消息队列
先说明消息队列是什么:
-
亚马逊:
消息队列是一种异步的服务间通信方式,适用于微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。 -
我的理解:
消息队列是一种进程/线程之间的通信方式,它是异步的、服务间解耦的、削峰填谷的,它是“永远在线”技术的基础。 -
常用的消息队列有:
Kafka、RabbitMQ、RocketMQ、ActiviMQ
Kafka是什么
概要
Apache Kafka 是一个开源流处理软件平台,由 LinkedIn 开发并捐赠给 Apache 软件基金会,用 Scala 和 Java 编写。 该项目旨在提供一个统一、高吞吐量、低延迟的平台来处理实时数据源。
它具有以下几个特性:
- 实时捕获数据
- 可持久存储(但一般会设置过期)
- 实时或者回顾性地处理数据
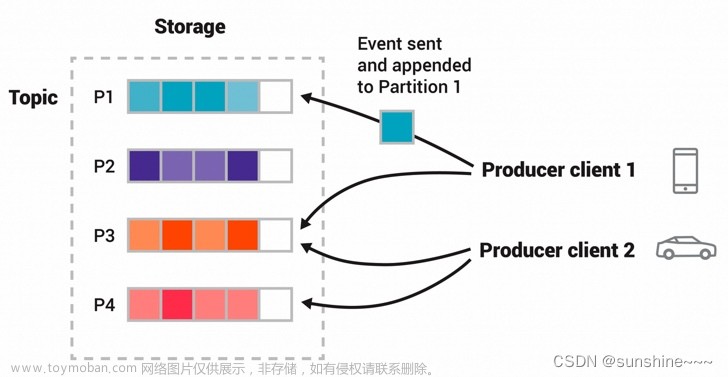
系统架构
图片引用了CSDN@Data跳动的博客:https://blog.csdn.net/weixin_43958974/article/details/122591425,大家有兴趣可以看看他对kafka的理解。
常用概念:
- Broker
- Controller
- Partitions
- Consumer
- Producer
- Topic
- Zookeeper (3.0之后逐步要淘汰)
Broker
Broker是单个 Kafka server,Kafka 集群中的一台服务器就是一个 broker。
Broker从生产者接收消息,为其分配偏移量Offset,并将消息提交到磁盘存储。
偏移量是一个唯一的整数值,Kafka 在生成每条消息时都会递增并添加到该消息中。 偏移量对于在发生故障或中断时保持数据一致性至关重要,因为消费者在发生故障后使用偏移量返回到最后消费的消息。
Broker会向消费者提供已存到磁盘的信息。
Controller
Kafka Broker 通过直接或间接共享信息形成集群。 在 Kafka 集群中,一个Broker充当Controller。 Controller负责管理分区和副本的状态,并执行管理任务,例如重新分配分区和注册处理程序以获取有关更改的通知。
尽管 Controller 服务运行在 Kafka 集群中的每个 Broker 上,但在任何时间点只能有一个 Broker 处于活动状态(当选)。 Broker Controller会在 Kafka 服务器启动时创建并启动。
Producer\Consumer
生产者是将事件发布(写入)到 Kafka 的客户端应用程序,而消费者是订阅(读取和处理)这些事件的客户端应用程序。
在 Kafka 中,生产者和消费者彼此完全解耦且互不可知,这是实现 Kafka 闻名的高可扩展性的关键设计元素。
Topic
事件被组织并持久化存储在Topic中,Topic类似于文件系统中的文件夹,事件是该文件夹中的文件(占磁盘)。
Kafka中的Topic始终是多生产者、多订阅者:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。
主题中的事件可以根据需要随时读取——与传统消息传递系统不同,事件在使用后不会被删除。(保留事件的事件是可配置的)。
Kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是完全可以的。但要考虑磁盘的容量。
Partition
Topic是存在多个Partition上的:这意味着一个Topic分布在不同broker的多个“桶”上。这种数据的分布式放置对于可扩展性非常重要,因为它允许client同时从多个代理读取数据或向多个broker写入数据。
同一分区内是顺序的:当新事件发布到主题时,它实际上会附加到主题的分区之一。 具有相同事件键(例如,客户或车辆 ID)的事件被写入同一分区,并且 Kafka 保证给定主题分区的任何消费者将始终按照与写入的顺序完全相同的顺序读取该分区的事件。
副本
为了使您的数据具有容错性和高可用性,每个主题都可以复制,甚至可以跨地理区域或数据中心进行复制,因此始终有多个代理拥有数据副本,以防出现问题时,您希望 对经纪人进行维护等等。 常见的生产设置是复制因子为 3,即始终存在数据的三个副本。 此复制是在主题分区级别执行的。
Lag
消息堆积的数量
Zookeeper(逐步淘汰)
Zookeeper 存储 Kafka 代理的元数据。 它充当代理和消费者之间的联络人,使分布式进程能够通过称为 znode 的数据寄存器的公共集中式命名空间相互通信。
随着 Apache Kafka 3.0及后续版本 的推出,Zookeeper 正在被删除。 许多用户抱怨必须管理单独的系统以及 Zookeeper 造成的单点故障。 展望未来,Kafka 代理本质上将承担 Zookeeper 的功能,将元数据存储在本地文件中。 控制器接管注册代理并从集群中删除失败的代理,并且在启动时代理仅从控制器读取已更改的内容,而不是完整状态。 这使得 Kafka 能够以更少的 CPU 消耗支持更多的分区。
合理地选择主题和分区
分区数量=消费者的线程数量
如果是自己单机测试的话,最优解是设置为机器CPU的核数
保证消息的顺序传递和容错性
同一partition内的消息是有序的,不同partition的消息是无序的。
MA中如果要保证同一个任务的数据是顺序传递的,会把同一个任务的消息分到同一个分区中。
Kafka高级工具
TODO: 探索Kafka生态系统中的相关工具和组件,如Kafka Connect和Kafka Streams,分享它们的作用和使用方式,以及如何将Kafka与其他技术进行集成
故障处理
常用kafka的命令:开源 kafka 使用指南
- 查看kafka状态
- 通过Grafanna监控,查看堆积情况(lag)
- 手动启动一个消费者线程,通过查看消费的日志,来判断消费是否正常:适用于机器日志因时间过长被清理的情况。
- 常用命令:https://blog.csdn.net/asd136912/article/details/103735037
进一步学习的资料:
kafka官网:https://kafka.apache.org/34/documentation.html
配置持久化时间:(默认为7天)https://blog.csdn.net/neweastsun/article/details/127109802文章来源:https://www.toymoban.com/news/detail-672294.html
参考资料:
https://aws.amazon.com/message-queue/?nc1=h_ls
https://blog.csdn.net/neweastsun/article/details/127109802
https://www.upsolver.com/blog/apache-kafka-architecture-what-you-need-to-know文章来源地址https://www.toymoban.com/news/detail-672294.html
到了这里,关于Kafka 简介 + 学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!