前言
作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv8,YOLOv7、YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他目标检测算法同样可以适用进行改进。希望能够对大家有帮助。
一、解决问题
这篇文章提出的方法主要用于遥感图像检测中,通过提出上下文聚合网络(CATNet)来改善特征提取过程,对于遥感图像中的小目标会有一定的效果,尝试引入YOLO系列算法中,提高检测效果。
二、基本原理
原文链接: 2111.11057.pdf (arxiv.org)
代码链接:CATNet/scp.py at main · yeliudev/CATNet · GitHub

摘要:远程感知图像中的实例分割任务旨在执行实例级别的像素级别标记,对于各种民用应用非常重要。尽管之前已经取得了成功,但是大多数现有的针对自然图像设计的实例分割方法在直接应用于俯视远程感知图像时遇到了严重的性能下降。经过仔细分析,我们发现这些挑战主要来自于缺乏具有区分度的目标特征,原因是受到严重的尺度变化、低对比度和聚集分布的影响。为了解决这些问题,提出了一种新的上下文聚合网络(CATNet)来改善特征提取过程。所提出的模型利用三个轻量级的即插即用模块,分别是密集特征金字塔网络(DenseFPN)、空间上下文金字塔(SCP)和分层感兴趣区提取器(HRoIE),在特征、空间和实例域中聚合全局视觉上下文。DenseFPN是一个多尺度特征传播模块,通过采用层内残差连接、层间稠密连接和特征重新加权策略,建立了更加灵活的信息流。利用注意机制,SCP通过将全局空间上下文聚合到本地区域中进一步增强特征。对于每个实例,HRoIE自适应地生成用于不同下游任务的RoI特征。我们在具有挑战性的iSAID、DIOR、NWPU VHR-10和HRSID数据集上对所提出的方案进行了广泛评估。评估结果表明,在类似的计算成本下,所提出的方法优于现有的最先进技术。

将上下文的概念扩展和明确分离为特征、空间和实例域,从而在远程感知图像分割中实现了卓越的性能。据我们所知,这是第一篇考虑超越空间依赖性的全局视觉上下文的研究。所提出的CATNet可以利用DenseFPN、SCP和HRoIE从不同域中学习和聚合全局视觉上下文,用于远程感知图像的目标检测和实例分割。所提出的方案已在各种数据集上进行了测试,包括iSAID、DIOR、NWPU VHR-10和HRSID,并且在类似的计算成本下获得了新的最先进性能。

在iSAID、DIOR、NWPU VHR-10和HRSID数据集上对所提出的方法进行了广泛评估。首先在iSAID数据集上进行实例分割任务的模块评估,然后在DIOR和NWPU VHR-10数据集上进行目标检测任务,以展示在光学遥感图像中的有效性。我们还使用HRSID数据集验证了在SAR图像中的泛化能力。
三、添加方法
原论文提出的CATnet中的ContextAggregation模块代码如下所示:
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule, caffe2_xavier_init, constant_init
from mmcv.runner import BaseModule, auto_fp16
from mmdet.models import NECKS
class ContextAggregation(nn.Module):
"""
Context Aggregation Block.
Args:
in_channels (int): Number of input channels.
reduction (int, optional): Channel reduction ratio. Default: 1.
conv_cfg (dict or None, optional): Config dict for the convolution
layer. Default: None.
"""
def __init__(self, in_channels, reduction=1, conv_cfg=None):
super(ContextAggregation, self).__init__()
self.in_channels = in_channels
self.reduction = reduction
self.inter_channels = max(in_channels // reduction, 1)
conv_params = dict(kernel_size=1, conv_cfg=conv_cfg, act_cfg=None)
self.a = ConvModule(in_channels, 1, **conv_params)
self.k = ConvModule(in_channels, 1, **conv_params)
self.v = ConvModule(in_channels, self.inter_channels, **conv_params)
self.m = ConvModule(self.inter_channels, in_channels, **conv_params)
self.init_weights()
def init_weights(self):
for m in (self.a, self.k, self.v):
caffe2_xavier_init(m.conv)
constant_init(self.m.conv, 0)
def forward(self, x):
n, c = x.size(0), self.inter_channels
# a: [N, 1, H, W]
a = self.a(x).sigmoid()
# k: [N, 1, HW, 1]
k = self.k(x).view(n, 1, -1, 1).softmax(2)
# v: [N, 1, C, HW]
v = self.v(x).view(n, 1, c, -1)
# y: [N, C, 1, 1]
y = torch.matmul(v, k).view(n, c, 1, 1)
y = self.m(y) * a
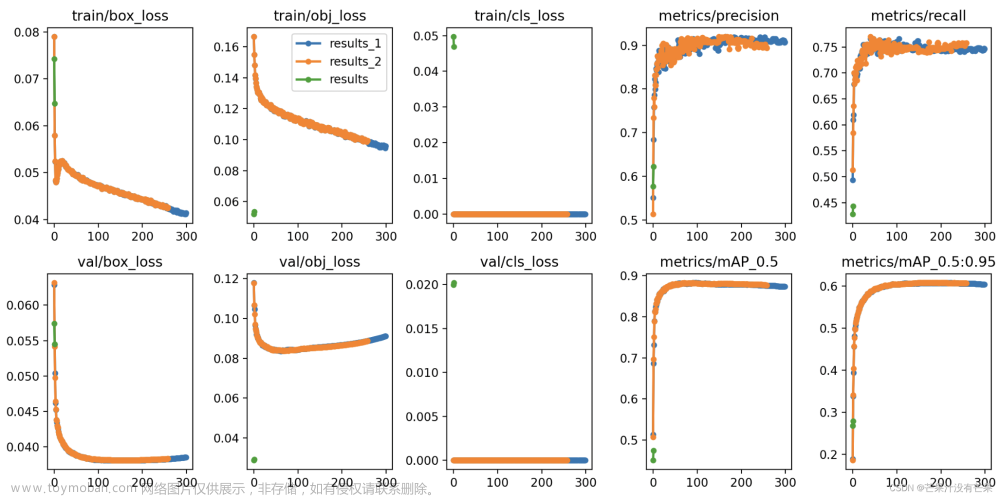
return x + y改进后运行的网络层数以及参数如下所示,博主是在NWPU VHR-10遥感数据集进行训练测试,实验是有提升效果的。具体获取办法可私信获取改进后的YOLO项目百度链接。

四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦文章来源:https://www.toymoban.com/news/detail-669609.html
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。文章来源地址https://www.toymoban.com/news/detail-669609.html
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
到了这里,关于YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进【NO.69】针对遥感图像目标检测中的小目标进行改进CATnet(ContextAggregation模块)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!