这篇具有很好参考价值的文章主要介绍了es和数据库同步方案。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
5.5 课程信息索引同步
5.5.1 技术方案
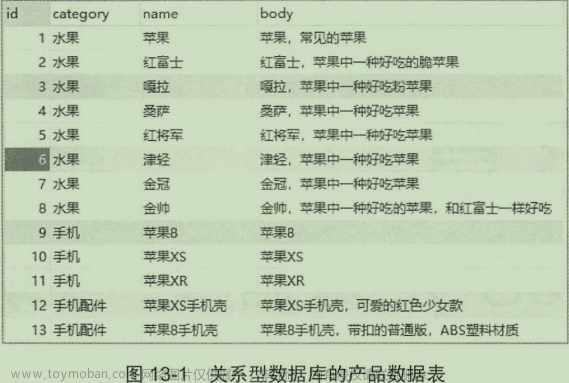
通过向索引中添加课程信息最终实现了课程的搜索,我们发现课程信息是先保存在关系数据库中,而后再写入索引,这个过程是将关系数据中的数据同步到elasticsearch索引中的过程,可以简单成为索引同步。
通常项目中使用elasticsearch需要完成索引同步,索引同步的方法很多:
1、针对实时性非常高的场景需要满足数据的及时同步,可以同步调用,或使用Canal去实现。
1)同步调用即在向MySQL写数据后远程调用搜索服务的接口写入索引,此方法简单但是耦合代码太高。
2)可以使用一个中间的软件canal解决耦合性的问题,但存在学习与维护成本。
canal主要用途是基于 MySQL 数据库增量日志解析,并能提供增量数据订阅和消费,实现将MySQL的数据同步到消息队列、Elasticsearch、其它数据库等,应用场景十分丰富。

它的地址:
github地址:https://github.com/alibaba/canal
版本下载地址:https://github.com/alibaba/canal/releases
文档地址:https://github.com/alibaba/canal/wiki/Docker-QuickStart
Canal基于mysql的binlog技术实现数据同步,什么是binlog,它是一个文件,二进制格式,记录了对数据库更新的SQL语句,向数据库写数据的同时向binlog文件里记录对应的sql语句。当数据库服务器发生了故障就可以使用binlog文件对数据库进行恢复。
所以,使用canal是需要开启mysql的binlog写入功能,Canal工作原理如下:

1、canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump
协议
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
3、canal 解析 binary log 对象(原始为 byte 流)
详细使用Canal进行索引同步的步骤参考:Canal实现索引同步.pdf
2、当索引同步的实时性要求不高时可用的技术比较多,比如:MQ、Logstash、任务调度等。
MQ:向mysql写数据的时候向mq写入消息,搜索服务监听MQ,收到消息后写入索引。使用MQ的优势是代码解耦,但是需要处理消息可靠性的问题有一定的技术成本,做到消息可靠性需要做到生产者投递成功、消息持久化以及消费者消费成功三个方面,另外还要做好消息幂等性问题。但是MQ会产生数据可靠性问题,在之前的文档之我们讲解了MQ的消息可靠性。使用MQ技术实现难度还是比较大的。
Logstash: 开源实时日志分析平台 ELK包括Elasticsearch、Kibana、Logstash,Logstash负责收集、解析和转换日志信息,可以实现MySQL与Elasticsearch之间的数据同步。也可以实现解耦合并且是官方推荐,但需要增加学习与维护成本。
任务调度:向mysql写数据的时候记录修改记录,开启一个定时任务根据修改记录将数据同步到Elasticsearch。
我们实现这个同步功能使用索引同步的方案进行解决。
实现代码
1、拷贝CourseIndex 模型类到内容管理model 工程的dto包下。
2、在内容管理服务中添加FeignClient
| Java
package com.xuecheng.content.feignclient;
import com.xuecheng.content.model.dto.CourseIndex;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
/**
* @description 搜索服务远程接口
* @author Mr.M
* @date 2022/9/20 20:29
* @version 1.0
*/
@FeignClient(value = "search",fallbackFactory = SearchServiceClientFallbackFactory.class)
public interface SearchServiceClient {
@PostMapping("/search/index/course")
public Boolean add(@RequestBody CourseIndex courseIndex);
} |
定义SearchServiceClientFallbackFactory :
| Java
@Slf4j
@Component
public class SearchServiceClientFallbackFactory implements FallbackFactory<SearchServiceClient> {
@Override
public SearchServiceClient create(Throwable throwable) {
return new SearchServiceClient() {
@Override
public Boolean add(CourseIndex courseIndex) {
throwable.printStackTrace();
log.debug("调用搜索发生熔断走降级方法,熔断异常:", throwable.getMessage());
return false;
}
};
}
} |
3、编写课程索引任务执行方法
完善CoursePublishTask类中的saveCourseIndex方法文章来源:https://www.toymoban.com/news/detail-672989.html
| Java
//保存课程索引信息
public void saveCourseIndex(MqMessage mqMessage,long courseId){
log.debug("保存课程索引信息,课程id:{}",courseId);
//消息id
Long id = mqMessage.getId();
//消息处理的service
MqMessageService mqMessageService = this.getMqMessageService();
//消息幂等性处理
int stageTwo = mqMessageService.getStageTwo(id);
if(stageTwo > 0){
log.debug("课程索引已处理直接返回,课程id:{}",courseId);
return ;
}
Boolean result = saveCourseIndex(courseId);
if(result){
//保存第一阶段状态
mqMessageService.completedStageTwo(id);
}
}
private Boolean saveCourseIndex(Long courseId) {
//取出课程发布信息
CoursePublish coursePublish = coursePublishMapper.selectById(courseId);
//拷贝至课程索引对象
CourseIndex courseIndex = new CourseIndex();
BeanUtils.copyProperties(coursePublish,courseIndex);
//远程调用搜索服务api添加课程信息到索引
Boolean add = searchServiceClient.add(courseIndex);
if(!add){
XueChengPlusException.cast("添加索引失败");
}
return add;
}文章来源地址https://www.toymoban.com/news/detail-672989.html |
到了这里,关于es和数据库同步方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!