目录
1.模型基本分类
1.1 CheckPoint 大模型/底模型/主模型
1.2 VAE美化模型/变分自编码器
1.3 HyperNetwork 超网络
1.4 embeddings(/Textual Inversion) 嵌入式向量
1.5 loRa 低秩适应模型
2. 下载途径和渠道
2.1 C站
2.1.1 如何筛选到自己需要的模型
2.1.2 使用技巧
2.1.3 学习他人作品
2.2 HuggingFace
想要做出好的AI绘画,模型是最重要的,他相当于AI绘画的大脑,决定了AI绘画质量的上限,所以了解AI绘画的各种模型非常重要
相比于Midjourney,Stable Diffusion最大的优势就是开源。
因而SD则每时每刻都有人在世界各地训练自己的模型并免费公开共享给全世界的使用者。当然我们也可以训练自己的专属模型
提示词+模型+参数设置
全能型赛博画手
首先我们来了解一下模型的基本分类
1.模型基本分类
具体模型类型有checkpoint、Textual lnversion、Hypernetwork、Aesthetic Gradient、LoRA、LyCORIS、Controlnet、Poses、wildcards等等
常用的有checkpoint
哇塞,这么多,那么这些究竟都是什么意思呢?
1.1 CheckPoint 大模型/底模型/主模型
检查点,常玩游戏的朋友肯定不陌生,一般会在一些节点存档
一个大的模型训练起来是非常费力的,如果每次迭代我们都从头训练那可真实个灾难,因而训练到一定程度我们就给模型存档,生成一个关键点Checkpoint模型,
常见文件后缀:后缀ckpt、safetensors(如果都有提供的话建议下载safetensors,下同)
存放路径: 根目录\models\Stable-diffusion
占用存储: 模型较大,占用3-7GB
我们这里的根目录都是指我们webui的最外层的那个文件夹,比如我这里的是stable-diffusion-webui
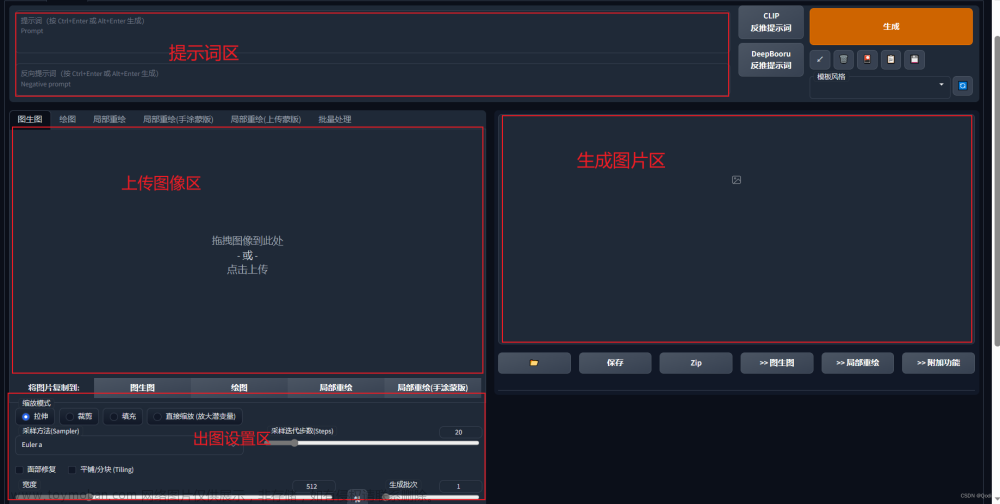
使用方法 将模型移动到根目录\models\Stable-diffusion后,在webui界面点击刷新按钮,再点下拉就可以看到了
文章来源:https://www.toymoban.com/news/detail-673190.html

模型推荐
二次元模型
menia mix 生成动漫
AbyssOrangeMix 深源橘
counter-feit v2.5 动漫模型
dream Shper v5 模型 肖像画 梦幻的插画风格
真实系模型
realistic vision v2.0 现实模型
Delibe-rate 比较全能的一个模型
在本章第二节可以看到如何利用其他网站来筛选自己需要的模型
1.2 VAE美化模型/变分自编码器
从使用来看,我们可以把他粗略的理解为“调色滤镜” 有些时候不加载VAE的情况下,出图就会发灰发白
有很多比较新的大模型是会将VAE整合到内部的,比如Chilloutmix。如果再加VAE则可能画面效果不会更好,甚至适得其反
而有的大模型则会有自己适配的VAE,如深渊橘,这里看模型网站上作者的推荐就好
也有一些适用于大多数模型的VAE
二次元风格:kf-f8-anime
写实风格:840000
常见文件后缀:后缀ckpt、pt
存放路径: 根目录/models/VAE
占用存储: 模型较小,占用0-1个GB
使用方法 将模型移动到根目录\models\VAE后,在VAE选项点击刷新按钮,再点下拉就可以看到了
1.3 HyperNetwork 超网络
hypernetworks是一个附加到stable diffusion model上的小型网络,用于微调,和embedings类似,不过现在用的也不是很多了,因为它的功能基本可以被smbeddings替代了
常见文件后缀: 后缀pt
存放路径: 根目录/models/hypernetworks
占用存储: 模型较小,占用几百MB
使用方法 注意HyperNetwork,embeddings这种微调网络和大模型使用方法不同
(1)将模型放到 根目录/models/hypernetworks
(2)首先点击生成按钮下的从左往右数的第三个,然后点击超网络,再点击需要用到的超网络模型,就会在提示词中添加相应的尖括号内容,如本例中的<hypernet>

1.4 embeddings(/Textual Inversion) 嵌入式向量
(1)优化画风,
(2)通过仅使用的几张图像,向模型教授新的概念,比如AI不知道奥特曼,通过embeddigns就可以让AI知道奥特曼长什么样子
(3)减少提示词的输入,比如EasyNegative这个Embeddings,里面包含了大量的负面词,可以减少你每次打一堆负面词的痛苦,解决AI绘画痛点,如画手等等
常见文件后缀: 后缀pt
存放路径: 根目录/embeddings
模型的切换通过文件名称来触发
占用存储: 模型很小,占用几十kB到几百kB
使用方法:
(1)将模型放到 根目录/embeddings目录下
(2)同HyperNetwork超网络,首先点击生成按钮下的从左往右数的第三个,然后点击嵌式入,再点击需要用到的嵌入式模型,就会在提示词中添加相应的尖括号内容
1.5 loRa 低秩适应模型
进行人物模型的微调,
让AI学习到一些新的人物概念
常见文件后缀: 后缀safesensors
存放路径: 根目录/embeddings
占用存储: 模型较小,10-200 MB。必须与checkpoint模型一起使用。
使用方法:
(1)将模型放到 根目录/models/Lora
(2)同HyperNetwork超网络,首先点击生成按钮下的从左往右数的第三个,然后点击Lora,再点击需要用到的Lora模型,就会在提示词中添加相应的尖括号内容
除了这些以外还有DreamBooth模型,LyCORIS模型等等,这些模型在模型的进阶用法给大家介绍
2. 下载途径和渠道
SD官方会发布模型
但是官方这个模型出图风格比较单一,因而我们现在下载使用的大多是私人训练的
主流下载网站
2.1 C站
需要科学上网 C站是最主流的一个AI绘画模型网站了,对于模型都是图像化展示,非常便捷

2.1.1 如何筛选到自己需要的模型
1 通过模型生成内容区分查找 模型栏目上边有一排可以选择的

2 利用我们第一节讲到的模型类型区分

2.1.2 使用技巧
注意模型的各种信息,包括作者推荐的VAE,分辨率设置,采样方式等等
如我们点击进入ReV Animated这个模型的下载界面,在模型的介绍界面里有show More

然后就可以看到作者推荐的VAE啦,提示词prompting啦之类的

初学可以使用别人推荐的一些大模型
stable diffusion 常用大模型解释和推荐(持续更新ing) - 知乎 (zhihu.com)
2.1.3 学习他人作品
C站除了优秀的模型以外,还会有很多优秀的作品,我们可以学习他们的模型搭配,提示词等等
点击C站的Images

点进去以后就可以看到详细的图片生成信息,模型搭配,提示词,采样方式,种子等等

2.2 HuggingFace
不需要科学上网,网速较快

Hugging Face – The AI community building the future.文章来源地址https://www.toymoban.com/news/detail-673190.html
到了这里,关于Stable Diffusion 系列教程 | 打破模型壁垒的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!