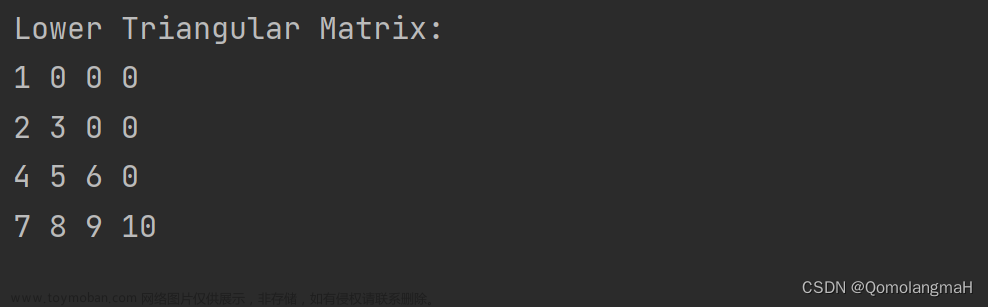
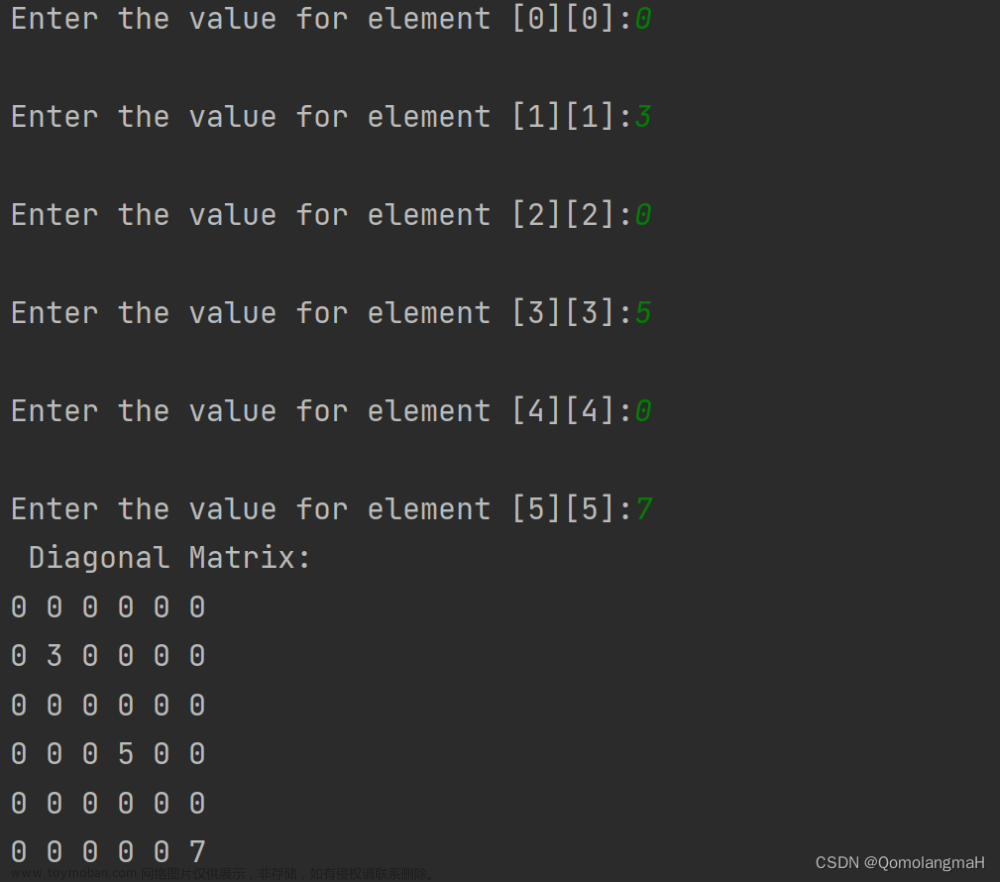
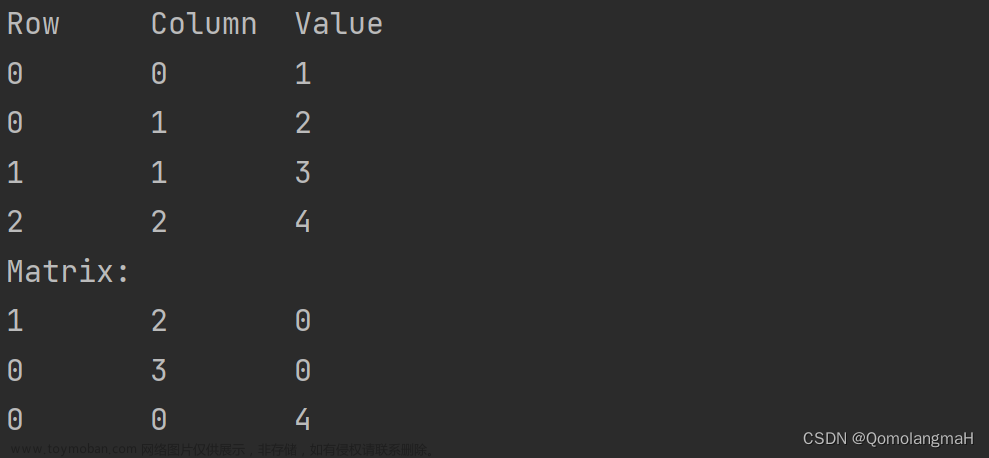
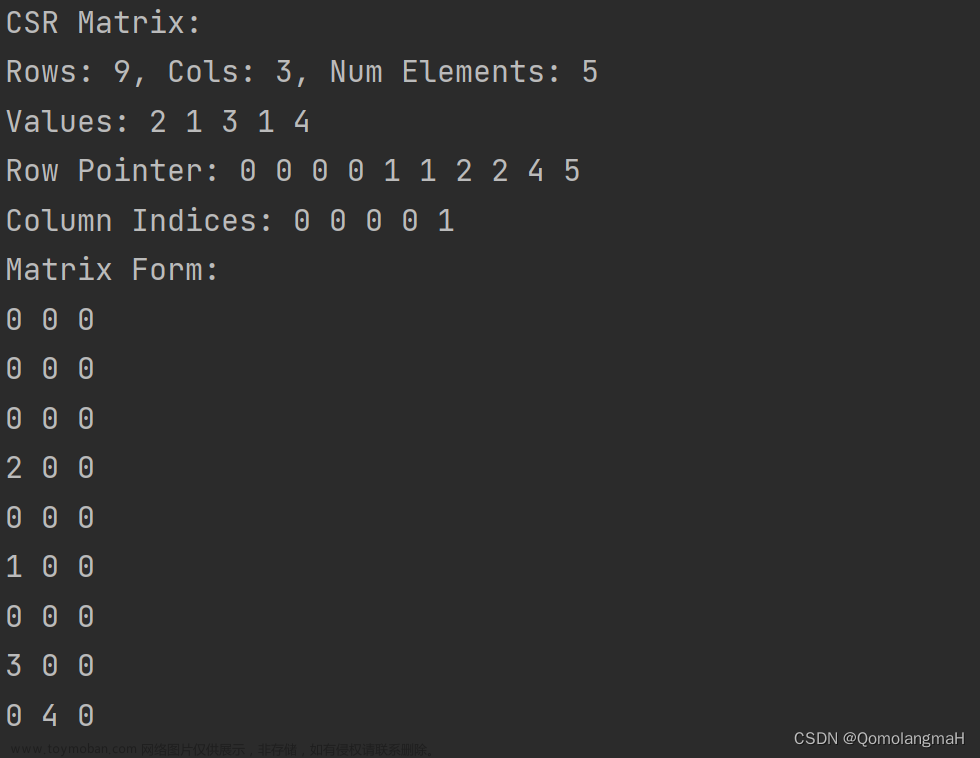
首先我们需要明确
c
t
c
l
o
s
s
ctcloss
ctcloss是用来做什么的。比如说要生成的目标字符串长度为
l
l
l,而这个字符串包含
s
s
s个字符,字符串允许的最大长度为
L
L
L,这里认为一个位置是一个时间步,就是一拍,记为
T
T
T。
对于这个允许最大长度,需要做出一些解释,定义一个生成字符串的规则,因为训练的时候,这个标签的长度是不一样的,所以我们需要引入空格来生成字符串,那么相应的,关于空格定义以下两条规则:
- 空格与空格之间的字符串是可以去掉重复字母的
- 使用空格间隔的两个部分串不能去重,比如说这个串长成:
cc cc,在运用上述两条规则之后应该变成c c
举例来说,对于目标生成串如果是
C
A
T
CAT
CAT的话,那么在时间拍为
5
5
5拍的情况下,他有这以下
28
28
28条路径可以生成
C
A
T
CAT
CAT
注:上述图片引自这里,博主对这篇文章加以致谢,还好有这个文章让我对
c
t
c
l
o
s
s
ctcloss
ctcloss有了初步的认识。
因此首先拿在手里的是一个随机矩阵为
y
y
y,这个矩阵的形状是
[
k
,
T
]
[k,T]
[k,T],其中
y
[
i
,
j
]
y[i,j]
y[i,j]表示的是在第
j
j
j个时间步,该字符为
i
i
i的概率,而我们需要做的是训练这个
y
y
y矩阵,让他最终产生指定字符串的概率
p
p
p最大,所以设置
−
l
n
(
p
)
-ln(p)
−ln(p)为损失函数,目标就是让这个损失函数最小。
那么应该怎么做呢?你可以枚举出这全部
28
28
28条路径的概率,
l
i
k
e
t
h
i
s
like\space this
like this,然后把他们相加之后求损失和。
 但是我知道你一定不想这么做。所以呢,我们需要使用一种更加简洁的方法来求这个概率,咋做呢?这里就要放上这张过程图了。
但是我知道你一定不想这么做。所以呢,我们需要使用一种更加简洁的方法来求这个概率,咋做呢?这里就要放上这张过程图了。

首先对字符串进行了插入空格的操作,我一开始的时候不给他插入空格不行,必须得考虑每一步能不能取到空格,并且状态转移的时候,还要考虑从第几个空格转移过来,非常麻烦,不如直接插入空格。接下来使用动态规划的方法来代替暴力搜索,分析 t t t时刻由 t − 1 t-1 t−1时刻字符的状态转移方程:
- 在 t t t时刻,能取到 s s s字符,那么这个字符可以由 t − 1 t-1 t−1时刻的 s s s字符转移过来,两个一样的字符消去就行了呗。
- 由 s − 1 s-1 s−1字符转移过来 , , ,就是 _ C _ A _ T _ \_C\_A\_T\_ _C_A_T_的 T T T接在 _ \_ _后面的情况。
- 从第 s − 2 s-2 s−2个字符转移过来,这个时候第 s s s个字符和第 s − 2 s-2 s−2个字符必须不能相同,否则的话就是 _ C _ A _ A _ T _ \_C\_A\_A\_T\_ _C_A_A_T_的两个 A A A越过中间的空格连在一起,这不铁定消去了。
所以状态转移使用如下的方法实现:
alpha[s, t] = alpha[s, t - 1]
if s - 1 >= 0:
alpha[s, t] += alpha[s - 1, t - 1]
if s - 2 >= 0 and blank_label[s] != '0' and blank_label[s] != blank_label[s - 2]:
alpha[s, t] += alpha[s - 2, t - 1]
alpha[s, t] *= y[map_dict[blank_label[s]], t]
但是你一定会问弄这个动态规划矩阵有个锤子用,我们来看看:
对于
a
l
p
h
a
alpha
alpha矩阵当中的任意一个元素来说,可以得到以下的表达式,其中
l
l
l是任意一个可能产生字符串的路径,
π
\pi
π是全部路径,
l
t
l_t
lt代表这个路径上在第
t
t
t拍上的字符,
P
P
P为概率。
a
l
p
h
a
[
i
,
t
]
=
P
(
l
t
)
∑
l
∈
π
∏
t
′
=
1
t
−
1
P
(
l
t
′
)
alpha[i,t] = P(l_t)\sum_{l\in \pi} \prod_{t'=1}^{t-1} P(l_{t'})
alpha[i,t]=P(lt)l∈π∑t′=1∏t−1P(lt′)
那么如果求出后向传播的矩阵
b
e
t
a
beta
beta:
b
e
t
a
[
i
,
t
]
=
P
(
l
t
)
∑
l
∈
π
∏
t
′
=
t
+
1
T
P
(
l
t
′
)
beta[i,t] = P(l_t)\sum_{l\in \pi} \prod_{t'=t+1}^{T} P(l_{t'})
beta[i,t]=P(lt)l∈π∑t′=t+1∏TP(lt′)
就能得到矩阵:
a
l
p
h
a
[
i
,
t
]
∗
b
e
t
a
[
i
,
t
]
=
P
(
l
t
)
∑
l
∈
π
∏
t
′
=
1
T
P
(
l
t
′
)
alpha[i,t]*beta[i,t] = P(l_t)\sum_{l\in \pi} \prod_{t'=1}^{T} P(l_{t'})
alpha[i,t]∗beta[i,t]=P(lt)l∈π∑t′=1∏TP(lt′)
所以我非常想求的总概率
p
=
∑
l
∈
π
∏
t
′
=
1
T
P
(
l
t
′
)
p=\sum_{l\in \pi} \prod_{t'=1}^{T} P(l_{t'})
p=∑l∈π∏t′=1TP(lt′)就可以使用
a
l
p
h
a
[
i
,
t
]
∗
b
e
t
a
[
i
,
t
]
P
(
l
t
)
\frac{alpha[i,t]*beta[i,t]}{P(l_t)}
P(lt)alpha[i,t]∗beta[i,t]来表示。
公式推导鸣谢:这里
注:这只是我大概的理解,不能十分完备的使用原文章中的符号
接下来就到了非常鸡冻人心的训练过程,差点没给我训练死了。因为改了一天这个梯度公式,并且我体会了什么是梯度消失,
s
o
f
t
m
a
x
softmax
softmax的作用,接下来将详细记录我训练的这个过程,应该只是我记得的了,其中非常感谢参考文献中文章的帮助,尤其是在晚上八点还是没有结果的时候看到的这篇文章,但是当时通过死亡调试梯度矩阵已经反应过来是梯度问题了hh。首先先声明一下:我不能完全保证我的梯度求解没有问题,但是的确训练出了结果,并且参考多篇博客,梯度的结果全都不一样,因此我只能找到一个我认为最合理的梯度来进行梯度下降。
那么再来捋一下思路:首先要最小化
−
l
n
(
p
)
-ln(p)
−ln(p),而前面已经求出
p
=
a
l
p
h
a
[
i
,
t
]
∗
b
e
t
a
[
i
,
t
]
P
(
l
t
)
p=\frac{alpha[i,t]*beta[i,t]}{P(l_t)}
p=P(lt)alpha[i,t]∗beta[i,t],这里将
P
(
l
t
)
P(l_t)
P(lt)换成
y
k
t
y_{k}^{t}
ykt来表示,就是在
t
t
t时刻的第
k
k
k个字符的概率。我们想对
y
y
y求偏导,但有一个
b
u
g
bug
bug就是
y
y
y他不一定每一列的和都是
1
1
1,所以需要对他进行
s
o
f
t
m
a
x
softmax
softmax操作,因此,用
x
k
t
x_{k}^{t}
xkt代表经过
s
o
f
t
m
a
x
softmax
softmax之后的
y
k
t
y_{k}^{t}
ykt。分析一下
y
y
y经过所有变换得到
p
p
p的过程:
y
∼
s
o
f
t
m
a
x
∼
a
l
p
h
a
+
b
e
t
a
∼
p
y\sim softmax \sim alpha+beta \sim p
y∼softmax∼alpha+beta∼p。需要求的梯度经过以上分析可以表示成为:
∂
(
−
l
n
p
)
∂
y
k
t
=
−
1
p
∂
p
∂
x
k
t
∂
x
k
t
∂
y
k
t
\begin{align} \frac{\partial (-lnp)}{\partial y_{k}^{t}} =-\frac{1}{p}\frac{\partial p}{\partial x_{k}^{t}}\frac{\partial x_{k}^{t}}{\partial y_{k}^{t}} \end{align}
∂ykt∂(−lnp)=−p1∂xkt∂p∂ykt∂xkt
前面已经知道:
p
=
a
l
p
h
a
[
i
,
t
]
∗
b
e
t
a
[
i
,
t
]
x
k
t
p=\frac{alpha[i,t]*beta[i,t]}{x_{k}^{t}}
p=xktalpha[i,t]∗beta[i,t],在这个公式当中
a
l
p
h
a
、
b
e
t
a
alpha、beta
alpha、beta与
x
k
t
x_{k}^{t}
xkt并不是完全没有关系的,他们可以表示成
c
o
n
s
1
∗
x
k
t
cons1*x_{k}^{t}
cons1∗xkt的形式,其中
c
o
n
s
1
cons1
cons1是到达
x
k
t
x_{k}^{t}
xkt字符之前的所有可能字符概率乘积的和,
c
o
n
s
2
cons2
cons2同理,值得注意的是,我们的假定是字符的概率是可以相乘的,也就是完全独立的,因此
c
o
n
s
1
cons1
cons1和
c
o
n
s
2
cons2
cons2对于
x
k
t
x_k^t
xkt来说是常数。所以
p
p
p应该化简为
c
o
n
s
1
∗
c
o
n
s
2
∗
x
k
t
cons1*cons2*x_{k}^{t}
cons1∗cons2∗xkt,其中
c
o
n
s
1
=
a
l
p
h
a
x
k
t
,
c
o
n
s
2
=
b
e
t
a
x
k
t
cons1=\frac{alpha}{x_{k}^{t}},cons2 =\frac{beta}{x_{k}^{t}}
cons1=xktalpha,cons2=xktbeta,所以
∂
p
∂
x
k
t
=
a
l
p
h
a
x
k
t
b
e
t
a
x
k
t
\begin{align} \frac{\partial p}{\partial x_{k}^{t}}=\frac{alpha}{x_{k}^{t}}\frac{beta}{x_{k}^{t}} \end{align}
∂xkt∂p=xktalphaxktbeta
由于
x
k
t
=
s
o
f
t
m
a
x
(
y
k
t
)
x_{k}^{t}=softmax(y_{k}^{t})
xkt=softmax(ykt),即
x
k
t
=
e
y
k
t
∑
j
=
1
s
e
y
j
t
x_{k}^{t}=\frac{e^{y_{k}^{t}}}{\sum_{j=1}^{s}e^{y_{j}^{t}}}
xkt=∑j=1seyjteykt,所以有
∂
x
k
t
∂
y
k
t
=
e
y
k
t
∗
∑
j
=
1
s
e
y
j
t
−
(
e
y
k
t
)
2
(
∑
j
=
1
s
e
y
j
t
)
2
=
x
k
t
−
(
x
k
t
)
2
\begin{align} \frac{\partial x_{k}^{t}}{\partial y_{k}^{t}} = \frac{e^{y_{k}^{t}}*\sum_{j=1}^{s}e^{y_{j}^{t}}-(e^{y_{k}^{t}})^2}{(\sum_{j=1}^{s}e^{y_{j}^{t}})^2} =x_{k}^{t}-(x_{k}^{t})^2 \end{align}
∂ykt∂xkt=(∑j=1seyjt)2eykt∗∑j=1seyjt−(eykt)2=xkt−(xkt)2
将
(
2
)
(2)
(2)式和
(
3
)
(3)
(3)代入
(
1
)
(1)
(1)中得到:
∂
(
−
l
n
p
)
∂
y
k
t
=
−
1
p
a
l
p
h
a
∗
b
e
t
a
x
k
t
(
1
−
x
k
t
)
=
a
l
p
h
a
∗
b
e
t
a
p
−
a
l
p
h
a
∗
b
e
t
a
p
∗
x
k
t
\begin{align} \frac{\partial (-lnp)}{\partial y_{k}^{t}}&=-\frac{1}{p}\frac{alpha*beta}{x_{k}^{t}}(1-x_k^t)\\ &=\frac{alpha*beta}{p}-\frac{alpha*beta}{p*x_k^t}\notag \end{align}
∂ykt∂(−lnp)=−p1xktalpha∗beta(1−xkt)=palpha∗beta−p∗xktalpha∗beta
那么到这里我们整个梯度就全部推导完成了,但是这个梯度是不对的,因此接下来根据这个图来研究一下梯度的结构:
我们在做动态规划的时候,并不是每一个节点都被规划了。如果设定目标产生的字符串为
a
b
d
d
c
e
abddce
abddce,一共有
8
8
8拍,也就是
a
l
p
h
a
alpha
alpha长成这样:
然后我们在看看
y
y
y,注意这里面的
y
y
y包含空格,且与这个表
相对应:
我们发现第一拍里面只有空格和字母
a
a
a是允许有值的,也就是其余位置的
a
l
p
h
a
alpha
alpha和
b
e
t
a
beta
beta都是
0
0
0,这很容易理解,在某一个拍某个字母完全没有可能取到的话,在前向更新的概率
p
p
p中也不会被计算。因此来看一下梯度
a
l
p
h
a
∗
b
e
t
a
p
−
a
l
p
h
a
∗
b
e
t
a
p
∗
x
k
t
\frac{alpha*beta}{p}-\frac{alpha*beta}{p*x_k^t}
palpha∗beta−p∗xktalpha∗beta,按照这个概率计算的话,所有不可能取到的点的梯度都是
0
0
0,但是这些字母对应的
y
y
y值是需要用梯度更新为
0
0
0的,所以这就是昨天我训练了一大天都没啥用的原因,当然还要包括推公式、初始化、没有归一化、梯度消失的错误。。。
所以最合理的办法就是分类讨论,但是重新观察一下这个梯度公式
a
l
p
h
a
∗
b
e
t
a
p
−
a
l
p
h
a
∗
b
e
t
a
p
∗
x
k
t
\frac{alpha*beta}{p}-\frac{alpha*beta}{p*x_k^t}
palpha∗beta−p∗xktalpha∗beta,发现
a
l
p
h
a
∗
b
e
t
a
p
\frac{alpha*beta}{p}
palpha∗beta,在被更新到的节点位置,这个值的取值应该是
x
k
t
x_k^t
xkt,如果将梯度写成
x
k
t
−
a
l
p
h
a
∗
b
e
t
a
p
∗
x
k
t
x_k^t-\frac{alpha*beta}{p*x_k^t}
xkt−p∗xktalpha∗beta的话,那么在没有更新到的节点位置,其
a
l
p
h
a
alpha
alpha和
b
e
t
a
beta
beta应该是
0
0
0,虽然这个是归一化之后的
y
y
y,但是起码梯度位置有值了,因此实际的计算梯度为:
∂
(
−
l
n
p
)
∂
y
k
t
=
x
k
t
−
a
l
p
h
a
∗
b
e
t
a
p
∗
x
k
t
\frac{\partial (-lnp)}{\partial y_{k}^{t}}=x_k^t-\frac{alpha*beta}{p*x_k^t}
∂ykt∂(−lnp)=xkt−p∗xktalpha∗beta
最终训练结果:
['e', 'd', '0', 'd', 'd', 'e', 'd', 'd', '0']
['e', 'd', '0', 'd', 'd', 'e', 'd', 'd', '0']
['e', 'd', '0', 'd', 'd', 'e', 'd', 'd', '0']
['e', 'a', '0', 'd', 'd', 'e', 'd', 'c', '0']
['e', 'a', '0', 'd', 'd', 'e', 'd', 'c', '0']
['e', 'a', '0', 'd', 'd', 'd', 'd', 'c', '0']
['e', 'a', '0', 'd', 'd', 'd', 'd', 'c', 'e']
['e', 'a', '0', 'd', 'd', 'd', 'd', 'c', 'e']
['e', 'a', '0', 'd', 'd', 'd', 'd', 'c', 'e']
['e', 'a', '0', 'd', 'd', 'd', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['e', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
['0', 'a', 'b', 'd', 'd', '0', 'd', 'c', 'e']
整个过程代码:文章来源:https://www.toymoban.com/news/detail-673143.html
import numpy as np
import math
def insert_blank(labels):
l_ = []
l_.append('0')
for i in range(len(labels)):
l_.append(labels[i])
l_.append('0')
return l_
def std_matrix(alpha):
alpha = math.e ** alpha
b = alpha.sum(axis=0)
return alpha / b
def check():
print(math.e ** alpha[-1][-1] + math.e ** alpha[-2][-1] - math.e ** beta[0][1] - math.e ** beta[1][1])
for i in range(alpha.shape[0]):
for j in range(alpha.shape[1]):
alpha[i, j] = alpha[i, j] + beta[i, j]
print(alpha)
def decode_fn(y, chars):
res = []
for j in range(y.shape[1]):
t = -1
max_ = -1
for i in range(y.shape[0]):
if (y[i, j] > max_):
max_ = y[i, j]
t = i
res.append(chars[t])
return res
'''
the init process
'''
T = 8
labels = ['a', 'b', 'd', 'd', 'c', 'e']
chars = ['0', 'a', 'b', 'c', 'd', 'e']
y = np.random.rand(len(chars), T + 1) # 这个还得包含空格,4个字符,5拍
x = std_matrix(y)
map_dict = {'0': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 4, 'f': 5}
alk = 0.09
blank_label = insert_blank(labels)
length = len(labels)
length_ = len(blank_label)
epoch = 80
'''
train process
'''
for m in range(epoch):
alpha = np.zeros((len(blank_label), T + 1)) # 这个一共是5拍
for i in range(alpha.shape[0]):
for j in range(alpha.shape[1]):
alpha[i, j] = -math.inf
alpha[0][1] = np.log(x[0][1]) # 这个是在第一个时刻,选空格
alpha[1][1] = np.log(x[1][1]) # 这个是在第一个时刻,选第一个字符
beta = np.ones((len(blank_label), T + 1))
for i in range(beta.shape[0]):
for j in range(beta.shape[1]):
beta[i, j] = -math.inf
beta[-1][-1] = np.log(x[-1][-1])
beta[-2][-1] = np.log(x[-2][-1])
'''
forward
'''
for t in range(2, T + 1):
lim_down = max(2 * (length - (T - t + 1)) + 1, 0)
lim_up = min(2 * t - 1, length_ - 1)
for s in range(lim_down, lim_up + 1, 1):
alpha[s, t] = math.e ** alpha[s, t - 1]
if s - 1 >= 0:
alpha[s, t] += math.e ** alpha[s - 1, t - 1]
if s - 2 >= 0 and blank_label[s] != '0' and blank_label[s] != blank_label[s - 2]:
alpha[s, t] += math.e ** alpha[s - 2, t - 1]
alpha[s, t] = np.log(alpha[s, t])
alpha[s, t] += np.log(x[map_dict[blank_label[s]], t])
# print(alpha)
'''
backward
'''
for t in range(T - 1, 0, -1):
lim_down = max(2 * (length - (T - t + 1)) + 1, 0)
lim_up = min(2 * t - 1, length_ - 1)
for s in range(lim_up, lim_down - 1, -1):
beta[s, t] = math.e ** beta[s, t + 1]
if s + 1 < length_:
beta[s, t] += math.e ** beta[s + 1, t + 1]
if s + 2 < length_ and blank_label[s] != '0' and blank_label[s] != blank_label[s + 2]:
beta[s, t] += math.e ** beta[s + 2, t + 1]
beta[s, t] = np.log(beta[s, t])
beta[s, t] += np.log(x[map_dict[blank_label[s]]][t])
check = np.zeros((len(chars), T + 1))
p = math.e ** alpha[-1][-1] + math.e ** alpha[-2][-1]
# p = math.e ** p
grad = np.zeros((len(chars), T + 1))
for i in range(x.shape[0]):
for j in range(x.shape[1]):
ab = 0
for k in range(alpha.shape[0]):
if alpha[k][j] == -np.inf or beta[k][j] == -np.inf:
continue
if blank_label[k] == chars[i]:
ab += (math.e ** alpha[k][j]) * (math.e ** beta[k][j])
check[i, j] = ab / x[i, j]
# if(x[i][j] == 0):
# print(x,y)
# ab_x2 = ab / (x[i, j] ** 2)
grad[i, j] = x[i, j] - ab/ (p*x[i,j])
# print(y)
y = y - grad * alk
y = np.where(y > 0, y, 0)
x = std_matrix(y)
print(decode_fn(x, chars))
若您对我的文章有任何疑问都欢迎指出
参考文章:文章来源地址https://www.toymoban.com/news/detail-673143.html
- 文章1
- 文章2
到了这里,关于使用ctcloss训练矩阵生成目标字符串的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!