代码
代码按照下列顺序依次:
1、
function result(true_value,predict_value,type)
[m,n]=size(true_value);
true_value=reshape(true_value,[1,m*n]);
predict_value=reshape(predict_value,[1,m*n]);
disp(type)
rmse=sqrt(mean((true_value-predict_value).^2));
disp(['根均方差(RMSE):',num2str(rmse)])
mae=mean(abs(true_value-predict_value));
disp(['平均绝对误差(MAE):',num2str(mae)])
mape=mean(abs((true_value-predict_value)./true_value));
disp(['平均相对百分误差(MAPE):',num2str(mape*100),'%'])
R2 = 1 - norm(true_value-predict_value)^2/norm(true_value - mean(true_value))^2;
disp(['决定系数(R2):',num2str(R2)])
fprintf('\n')
2、
function r2=R2(T_test,T_sim)
N = length(T_test);
r2 = (N*sum(T_sim.*T_test)-sum(T_sim)*sum(T_test))^2/((N*sum((T_sim).^2)-(sum(T_sim))^2)*(N*sum((T_test).^2)-(sum(T_test))^2));
3、
function [y,trace,result]=qpsoforlstm(p_train,t_train,p_test,t_test)
PopNum=10;% 种群数
Maxstep=10;%最大寻优迭代数
dim=4;% 寻优维度
xmin=[1 1 10 0.001];%分别对两个隐含层的节点 训练次数与学习率寻优
xmax=[200 200 100 0.01];%比如第一个隐含层节点的范围是1-200
for i=1:PopNum%随机初始化速度,随机初始化位置
for j=1:dim
if j==dim% % 隐含层节点与训练次数是整数 学习率是浮点型
pop(i,j)=(xmax(j)-xmin(j))*rand+xmin(j);
else
pop(i,j)=round((xmax(j)-xmin(j))*rand+xmin(j)); %
end
end
end
% calculate the fitness_value of Pop
pbest = pop;
gbest = zeros(1,dim);
data1 = zeros(Maxstep,PopNum,dim);
data2 = zeros(Maxstep,PopNum);
for i = 1:PopNum
fit(i) = fitness(pop(i,:),p_train,t_train,p_test,t_test);
f_pbest(i) = fit(i);
end
g = min(find(f_pbest == min(f_pbest(1:PopNum))));
gbest = pbest(g,:);
f_gbest = f_pbest(g);
%-------- in the loop -------------
for step = 1:Maxstep
mbest =sum(pbest(:))/PopNum;
% linear weigh factor
b = 1-step/Maxstep*0.5;
data1(step,:,:) = pop;
data2(step,:) = fit;
for i = 1:PopNum
a = rand(1,dim);
u = rand(1,dim);
p = a.*pbest(i,:)+(1-a).*gbest;
pop(i,:) = p + b*abs(mbest-pop(i,:)).*...
log(1./u).*(1-2*(u >= 0.5));
% boundary detection
for j=1:dim
if j ==dim
if pop(i,j)>xmax(j) | pop(i,j)<xmin(j)
pop(i,j)=(xmax(j)-xmin(j))*rand+xmin(j); %
end
else
pop(i,j)=round(pop(i,j));
if pop(i,j)>xmax(j) | pop(i,j)<xmin(j)
pop(i,j)=round((xmax(j)-xmin(j))*rand+xmin(j)); %
end
end
end
fit(i) = fitness(pop(i,:),p_train,t_train,p_test,t_test);
if fit(i) < f_pbest(i)
pbest(i,:) = pop(i,:);
f_pbest(i) = fit(i);
end
if f_pbest(i) < f_gbest
gbest = pbest(i,:);
f_gbest = f_pbest(i);
end
end
trace(step)=f_gbest;
step,f_gbest,gbest
result(step,:)=gbest;
end
y=gbest;
end
4、
function [xm ,trace,result]=psoforlstm(p_train,t_train,p_test,t_test)
N=5;
M=10;
c1=1.5;
c2=1.5;
w=0.8;
D=4;
% 定义寻优边界
xmin=[1 1 10 0.001];%分别两个对隐含层节点 训练次数与学习率寻优
xmax=[200 200 100 0.01];%比如第一个隐含层节点的范围是1-200
for i=1:N%随机初始化速度,随机初始化位置
for j=1:D
if j==D% % 隐含层节点与训练次数是整数 学习率是浮点型
x(i,j)=(xmax(j)-xmin(j))*rand+xmin(j);
else
x(i,j)=round((xmax(j)-xmin(j))*rand+xmin(j)); %
end
end
v(i,:)=rand(1,D);
end
%------先计算各个粒子的适应度,并初始化Pi和Pg----------------------
for i=1:N
p(i)=fitness(x(i,:),p_train,t_train,p_test,t_test);
y(i,:)=x(i,:);
end
[fg,index]=min(p);
pg = x(index,:); %Pg为全局最优
%------进入主要循环,按照公式依次迭代------------
for t=1:M
for i=1:N
v(i,:)=w*v(i,:)+c1*rand*(y(i,:)-x(i,:))+c2*rand*(pg-x(i,:));
x(i,:)=x(i,:)+v(i,:);
for j=1:D
if j ~=D
x(i,j)=round(x(i,j));
end
if x(i,j)>xmax(j) | x(i,j)<xmin(j)
if j==D
x(i,j)=(xmax(j)-xmin(j))*rand+xmin(j); %
else
x(i,j)=round((xmax(j)-xmin(j))*rand+xmin(j)); %
end
end
end
temp=fitness(x(i,:),p_train,t_train,p_test,t_test);
if temp<p(i)
p(i)=temp;
y(i,:)=x(i,:);
end
if p(i)<fg
pg=y(i,:);
fg=p(i);
end
end
trace(t)=fg;
result(t,:)=pg;
t,fg,pg
end
xm = pg;
5、
function huatu(fitness,process,type)
figure
plot(fitness)
grid on
title([type,'的适应度曲线'])
xlabel('迭代次数/次')
ylabel('适应度值/MSE')
figure
subplot(2,2,1)
plot(process(:,1))
grid on
xlabel('迭代次数/次')
ylabel('L1/个')
subplot(2,2,2)
plot(process(:,2))
grid on
xlabel('迭代次数/次')
ylabel('L2/个')
subplot(2,2,3)
plot(process(:,3))
grid on
xlabel('迭代次数/次')
ylabel('K/次')
subplot(2,2,4)
plot(process(:,4))
grid on
xlabel('迭代次数/次')
ylabel('lr')
suptitle([type,'的超参数随迭代次数的变化'])
6、
function y=fitness(x,p,t,pt,tt)
rng(0)
numFeatures = size(p,1);%输入节点数
numResponses = size(t,1);%输出节点数
miniBatchSize = 16; %batchsize 与main....m中保持一致
numHiddenUnits1 = x(1);
numHiddenUnits2 = x(2);
maxEpochs=x(3);
learning_rate=x(4);
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits1)
lstmLayer(numHiddenUnits2)
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',learning_rate, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Verbose',false);
net = trainNetwork(p,t,layers,options);
YPred = predict(net,pt,'MiniBatchSize',1);YPred=double(YPred);
[m,n]=size(YPred);
YPred=reshape(YPred,[1,n*m]);
tt=reshape(tt,[1,n*m]);
y =mse(YPred-tt);
% 以mse为适应度函数,优化算法目的就是找到一组超参数 使网络的mse最低
rng((100*sum(clock)))
7、
clc;clear;close
%%
lstm=load('result/lstm.mat');
result(lstm.true_value,lstm.predict_value,'LSTM');
psolstm=load('result/pso_lstm.mat');
result(psolstm.true_value,psolstm.predict_value,'PSO-LSTM');
qpsolstm=load('result/qpso_lstm.mat');
result(qpsolstm.true_value,qpsolstm.predict_value,'QPSO-LSTM');
figure
plot(lstm.true_value(end,:),'-r')
hold on;grid on
plot(lstm.predict_value(end,:),'-b')
plot(psolstm.predict_value(end,:),'-k')
plot(qpsolstm.predict_value(end,:),'-k')
legend('真实值','LSTM网络模型','PSO-LSTM网络模型','QPSO-LSTM网络模型')
title('各算法结果')
xlabel('测试集样本')
ylabel('负荷')
8、
%% QPSO优化LSTM时间序列预测
clc;clear;close all;format compact
%%
load u789
n=10;m=2;
[x,y]=data_process(data,n,m);%前n个时刻 预测后m个时刻
method=@mapminmax;%归一化
% method=@mapstd;%标准化
[xs,mappingx]=method(x');x=xs';
[ys,mappingy]=method(y');y=ys';
%划分数据
n=size(x,1);
m=round(n*0.7);%前70%训练 后30%测试
XTrain=x(1:m,:)';
XTest=x(m+1:end,:)';
YTrain=y(1:m,:)';
YTest=y(m+1:end,:)';
%% 采用QPSO优化
optimization=1;%是否重新优化
if optimization==1
[x ,fit_gen,process]=qpsoforlstm(XTrain,YTrain,XTest,YTest);%分别对隐含层节点 训练次数与学习率寻优
save result/qpso_para_result x fit_gen process
else
load result/qpso_para_result
end
%% 画适应度曲线与4个参数的变化曲线
huatu(fit_gen,process,'QPSO')
disp('优化的超参数为:')
disp('L1:'),x(1)
disp('L2:'),x(2)
disp('K:'),x(3)
disp('lr:'),x(4)
%% 利用优化得到的参数重新训练
train=1;%是否重新训练
if train==1
rng(0)
numFeatures = size(XTrain,1);%输入节点数
numResponses = size(YTrain,1);%输出节点数
miniBatchSize = 16; %batchsize 与fitness.m中保持一致
numHiddenUnits1 = x(1);
numHiddenUnits2 = x(2);
maxEpochs=x(3);
learning_rate=x(4);
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits1)
lstmLayer(numHiddenUnits2)
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',learning_rate, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Verbose',true,...
'Plots','training-progress');
net = trainNetwork(XTrain,YTrain,layers,options);
save model/qpsolstm net
else
load model/qpsolstm
end
% 预测
YPred = predict(net,XTest,'MiniBatchSize',1);YPred=double(YPred);
% 反归一化
predict_value=method('reverse',YPred,mappingy);
true_value=method('reverse',YTest,mappingy);
save result/qpso_lstm predict_value true_value
%%
load result/qpso_lstm
disp('结果分析')
result(true_value,predict_value,'QPSO-LSTM')
fprintf('\n')
%
figure
plot(true_value(end,:),'p-')
hold on
plot(predict_value(end,:),'-*')
grid on
title('QPSO-LSTM')
legend('真实值','预测值')
xlabel('预测样本点坐标')
ylabel('值')
9、
%% PSO优化LSTM时间序列预测
clc;clear;close all;format compact
%%
load u789
n=10;m=2;
[x,y]=data_process(data,n,m);%前n个时刻 预测后m个时刻
method=@mapminmax;%归一化
% method=@mapstd;%标准化
[xs,mappingx]=method(x');x=xs';
[ys,mappingy]=method(y');y=ys';
%划分数据
n=size(x,1);
m=round(n*0.7);%前70%训练 后30%测试
XTrain=x(1:m,:)';
XTest=x(m+1:end,:)';
YTrain=y(1:m,:)';
YTest=y(m+1:end,:)';
%% 采用PSO优化
optimization=1;%是否重新优化
if optimization==1
[x ,fit_gen,process]=psoforlstm(XTrain,YTrain,XTest,YTest);%分别对隐含层节点 训练次数与学习率寻优
save result/pso_para_result x fit_gen process
else
load result/pso_para_result
end
%% 画适应度曲线与4个参数的变化曲线
huatu(fit_gen,process,'PSO')
disp('优化的超参数为:')
disp('L1:'),x(1)
disp('L2:'),x(2)
disp('K:'),x(3)
disp('lr:'),x(4)
%% 利用优化得到的参数重新训练
train=1;%是否重新训练
if train==1
rng(0)
numFeatures = size(XTrain,1);%输入节点数
numResponses = size(YTrain,1);%输出节点数
miniBatchSize = 16; %batchsize 与fitness.m中保持一致
numHiddenUnits1 = x(1);
numHiddenUnits2 = x(2);
maxEpochs=x(3);
learning_rate=x(4);
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits1)
lstmLayer(numHiddenUnits2)
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',learning_rate, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Verbose',true,...
'Plots','training-progress');
net = trainNetwork(XTrain,YTrain,layers,options);
save model/psolstm net
else
load model/psolstm
end
% 预测
YPred = predict(net,XTest,'MiniBatchSize',1);YPred=double(YPred);
% 反归一化
predict_value=method('reverse',YPred,mappingy);
true_value=method('reverse',YTest,mappingy);
save result/pso_lstm predict_value true_value
%%
load result/pso_lstm
disp('结果分析')
result(true_value,predict_value,'PSO-LSTM')
fprintf('\n')
%
figure
plot(true_value(end,:),'p-')
hold on
plot(predict_value(end,:),'-*')
grid on
title('PSO-LSTM')
legend('真实值','预测值')
xlabel('预测样本点坐标')
ylabel('值')
10、
%% LSTM时间序列预测
clc;clear;close all
%%
load u789
n=10;m=2;
[x,y]=data_process(data,n,m);%前n个时刻 预测后m个时刻
method=@mapminmax;%归一化
% method=@mapstd;%标准化
[xs,mappingx]=method(x');x=xs';
[ys,mappingy]=method(y');y=ys';
%划分数据
n=size(x,1);
m=round(n*0.7);%前70%训练 后30%测试
XTrain=x(1:m,:)';
XTest=x(m+1:end,:)';
YTrain=y(1:m,:)';
YTest=y(m+1:end,:)';
%% 参数设置
train=1;%为1就重新训练,否则加载训练好的模型进行预测
if train==1
rng(0)
numFeatures = size(XTrain,1);%输入节点数
numResponses = size(YTrain,1);%输出节点数
miniBatchSize = 16; %batchsize
numHiddenUnits1 = 20;
numHiddenUnits2 = 20;
maxEpochs=20;
learning_rate=0.005;
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits1)
lstmLayer(numHiddenUnits2)
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',learning_rate, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Verbose',true,...
'Plots','training-progress');
net = trainNetwork(XTrain,YTrain,layers,options);
save model/lstm net
else
load model/lstm
end
YPred = predict(net,XTest,'MiniBatchSize',1);YPred=double(YPred);
% 反归一化
predict_value=method('reverse',YPred,mappingy);
true_value=method('reverse',YTest,mappingy);
save result/lstm predict_value true_value
%%
load result/lstm
disp('结果分析')
result(true_value,predict_value,'LSTM')
%
figure
plot(true_value(end,:),'p-')
hold on
plot(predict_value(end,:),'-*')
grid on
title('LSTM')
legend('真实值','预测值')
xlabel('预测样本点坐标')
ylabel('值')
11、
function [in,out]=data_process(data,num,mem)
% 采用1到num作为输入 第num到mem作为输出
n=length(data)-num-mem+1;
for i=1:n
in(i,:)=data(i:i+num-1);
out(i,:)=data(i+num:i+num+mem-1);
end
数据
 文章来源:https://www.toymoban.com/news/detail-671643.html
文章来源:https://www.toymoban.com/news/detail-671643.html
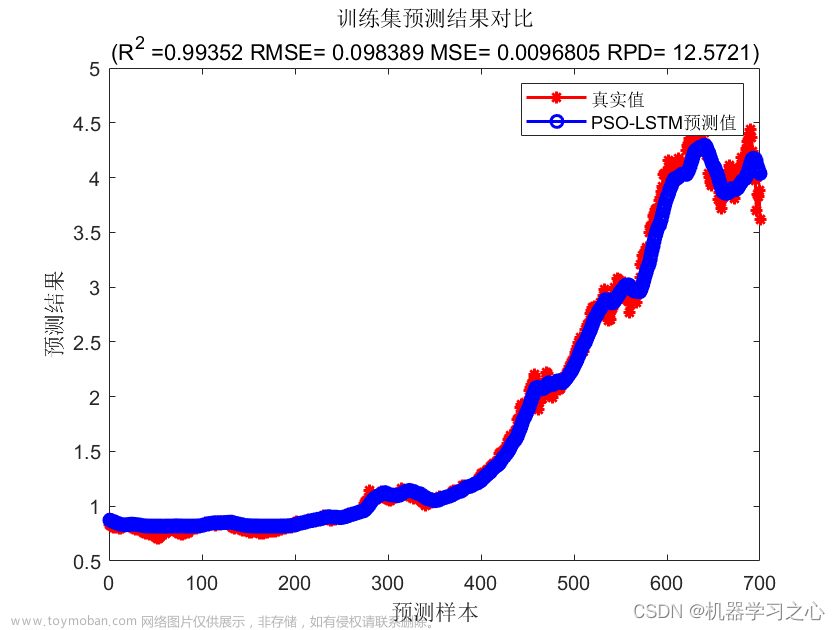
结果


如有需要代码和数据的同学请在评论区发邮箱,一般一天之内会回复,请点赞+关注谢谢!!文章来源地址https://www.toymoban.com/news/detail-671643.html
到了这里,关于机器学习之MATLAB代码--MATLAB量子粒子群优化LSTM超参数负荷预测(十三)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





(Matlab代码实现)](https://imgs.yssmx.com/Uploads/2024/02/628119-1.png)