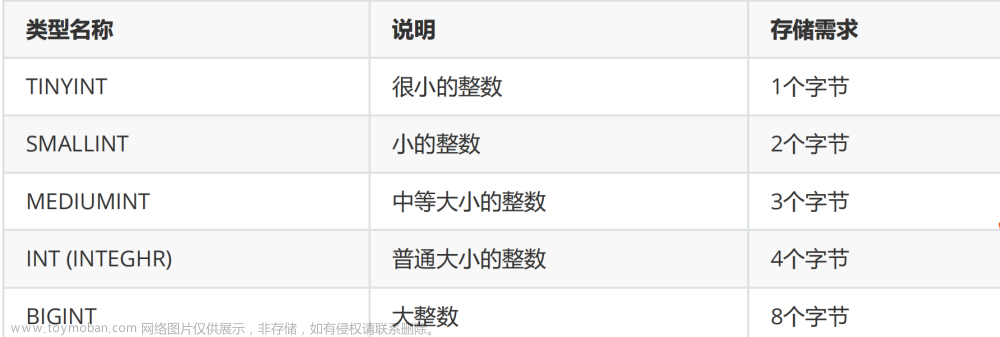
Mysql的知识点目录
- 重点:架构,引擎,索引,锁机制,事务机制,日志机制,集群,调优
3、Mysql索引
- 索引概念
- 覆盖索引: 条件列和结果列都在索引中
- 索引下推: 查询会先过滤条件列,然后回表查数据
- 最左前缀匹配: 查询条件会从最左开始匹配索引列
- 回表:经过索引查询后,不满足还需要通过ID查询所有数据
- 索引失效原因
- or,!=,not in,like等
- 创建索引原则
- 最左前缀原则
- 读多写少创建索引,写多的不适宜
- 避免破坏索引的查询
- 优先在原有基础上创建索引,避免新建索引
- 区分度低列,外键不建索引
- 删除不再使用进货很少用的索引
4、mysql锁机制
- 锁机制 : 乐观锁(MVCC机制),悲观锁
- 锁粒度 : 全局锁,表锁,行锁,叶索,间隙锁
- 兼容性:共享锁(S锁),排他锁(X锁)
- 锁的模式:记录锁(行锁),间隙锁,意向锁(分为读,写,插入意向锁),next-key锁,自增所
- 死锁的解决
- 互斥条件,请求和保持条件,环路等待条件,不剥夺条件
- 解决思路:切断环路
- 死锁与索引密不可分,解决索引问题,需要合理优化你的索引
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率
Mysql的主从复制,读写分离
-
mysql主从同步延迟
- 原因:主库在高并发写操作时,由于某些SQL执行时间较长,或者SQL锁表导致主库的SQL积压,不能马上同步到从库导致
- 场景:高并发场景时,修改数据库字段,或者发生长事务时,会导致主从延迟
- 解决办法:
- 从库读操作:sync_binlog=0 , 提交SQL执行效率,或者使用更好的设备
- 硬件上:(1)使用更好的设备做从库,(2)增加从库的机器数量,(3)把某一台从库当做备用,不处理查询操作
- 判断主从延迟:通过show slave status,通过Seconds_Behind_Master参数判断
-
主从复制延迟问题
-
mysql读写分离文章来源:https://www.toymoban.com/news/detail-672014.html
- 应用层控制DML语句在主库操作–同步到从库
- 应用层控制SQL语句在从库操作
- 应用层在操作读写事件是可以要求强制读主库,保证一致性
-
mysql主从延迟文章来源地址https://www.toymoban.com/news/detail-672014.html
- 主要根据业务需求,
- 要求强一致性:读写全部在主库
- 弱一致性:一般读在从库,事务读写都在主库
- 最终一致性:写在主库,从在读库
Mysql分库分表
- 分库分表中间件方案
- 当当-shardingjdbc,阿里-mycat,阿里-tddl,阿里-cobar,58同城-Oceanus,阿里-OneProxy,谷歌-vitess
- 分库分表的问题
- 事务问题
- 方式一:使用分布式事务,简单有效,但是性能代价高
- 方式二:将跨库分布式事务拆分成多个单库的小失误,通过程序来控制小事务,性能上优势,但是破坏了耦合性
- 跨结点join问题
- 方式:统一单表操作,通过程序控制
- 跨结点count,orderby,groupby
- 方式:和join类似,在每个节点执行然后再做合并
- id问题
- Redis自增ID
- 雪花算法生成ID
- 数据库维护一个sequence
- 跨分片排序分页问题
- 尽量避免出现跨库的查询分页,如果无法避免,采用内存分页方式
- 数据迁移,容量规划,扩容问题
- 提前规划
- 事务问题
主从延迟问题
- 主从同步步骤:
- 主库发生更新,写入到bin_log
- 从库发起连接到主库
- 主库创建一个binlog dump thread,把binlog的内容发送到从库
- 通过IO线程,读取binlog内容并写入到relay log
- 从库还会创建一个SQL线程,从relay log里面读取内容并执行
- 原因:
- 从库的机器性能差
- 从库访问压力大
- 大事务的执行
- 主库的DDL(alter、drop、create)
- 锁冲突
- 从库的复制能力
- 解决办法:
- 主服务负责更新, 安全性要高,所以设置参数,
- 例如:sync_binlog=1
- 例如:innodb_flush_log_at_trx_commit=1
- 更好的设备作为从库,或者设置更多的从库
- 某台从库不提供查询,专门提供bin_log同步到从库
- 降低多线程大事务并发的概率,优化业务逻辑
- 优化SQL,避免慢SQL,减少批量操作,建议写脚本以update-sleep这样的形式完成。
- 尽量采用短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。
- 实时性要求的业务读强制走主库,从库只做灾备,备份。
- 主服务负责更新, 安全性要高,所以设置参数,
关于BufferPool缓冲池
- mysql数据存储在磁盘,会根据sql的需要通过索引等方式从磁盘中刷到缓冲池
- mysql的sql操作会现在磁盘中操作,事务完成后通过Bin_log刷盘到磁盘。
数据表设计
数据表类型
- 第一类:流水表,日志表,
- 第二类:状态型,记录核心数据
- 第三类:配置表,数据量少,不需要优化
面试:谈谈Mysql调优
1、调优过程
- 1、定位问题:
- 2、分析问题
- 3、解决问题
- 4、验证结果
第一步:定位问题
- 通过服务监控,找到服务卡顿时或服务超时的时间,分析接口
- 通过接口定位代码,进一步定位到执行的SQL,查看执行时长,确认现场
第二步:分析问题
- 通过数据库监控,查看发生问题时,DB集群的数据的CPU,内存,IO磁盘,网络,线程数等参数
- 通过分析现场参数,结合SQL,判断问题所在,例如以下
- CPU过高,检查SQL中是否有运算,是否吞吐量过高等
- 内存过高,SQL是否有用到索引,是否频繁回表
- IO磁盘过高,是否有大表join等问题
- 网络延迟高,是否云服务网络问题
- 线程问题,是否长事务导致锁问题
第三步:解决问题
- 系统负载过高,进行DB扩容,使用分库分表,读写分离等手段,应用层增加缓存等
- 由于SQL原因,进行SQL优化,加索引,使用覆盖索引,删除冗余索引等,一般通过explain分析
- 优化长事务,缩短事务流程
- 优化应用程序,例如加入分布式缓存,以及DAO缓存等
第四步:验证结果
- 设定期望,例如减少请求响应时间,降低系统负载等
- 先在压测环境更新,然后通过压测验证
- 压测没有问题,再部署到生产
Mysql的调优
Mysql的底层知识点
日志种类以及作用
- general_log 一般日志
- error_log 错误日志
- slow_query_log 慢查询日志
- relay_log 中继日志–数据同步,故障恢复起作用
- relay log日志文件具有与bin log日志文件相同的格式
- relay log起到一个中转的作用,slave先从主库master读取二进制日志数据,写入从库本地,后续再异步由SQL线程读取解析relay log为对应的SQL命令执行relay log起到一个中转的作用,slave先从主库master读取二进制日志数据,写入从库本地,后续再异步由SQL线程读取解析relay log为对应的SQL命令执行
- bin_log 归档日志–数据持久性中起作用
- 记录数据库所有的DDL和DML记录,保证数据库数据完整性
- undo_log 回滚日志–事务隔离性和原子性中起作用
- undo log属于逻辑日志,如其名主要起到回滚的作用,它是保证事务原子性的关键。记录的是数据修改前的状态
- 在数据修改的流程中,同时会记录一条与当前操作相反的逻辑日志到undo log中。
- 如果事务执行时,提交rollback则会执行undo_log保证事务回滚
- redo_log 重做日志–数据持久性中起作用
- redo log属于MySQL存储引擎InnoDB的事务日志。
- 作用类似于备份,当出现宕机后恢复时,会使用redo_log快速恢复数据
mysql底层知识点
MVCC原理:
- 为了实现高并发事务场景下使用无锁化场景,解决数据幻读的问题
- 实现原理:
- 关键:隐藏字段,当前读,快照读,事务快照,redolog等配合完成
- 1、隐藏字段:db_row_id行ID,db_trx_id事务ID,db_roll_ptr回滚指针
- 2、undo_log用作操作先备份数据,如果出现异常后回滚数据
- 3、当前读:在读锁下读取最新数据,快照读:不一定是最新数据,类似于缓存
- 4、事务快照+readView
- 事务快照是表共享空间的建立的事务快照,用于区分事务前后顺序
- readView是事务快照读产生的读视图,如果读操作是在事务之前,则可见,如果在事务之后,则不可见,用于控制可见性
到了这里,关于Mysql数据库技术知识整理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!