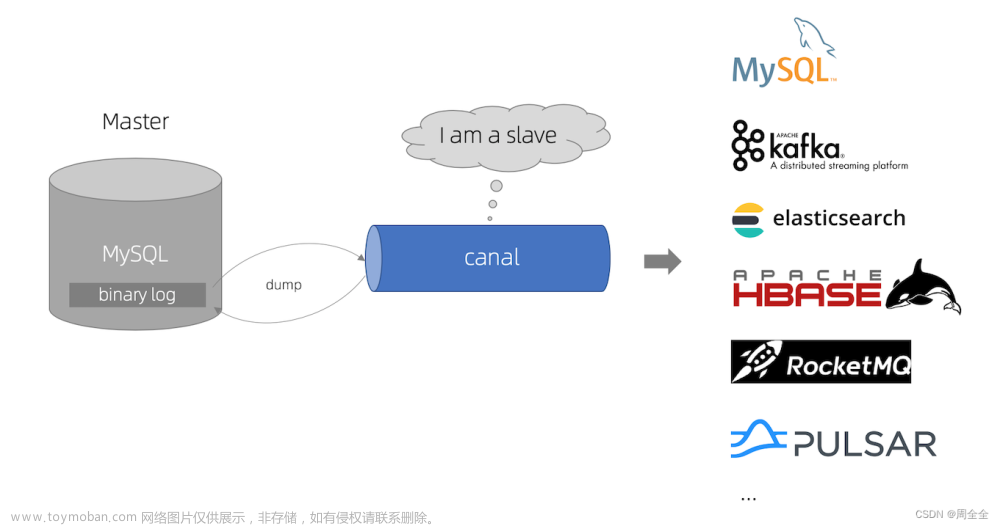
基于之前的文章,精简操作而来
- 让ELK在同一个docker网络下通过名字直接访问
- Ubuntu服务器ELK部署与实践
- 使用 Docker 部署 canal 服务实现MySQL和ES实时同步
- Docker部署ES服务,canal全量同步的时候内存爆炸,ES/Canal Adapter自动关闭,CPU100%
1. 拉镜像
docker pull elasticsearch:7.8.0
docker pull kibana:7.8.0
docker pull canal/canal-server:v1.1.5
docker pull slpcat/canal-adapter:v1.1.5-jdk8
docker pull mysql:5.7
2. mysql环境配置
2.1 新建mysql docker
首先新建数据库的docker镜像
docker run -p 3306:3306 --name mysql \
-v /data/mysql/log:/var/log/mysql \
-v /data/mysql/data:/var/lib/mysql \
-v /data/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
2.2 修改配置重启
接下来去/data/mysql/conf路径下,新建my.cnf文件,输入以下内容
[mysqld]
#binlog setting
log-bin=mysql-bin # 开启logbin
binlog-format=ROW # binlog日志格式
server-id=1 # mysql主从备份serverId,canal中不能与此相同
docker restart重启mysql
2.3 验证配置结果
新建新闻表
CREATE SCHEMA MyTest;
use MyTest;
create table News
(
id INT(11),
title VARCHAR(2125),
desc VARCHAR(2125),
image VARCHAR(2125),
url VARCHAR(2125),
source VARCHAR(2125),
date Date
)DEFAULT CHARSET=utf8;
检查该新闻表的状态
mysql -u root -p // mysql登录
>show databases;
>use MyTest; // 开启数据库
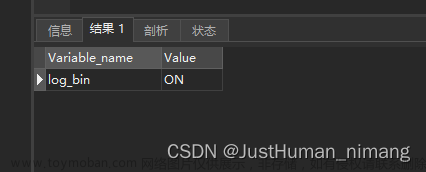
>show variables like 'log_%';
>show variables like 'binlog_format';
>show master status; // binlog日志文件 mysql-bin.000001
>reset master; // 重置日志

2.4 查看日志文件
cd /var/lib/mysql // 进入日志文件目录
mysqlbinlog -vv mysql-bin.000001 // row格式查看日志

3. ES+Kibana环境配置
3.1 前置准备
修改内存最大容量
# 查看参数大小
cat /proc/sys/vm/max_map_count
# 设置参数
sysctl -w vm.max_map_count=262144
设置mynetwork
本想用的bridge,发现bridge
-
创建一个自定义网络(执行到这里就可以了):
## 查看已有网络 docker network ls ## 新建网络 docker network create mynetwork -
启动容器时,将它们连接到相同的网络并分配容器名称:
docker run -d --name containerA --network mynetwork imageA docker run -d --name containerB --network mynetwork imageB在这个例子中,我们将容器A和容器B连接到同一个名为
mynetwork的网络,并分别分配了容器名称containerA和containerB。 -
在容器A中通过容器名称访问容器B:
ping containerB- 对于已经启动的Docker放入到指定网络
docker network connect <network_name_or_id> <container_name_or_id>
3.2 ES(单节点模式部署)
#安装elasticsearch,创建一个elk文件夹, 后面的elk日志采集系统的配置文件都放在这里面
#创建elk使用配置文件的目录
mkdir -p /data/elk
#创建es使用的目录
mkdir /data/elk/conf -p
#配置es的配置文件
cat >/data/elk/conf/elasticsearch.yml<<'EOF'
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# 访问ID限定,0.0.0.0为不限制,生产环境请设置为固定IP
transport.host: 0.0.0.0
# elasticsearch节点名称
node.name: node-1
# elasticsearch节点信息 单节点模式关闭这个
# cluster.initial_master_nodes: ["node-1"]
# 下面的配置是关闭跨域验证可以实现浏览器查看es的数据
http.cors.enabled: true
http.cors.allow-origin: "*"
EOF
#创建es使用的存储卷把数据映射出来
[root@centos7 ~]# docker volume create elasticsearch
elasticsearch
#创建并启动elasticsearch容器
docker run -di -p 9200:9200 -p 9300:9300 --name=elasticsearch --network mynetwork -v /data/elk/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" --mount src=elasticsearch,dst=/usr/share/elasticsearch elasticsearch:7.8.0
#把宿主机的配置文件映射到es作为配置文件
/data/elk/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
#把es的容器安装目录映射到宿主机
--mount src=elasticsearch,dst=/usr/share/elasticsearch
#创建成功
[root@centos7 elasticsearch]# docker run -di -p 9200:9200 -p 9300:9300 --name=elasticsearch -v /data/elk/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml --mount src=elasticsearch,dst=/usr/share/elasticsearch elasticsearch:7.6.0
317d2a274ec64500c44a7c8c0bea60175c2183a66e8e6e8a5554bc223e836e58
#对存储卷创建软连接实现快速访问
/data/docker/volumes/elasticsearch/_data/
ln -s /data/docker/volumes/elasticsearch/_data/ /data/elk/es
测试是否安装成功
[root@centos7 es]# curl 127.0.0.1:9200
{
"name" : "node-1",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "CK6xnBvaTciqRtWhjZf7WA",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
注意:如果需要添加插件时,需要将容器的插件目录映射到实际的路径中或者通过命令
(如安装ik分词器:docker cp ik elasticsearch:/usr/share/elasticsearch/plugins/)将其拷贝到容器中
3.3 kibana
#安装kibana
#kibana主要用于对elasticsearch的数据进行分析查看。注意选择的版本必须和elasticsearch的版本相同或者低,建议和elasticsearch的版本相同,否则会无法将无法使用kibana。
#创建配置文件
cat >/data/elk/conf/kibana.yml<<'EOF'
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch:9200"] # 这里需要参考我下面的docker网络访问配置
# 操作界面语言设置为中文
i18n.locale: "zh-CN"
EOF
#创建kibana使用的容器卷
docker volume create kibana
#创建并启动kibana容器
docker run -di --name kibana -p 5601:5601 --network mynetwork -v /data/elk/conf/kibana.yml:/usr/share/kibana/config/kibana.yml --mount src=kibana,dst=/usr/share/kibana kibana:7.8.0
#把宿主机的kibana配置文件映射到容器内部
# -v /data/elk/conf/kibana.yml:/usr/share/kibana/config/kibana.yml
#把容器内的kibana的安装目录映射到宿主机的容器卷方便管理
# --mount src=kibana,dst=/usr/share/kibana
#创建kibana容器卷的软连接方便管理
ln -s /data/docker/volumes/kibana/_data/ /data/elk/kibana
此时直接curl 127.0.0.1:5601,有可能遇到问题Kibana server is not ready yet,解决方法参考kibana解决Kibana server is not ready yet问题。一般都是docker内部网络访问配置没配置好的问题
如果有需要配置密码,参考kibana+nginx配置密码 ubuntu
4. Canal Server+Adapter环境配置
4.1 Canal Server
首先安装canal-server,复制配置文件到外面
# 启动docker
docker pull canal/canal-server:v1.1.5
docker run --name canal-server -id canal/canal-server:v1.1.5
mkdir -p /data/canal/canal-server
# 复制配置文件(注意,复制的时候,如果目标路径是/conf/,那就会在conf中创建一个新的文件夹用来接收复制文件。如果是/conf,那句直接复制到该文件夹下)
docker cp canal-server:/home/admin/canal-server/conf/ /data/canal/canal-server/conf
docker cp canal-server:/home/admin/canal-server/logs/ /data/canal/canal-server/logs
# 删除并重新启动
docker stop canal-server && docker rm canal-server
docker run --name canalsever_1.1.5 -p 11111:11111 \
-v /data/canal/canal-server/conf/example/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /data/canal/canal-server/conf/canal.properties:/home/admin/canal-server/conf/canal.properties \
-v /data/canal/canal-server/logs/:/home/admin/canal-server/logs/ \
--network mynetwork \ # 这个是我“让ELK在同一个docker网络下通过名字直接访问”博客中新建的网络,以后所有127.0.0.1都写成docker的name就可以
-d canal/canal-server:v1.1.5
修改Server配置文件example/instance.properties 
注意,canal.properties中的destination要和后续的Canal Adapter保持一致
验证服务是否启动成功
docker exec -it [c_id]/bin/bash
cd canal-server/bin/
./start.sh // 启动服务
cd canal-server/logs/example/
tail -100f example.log // 查看日志

4.2 Canal Adapter
# 启动docker
docker pull slpcat/canal-adapter:v1.1.5-jdk8
docker run --name canal-adapter -id slpcat/canal-adapter:v1.1.5-jdk8
# 复制配置文件
docker cp canal-adapter:/opt/canal-adapter/conf /data/canal/canal-dapter/conf
docker cp canal-adapter:/opt/canal-adapter/logs /data/canal/canal-dapter/conf
# 删除并重新启动
docker stop canal-adapter && docker rm canal-adapter
docker run --name canal-adapte_1.1.5 -p 8081:8081 \
-v /data/canal_/canal-dapter/conf:/opt/canal-adapter/conf \
-v /data/canal_/canal-dapter/logs:/opt/canal-adapter/logs \
--network mynetwork \
-d slpcat/canal-adapter:v1.1.5-jdk8
修改两处配置文件
配置文件取消注释一定要自己手动删除#,不要用快捷键。否则会导致文件格式出问题
配置文件详解
ClientAdapter: Canal的Adapter配置项目 application.ym(application.yml)
Sync ES:Canal的Adapter中ES同步的配置项 (user.yml)
修改配置文件application.yml。


name logger就是在发生数据修改的时候,直接实时更新到log中,如下图
修改完上述配置,可以看到name为es的canalAdapters被启动了。因此要去es文件夹下修改,注意以下字段的配置。目前只是能够运行起来,至于业务实际应用可能还有待验证。

修改启动脚本,使adapter稳定运行
以下修改方案基于slpcat/canal-adapter:v1.1.5-jdk8修改
首先docker exec进入到容器内部,修改启动脚本vi bin/startup.sh
我修改了两个地方文章来源:https://www.toymoban.com/news/detail-669075.html
- if else判断的地方,我直接指定JAVA_OPTS为非x64系统的配置
- 修改了原先的
-Xms和-Xmx,变成了新的104m和512m (随便设置的,就想着要小一点),以及增加了新的参数-XX:MaxDirectMemorySize=128m
#!/bin/bash
current_path=`pwd`
case "`uname`" in
Linux)
bin_abs_path=$(readlink -f $(dirname $0))
;;
*)
bin_abs_path=`cd $(dirname $0); pwd`
;;
esac
base=${bin_abs_path}/..
export LANG=en_US.UTF-8
export BASE=$base
if [ -f $base/bin/adapter.pid ] ; then
echo "found adapter.pid , Please run stop.sh first ,then startup.sh" 2>&2
exit 1
fi
if [ ! -d $base/logs ] ; then
mkdir -p $base/logs
fi
## set java path
if [ -z "$JAVA" ] ; then
JAVA=$(which java)
fi
ALIBABA_JAVA="/usr/alibaba/java/bin/java"
TAOBAO_JAVA="/opt/taobao/java/bin/java"
if [ -z "$JAVA" ]; then
if [ -f $ALIBABA_JAVA ] ; then
JAVA=$ALIBABA_JAVA
elif [ -f $TAOBAO_JAVA ] ; then
JAVA=$TAOBAO_JAVA
else
echo "Cannot find a Java JDK. Please set either set JAVA or put java (>=1.5) in your PATH." 2>&2
exit 1
fi
fi
case "$#"
in
0 )
;;
2 )
if [ "$1" = "debug" ]; then
DEBUG_PORT=$2
DEBUG_SUSPEND="n"
JAVA_DEBUG_OPT="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=$DEBUG_PORT,server=y,suspend=$DEBUG_SUSPEND"
fi
;;
* )
echo "THE PARAMETERS MUST BE TWO OR LESS.PLEASE CHECK AGAIN."
exit;;
esac
str=`file -L $JAVA | grep 64-bit`
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms2048m -Xmx3072m -Xmn1024m -XX:SurvivorRatio=2 -Xss256k -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError"
else
JAVA_OPTS="-server -Xms1024m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxPermSize=128m "
fi
## 主要是修改了这个地方,修改了启动参数
JAVA_OPTS="-server -Xms104m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxDirectMemorySize=128m -XX:MaxPermSize=128m "
echo $JAVA_OPTS
JAVA_OPTS=" $JAVA_OPTS -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dfile.encoding=UTF-8"
ADAPTER_OPTS="-DappName=canal-adapter"
for i in $base/lib/*;
do CLASSPATH=$i:"$CLASSPATH";
done
CLASSPATH="$base/conf:$CLASSPATH";
echo "cd to $bin_abs_path for workaround relative path"
cd $bin_abs_path
echo CLASSPATH :$CLASSPATH
exec $JAVA $JAVA_OPTS $JAVA_DEBUG_OPT $ADAPTER_OPTS -classpath .:$CLASSPATH com.alibaba.otter.canal.adapter.launcher.CanalAdapterApplication
可以看到插入几万条数据后(确实也同步到ES中了),adapter的内存反而还下降了?不是很懂,只能说回想起了深度学习调参的日子
 文章来源地址https://www.toymoban.com/news/detail-669075.html
文章来源地址https://www.toymoban.com/news/detail-669075.html
到了这里,关于实时同步ES技术选型:Mysql+Canal+Adapter+ES+Kibana的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!