n/AMAAAAFAGR1bW152MUYWw==
'/*!*/;
# at 2870
在一个Update_rows事件里同样包含多条受影响的记录:
UPDATE `testdb`.`t_test` SET `id`=1, `desp`='dummy' WHERE `id`=1 AND `desp`='blade' LIMIT 1; #start 2568 end 2870 time 2022-05-28 10:08:00
UPDATE `testdb`.`t_test` SET `id`=2, `desp`='dummy' WHERE `id`=2 AND `desp`='sword' LIMIT 1; #start 2568 end 2870 time 2022-05-28 10:08:00
UPDATE `testdb`.`t_test` SET `id`=3, `desp`='dummy' WHERE `id`=3 AND `desp`='balong' LIMIT 1; #start 2568 end 2870 time 2022-05-28 10:08:00
alter table语句(事件类型为Query)也只产生一条binlog:
#220528 10:12:15 server id 1 end_log_pos 3090 CRC32 0x1d604410 Query thread_id=2 exec_time=0 error_code=0
SET TIMESTAMP=1653703935/*!*/;
alter table t_test add desp1 varchar(255) NULL
/*!*/;
且并不像Update_rows和Delete_rows那样包含受影响的全部记录。
所以,alter table不像有的文章说的那样,产生大量的binlog,那是纯属想当然的说法!
binlog解析
可用binlog2sql工具解析。项目地址:
https://github.com/danfengcao/binlog2sql
下载后执行命令:
python binlog2sql.py -h127.0.0.1 -P3306 -uroot -pXXXX -dtestdb -t t_test --start-file=mysql-bin.000002
即可根据binlog打印出对应的SQL语句。
binlog格式的解析细节,待后面有时间、有机缘再说吧。
binlog格式选择
针对一条sql语句,mysql将其分为safe和unsafe,作为binlog格式的选择指导,指导原则如下:
When using row-based logging, no distinction is made in the treatment of safe and unsafe statements.
row格式的binlog直接无视safe与否
When using mixed-format logging, statements flagged as unsafe are logged using the row-based format; statements regarded as safe are logged using the statement-based format.
mixed格式的binlog,对safe语句用statement格式记录,对unsafe语句用row格式记录。
When using statement-based logging, statements flagged as being unsafe generate a warning to this effect. Safe statements are logged normally.
statement格式的binlog,unsafe语句会生成一条告警,safe语句照常处理。
因此,safe与否,主要针对的是statement格式而言。row格式始终是安全的。
下面文档里给出了一些不安全的语句。
典型的是update by limit:
UPDATE tbl SET foo = 'qux' ORDER BY rand() LIMIT 1
另外,对于有多个primary key或unique key的update on duplicate语句,也是不安全的:
When executed against a table that contains more than one primary or unique key, this statement is considered unsafe, being sensitive to the order in which the storage engine checks the keys, which is not deterministic, and on which the choice of rows updated by the MySQL Server depends.
我个人的理解,如果只有一些相对简单的用法(不含存储过程啥的),binlog用mixed格式能兼顾正确性和效率。
主从复制延迟
主从复制延迟对mysql的影响主要是数据不一致,如果不开启同步模式,倒不至于像mongodb那样,导致majority写挂死或超时,进而影响整个微服务系统的可用性。
但如果开启同步模式,对mysql的影响可能比mongodb还大,毕竟mongo只是majority写,而mysql是所有节点都要写入成功,更容易出现主节点上的mysql事务挂住的情况,进而影响整个微服务集群的可用性。
可使用如下命令查看主从延迟:
show slave status
查看输出中Seconds_Behind_Master参数的值 :
Seconds_Behind_Master=0: 表示主从复制良好;
Seconds_Behind_Master=NULL: 表示从库的io_thread或是sql_thread有任何一个发生故障;
Seconds_Behind_Master=79: 数字越大表示从库延迟越严重。
主从复制延迟大致有以下几个原因:
1)主节点如果有大量数据修改或执行一个很大的事务,就会对主从延迟产生较大的影响
2)网络延迟,日志较大,slave数量过多
3)主上多线程写入,从节点只有单线程同步
4)机器性能问题,从节点是否使用了“烂机器”
5)从机上的锁冲突问题也可能导致从机的SQL线程执行慢
一些缓解的手段:
1)大事务:将大事务分为小事务,或者分批更新数据
2)减少Slave的数量,不要超过5个,减少单次事务的大小
3)MySQL 5.7之后,可以使用多线程复制,使用MGR复制架构
4)在磁盘、raid卡、调度策略有问题的情况下可能会出现单个IO延迟很高的情况,可用iostat命令查看DB数据盘的IO情况,再进一步判断
5)针对锁问题可以通过抓去processlist以及查看information_schema下面和锁以及事务相关的表来查看
MGR(Mysql Group Replication)
MGR其实也是分布式系统的自然发展方向。传统的主从复制一旦主节点挂了,需要人工指定主。MGR是可以像mongodb、ES那样自动从从机中选举出一个主的。而且MGR是可以弹性扩容的。至于写入,MGR是同步的主从复制,还是majority写入?尚未研究过,存疑。文章来源:https://www.toymoban.com/news/detail-668244.html
感觉MGR跟mongodb的replica set已经很像了。文章来源地址https://www.toymoban.com/news/detail-668244.html
到了这里,关于mysql使用心得的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!