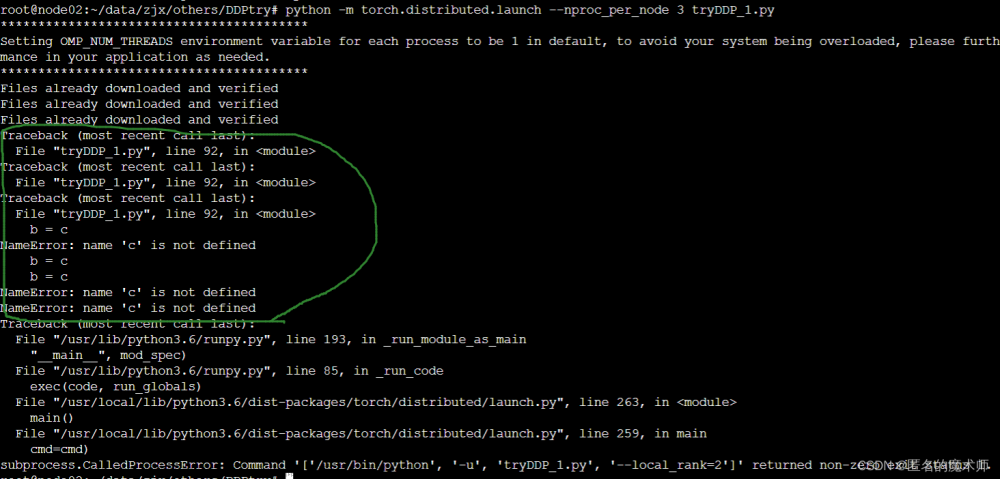
文章来源:https://www.toymoban.com/news/detail-669664.html
文章来源:https://www.toymoban.com/news/detail-669664.html
一、介绍
欢迎来到我们关于 PyTorch Lightning 系列的第二篇文章!在上一篇文章中,我们向您介绍了 PyTorch Lightning,并探讨了它在简化深度学习模型开发方面的主要功能和优势。我们了解了 PyTorch Lightning 如何为组织和构建 PyTorch 代码提供高级抽象,使研究人员和从业者能够更多地关注模型设计和实验,而不是样板代码。文章来源地址https://www.toymoban.com/news/detail-669664.html
到了这里,关于PyTorch Lightning:通过分布式训练扩展深度学习工作流的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!