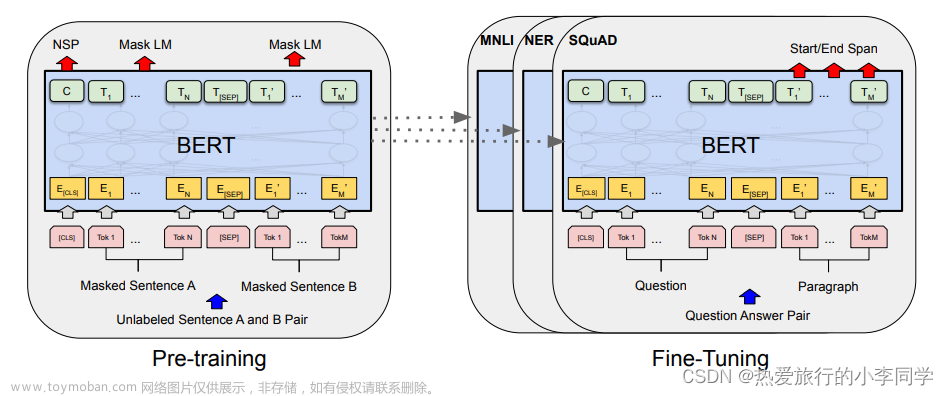
利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值 MERGE_RATIO ,从前往后依次判断相邻两个段落的相似度分数是否大于MERGE_RATIO ,如果大于则合并,否则断开。文章来源地址https://www.toymoban.com/news/detail-672479.html
import torch
from transformers import BertModel,BertTokenizer
#加载字典和分词工具,即tokenizer
tokenizer= BertTokenizer.from_pretrained('bert-base-chinese') # 要跟预训练模型相匹配
#加载预训练模型
model= BertModel.from_pretrained('bert-base-chinese')
TEMPERATURE = 1 #温度函数 自定义
MERGE_RATIO = 0.9 #阈值分数 自定义
def is_nextsent(sent, next_sent):
encoding = tokenizer(sent, next_sent, return_tensors="pt",truncation=True, padding=False)
with torch.no_grad():
outputs = model(**encoding, labels=torch.LongTensor([1]))
logits = outputs.logits
probs = torch.softmax(logits/TEMPERATURE, dim=1)
next_sentence_prob = probs[:, 0].item()
if next_sentence_prob <= MERGE_RATIO:
return False
else:
return True
文章来源:https://www.toymoban.com/news/detail-672479.html
到了这里,关于bert-base-chinese 判断上下句的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!