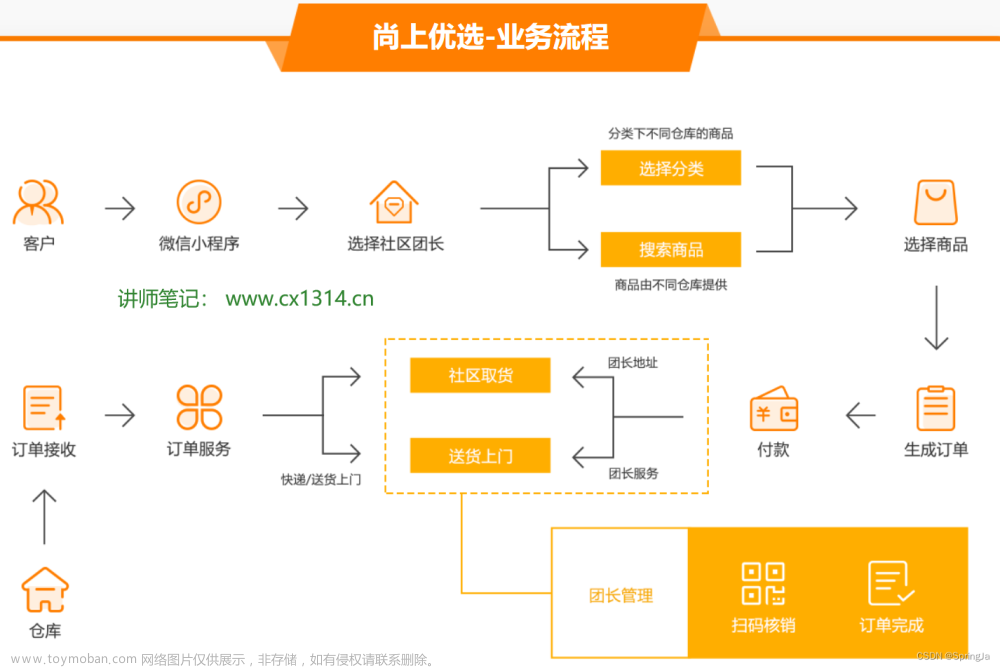
先看基本的业务流程

那么我们可以看到整个流程都是一个线程来完成的,这样的话耗时还是很长的,那么可不可以采用多线程去实现呢?
首先我们要思考怎么对业务进行拆分,可以想象一个我们去饭店点餐,会有前台接待,询问订单,之后将小票传给后厨去做饭,这样就会快很多,也可以接待更多的客人
也就是说 一个线程负责去读数据库做准备工作,另一个线程去实现写操作,如下图中所示:

确定了我们可以将判断库存和检验一人一单业务抽取出来之后,我们在想一下 还能不能优化,这个时候我们会发现,这两个操作还是在数据库进行的,那么mysql的并发本身也是不高的,现在我们就要通过另一个性能更好的数据库进行实现,就是redis

这样只需要业务进行到校验完成就可以给用户返回下单完成的信息,之后在通过另一个线程异步进行扣减库存操作
redis中实现上面两个操作的业务流程如下:

由于操作流程较长,应该使用lua脚本来保证原子性
将上面的逻辑采用lua脚本进行编写,之后程序运行首先判断返回值如果是0就说明用户有下单资格,如果是1或者2就说明用户没有资格下单
如果有下单资格就可以将用户id,优惠券id,和订单id存入一个阻塞队列里面,之后异步进行写入数据库操作
整体流程:

提供lua脚本代码
-- 1.参数列表
-- 1.1.优惠券id
local voucherId = ARGV[1]
-- 1.2.用户id
local userId = ARGV[2]
-- 1.3.订单id
local orderId = ARGV[3]
-- 2.数据key
-- 2.1.库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2.订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1.判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2.库存不足,返回1
return 1
end
-- 3.2.判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6.发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ...
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0使用方式
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.返回订单id
return Result.ok(orderId);
}redis的流程到此就完结了,接下来就是使用阻塞队列存储要进行写操作的信息
阻塞队列的实现方式通常是使用一个先进先出的队列来存储元素,同时使用锁来实现线程安全。当队列为空时,put()方法会被阻塞,直到有元素被添加到队列中;当队列满时,put()方法同样会被阻塞,直到队列中有元素被移除。
阻塞队列通常用于生产者-消费者模型中,生产者将元素添加到队列中,消费者从队列中取出元素进行处理。通过使用阻塞队列,可以避免生产者和消费者之间的直接交互,从而简化了代码的设计和维护。
首先我们可以可以使用java自带的阻塞队列实现,提供一个样例:文章来源:https://www.toymoban.com/news/detail-672797.html
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ProducerConsumerExample {
public static void main(String[] args) {
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10); // 创建一个容量为10的阻塞队列
Thread producer = new Thread(new Producer(queue));
Thread consumer = new Thread(new Consumer(queue));
producer.start();
consumer.start();
}
}
class Producer implements Runnable {
private BlockingQueue<Integer> queue;
public Producer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
try {
System.out.println("Producing " + i);
queue.put(i); // 将元素添加到队列中
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Consumer implements Runnable {
private BlockingQueue<Integer> queue;
public Consumer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
Integer item = queue.take(); // 从队列中取出元素进行处理
System.out.println("Consuming " + item);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
当然如果想要性能更好的话,我们可以采用消息队列来做文章来源地址https://www.toymoban.com/news/detail-672797.html
到了这里,关于秒杀系统的业务流程以及优化方案(实现异步秒杀)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!