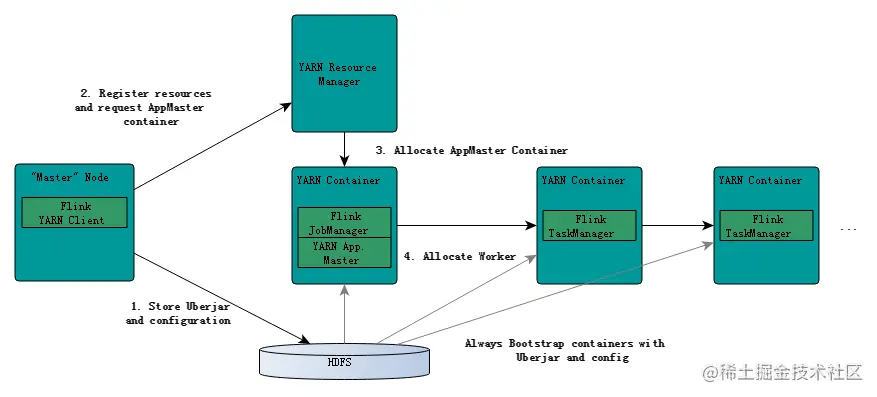
1、背景
当时,hive安装部署好,并没有这个问题,后面部署了 Flink On Yarn,就没有使用过hive了。
2、问题
(1)使用 bin/hive 的时候,会打印大量的INFO日志,不停的刷日志,sql语句这些能够正常执行(MR引擎或者Tez引擎都可以),但是其实无法正常使用。
(2)info日志如下所示:
(3)而后想通过启动 hiveserver2服务,使用DataGrip去连接操作Hive,这样至少不用看见那烦人的INFO日志了。。。事实是,sql语句无法正常跑下去。。。
3、解决办法
出现这个问题的原因:环境变量配置了HADOOP_CLASSPATH导致的。文章来源:https://www.toymoban.com/news/detail-668485.html
vim /etc/profile.d/my_env.sh
把最下面的注释掉或者删掉,重启服务器,重启集群,重新连接hive。
注意,除了source加载一次,一定要重启服务器哈(reboot)!!!!!!我就是栽在了这里,坑了半天。。。
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
下面这两个环境变量是在部署FLink On Yarn的时候用到的,为以后使用方便,我选择注释即可!!!
#export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
#export HADOOP_CLASSPATH=`hadoop classpath`
4、测试Hive是否正常

后面sql语句都正常使用。文章来源地址https://www.toymoban.com/news/detail-668485.html
到了这里,关于Hive产生大量Info日志的问题(由Flink On Yarn配置引起的)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[Flink] Flink On Yarn(yarn-session.sh)启动错误](https://imgs.yssmx.com/Uploads/2024/02/635597-1.png)