EasyOCR是一个开源的Python库,专注于提供易用而准确的文字识别功能。它基于深度学习技术,使用了一种端到端的方法,能够在多种语言和字体下进行稳定的识别。
初
希望能写一些简单的教程和案例分享给需要的人
环境
Python 3.10.12
系统: ubuntu 22.04
内容
接下来我分享如何使用Python的easyocr库,将图片中的文字提取出来。
步骤一:安装easyocr库
首先,确保您已经安装了Python。接下来,我们需要安装easyocr库,可以通过以下命令在命令行中进行安装:
pip install easyocr
步骤二:导入必要的库
在您的Python脚本中,导入所需的库,其中包括我们即将使用的easyocr库:
import easyocr
步骤三:创建OCR阅读器对象
创建一个OCR阅读器对象,您可以选择要识别的语言。以下示例选择了中文和英文语言:
reader = easyocr.Reader(['ch_sim', 'en'])
步骤四:指定要识别的图片路径
将要进行OCR识别的图片放置在您选择的路径下,并将该路径赋值给变量image_path:
image_path = 'test.png'
确保将test.png替换为您实际的图片路径。
步骤五:执行OCR识别并提取文章内容
使用OCR阅读器对象的readtext方法读取图片中的文本,将识别结果存储在变量results中:
results = reader.readtext(image_path)
步骤六:遍历识别结果并打印文章内容
使用循环遍历results中的每个识别结果,然后打印出每个结果的文本内容:
for (bbox, text, prob) in results:
print(text)
完整代码
# 导入所需库
import easyocr
# 创建一个OCR阅读器对象,选择中文和英文语言
reader = easyocr.Reader(['ch_sim', 'en'])
# 指定要进行OCR识别的图片路径
image_path = 'aaa.png'
# 使用OCR阅读器对象读取图片中的文本
results = reader.readtext(image_path)
# 遍历识别结果并打印文本内容
for (bbox, text, prob) in results:
print(text)
运行结果

python3 a.py

识别出来是这样:识别率还行,不过有些确实不是很正确。
盗理者
玛龄7年
企业员工
355
4954
1458
103万+
原创
屑#名
总排名
访问
1万+
1770
788
241
1071
讧论
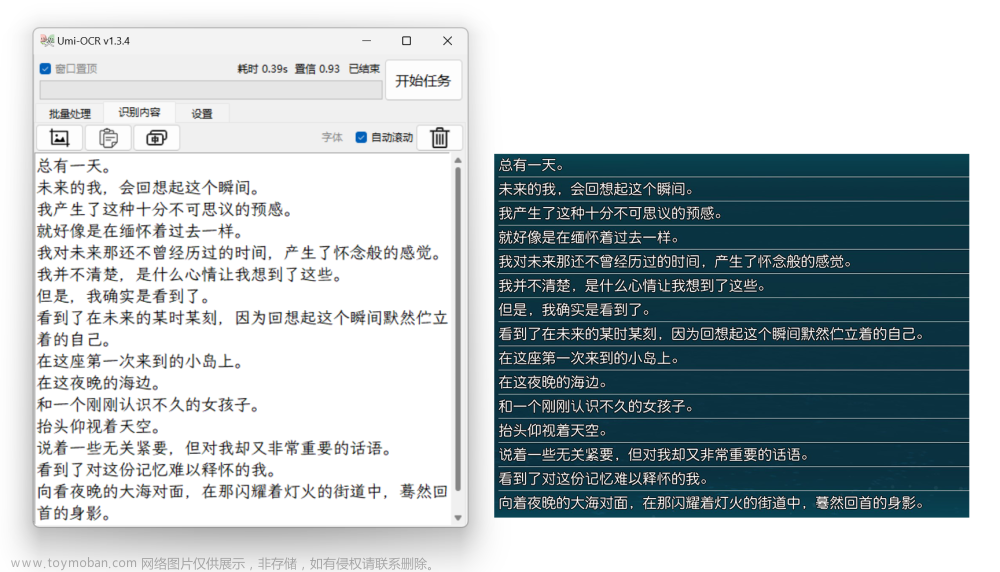
在sublime text 的效果:文章来源:https://www.toymoban.com/news/detail-671084.html
 文章来源地址https://www.toymoban.com/news/detail-671084.html
文章来源地址https://www.toymoban.com/news/detail-671084.html
到了这里,关于Python OCR 使用easyocr库将图片中的文章提取出来的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!