一、Flink 窗口 理解
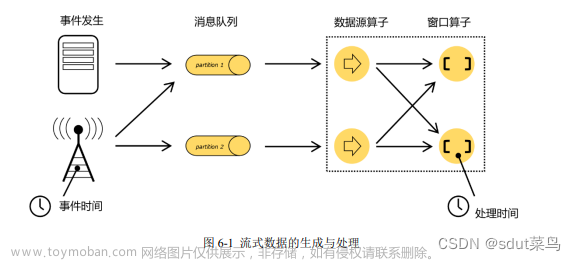
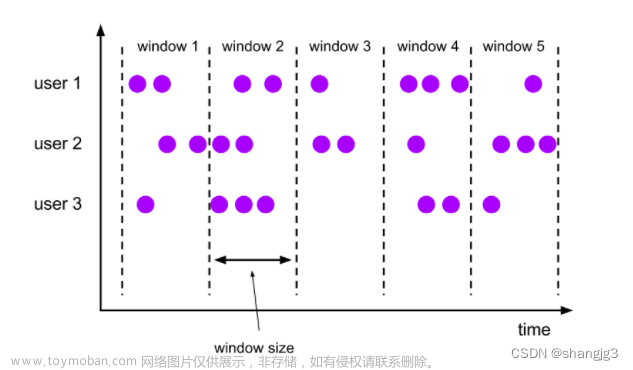
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而Window窗口是一种切割无限数据为有限块进行处理的手段。
在Flink中, 窗口(window)是处理无界流的核心. 窗口把流切割成有限大小的多个"存储桶"(bucket), 我们在这些桶上进行计算.
时间窗口
时间窗口包含一个开始时间戳(包括)和结束时间戳(不包括), 这两个时间戳一起限制了窗口的尺寸。在代码中, Flink使用TimeWindow这个类来表示基于时间的窗口. 这个类提供了key查询开始时间戳和结束时间戳的方法, 还提供了针对给定的窗口获取它允许的最大时间戳的方法(maxTimestamp()),时间窗口又分3种:滚动窗口、滑动窗口、会话窗口。
二、数据准备
准备一个WaterSensor类方便演示
package com.lyh.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class WaterSensor {
private String id;
private Long ts;
private Integer vc;
}
三、时间滚动窗口
滚动窗口有固定的大小, 窗口与窗口之间不会重叠也没有缝隙.比如,如果指定一个长度为5分钟的滚动窗口, 当前窗口开始计算, 每5分钟启动一个新的窗口。滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。
滚动窗口有固定的大小, 窗口与窗口之间不会重叠也没有缝隙.比如,如果指定一个长度为5分钟的滚动窗口, 当前窗口开始计算, 每5分钟启动一个新的窗口.
滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口
1.时间间隔可以通过: Time.milliseconds(x), Time.seconds(x), Time.minutes(x),等等来指定,2.我们传递给window函数的对象叫窗口分配器.
时间滚动窗口代码
package com.lyh.flink07;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Window_s {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String,String, TimeWindow>() {
@Override
public void process(String key,
Context ctx,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
List<WaterSensor> list = toList(elements);
long starttime = ctx.window().getStart();
long endtime = ctx.window().getEnd();
out.collect("窗口:" + starttime + " " + endtime + " " + "key:" + key + " " + "list:" + list);
}
}).print();
env.execute();
}
private static <T>List<T> toList(Iterable<T> it) {
List<T> list = new ArrayList<>();
for (T t : it) {
list.add(t);
}
return list;
}
}
运行结果
在hadoop100 服务器
输入nc -lk 999 启动socket
消费结果:
四、时间滑动窗口
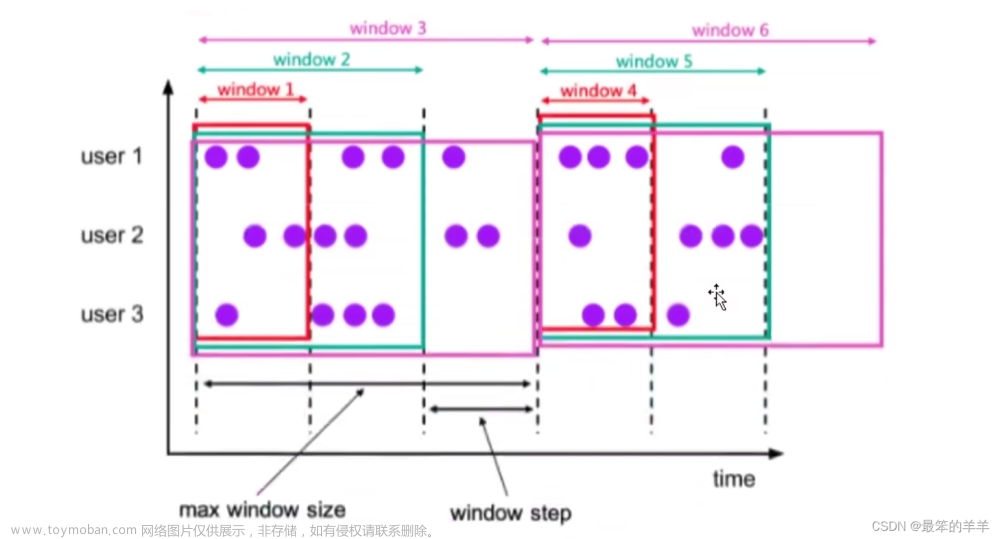
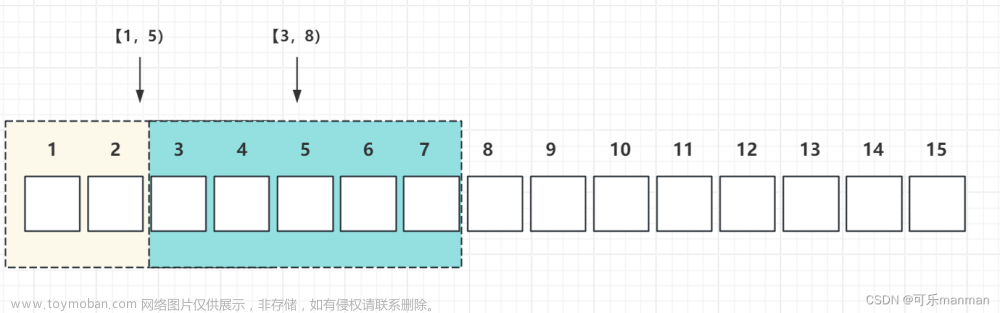
与滚动窗口一样, 滑动窗口也是有固定的长度. 另外一个参数我们叫滑动步长, 用来控制滑动窗口启动的频率.
所以, 如果滑动步长小于窗口长度, 滑动窗口会重叠. 这种情况下, 一个元素可能会被分配到多个窗口中
例如, 滑动窗口长度10分钟, 滑动步长5分钟, 则, 每5分钟会得到一个包含最近10分钟的数据。
时间滑动窗口代码
package com.lyh.flink07;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Window_s {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
// .window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2)))
.process(new ProcessWindowFunction<WaterSensor, String,String, TimeWindow>() {
@Override
public void process(String key,
Context ctx,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
List<WaterSensor> list = toList(elements);
long starttime = ctx.window().getStart();
long endtime = ctx.window().getEnd();
out.collect("窗口:" + starttime + " " + endtime + " " + "key:" + key + " " + "list:" + list);
}
}).print();
env.execute();
}
private static <T>List<T> toList(Iterable<T> it) {
List<T> list = new ArrayList<>();
for (T t : it) {
list.add(t);
}
return list;
}
}
执行结果
在hadoop100 服务器
输入nc -lk 999 启动socket
消费结果
五、时间会话窗口
会话窗口分配器会根据活动的元素进行分组. 会话窗口不会有重叠, 与滚动窗口和滑动窗口相比, 会话窗口也没有固定的开启和关闭时间.
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔)
我们可以配置静态的gap, 也可以通过一个gap extractor 函数来定义gap的长度. 当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口。
时间会话窗口代码
package com.lyh.flink07;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Window_s {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
// .window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
// .window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2)))
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(3)))
.process(new ProcessWindowFunction<WaterSensor, String,String, TimeWindow>() {
@Override
public void process(String key,
Context ctx,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
List<WaterSensor> list = toList(elements);
long starttime = ctx.window().getStart();
long endtime = ctx.window().getEnd();
out.collect("窗口:" + starttime + " " + endtime + " " + "key:" + key + " " + "list:" + list);
}
}).print();
env.execute();
}
private static <T>List<T> toList(Iterable<T> it) {
List<T> list = new ArrayList<>();
for (T t : it) {
list.add(t);
}
return list;
}
}
运行结果
在hadoop100 服务器
输入nc -lk 999 启动socket
消费结果
因为会话窗口没有固定的开启和关闭时间, 所以会话窗口的创建和关闭与滚动,滑动窗口不同. 在Flink内部, 每到达一个新的元素都会创建一个新的会话窗口, 如果这些窗口彼此相距比较定义的gap小, 则会对他们进行合并. 为了能够合并, 会话窗口算子需要合并触发器和合并窗口函数: ReduceFunction, AggregateFunction, or ProcessWindowFunction 。
六、基于元素个数的滚动窗口
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
实例代码
.countWindow(3)
说明:哪个窗口先达到3个元素, 哪个窗口就关闭. 不影响其他的窗口.
基于元素个数的滚动窗口代码
package com.lyh.flink07;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Window_s_n {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.countWindow(2)
.process(new ProcessWindowFunction<WaterSensor, String, String, GlobalWindow>() {
@Override
public void process(String key,
Context ctx,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
List<WaterSensor> list = toList(elements);
out.collect("窗口:" + "key:" + key + " " + "list:" + list);
}
}).print();
env.execute();
}
private static <T>List<T> toList(Iterable<T> it) {
List<T> list = new ArrayList<>();
for (T t : it) {
list.add(t);
}
return list;
}
}
运行结果

七、基于元素个数的滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围最多是3个元素。
实例代码
.countWindow(3, 2)文章来源:https://www.toymoban.com/news/detail-669647.html
package com.lyh.flink07;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Window_s_n {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
// .countWindow(2)
.countWindow(3,2)
.process(new ProcessWindowFunction<WaterSensor, String, String, GlobalWindow>() {
@Override
public void process(String key,
Context ctx,
Iterable<WaterSensor> elements,
Collector<String> out) throws Exception {
List<WaterSensor> list = toList(elements);
out.collect("窗口:" + "key:" + key + " " + "list:" + list);
}
}).print();
env.execute();
}
private static <T>List<T> toList(Iterable<T> it) {
List<T> list = new ArrayList<>();
for (T t : it) {
list.add(t);
}
return list;
}
}
运行结果
 文章来源地址https://www.toymoban.com/news/detail-669647.html
文章来源地址https://www.toymoban.com/news/detail-669647.html
到了这里,关于大数据-玩转数据-Flink时间滚动动窗口的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!