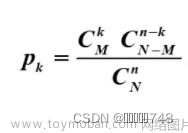1 数据位置 (Measures of location)
对于数据集:
7
,
9
,
9
,
10
,
10
,
11
,
11
,
12
,
12
,
12
,
13
,
14
,
14
,
15
,
16
7,9,9,10,10,11,11,12,12,12,13,14,14,15,16
7,9,9,10,10,11,11,12,12,12,13,14,14,15,16
- 计算加权平均数,其中权重为: 2 , 1 , 3 , 2 , 1 , 1 , 2 , 2 , 1 , 3 , 2 , 1 , 1 , 1 , 1 2,1,3,2,1,1,2,2,1,3,2,1,1,1,1 2,1,3,2,1,1,2,2,1,3,2,1,1,1,1
- 计算截断均值, 去除最高和最低的两个值。
- 计算众数,中位数,方差,标准差
2 数据散布(Measures of spread/dispersion)
使用上述数据集,计算四分位差
3 随机变量的类型和概率分布
考虑一个实验,其中一个包包含 5 个红球和 3 个绿球。随机从中抽取 2 个球,不放回。定义一 个随机变量
X
X
X 为抽取的红球数量。列出
X
X
X 的所有可能值,并为每个值计算概率。
4 理论概率分布之常见的离散型分布
一个生产线上,产品的不合格率为 0.05 。现在从生产线上随机选择10个产品。使用二项分布 计算恰好有 2 个不合格产品的概率。
5 假设学生的智商(IQ)分数分布是标准正态分布,平均值为100,标准差为15。计算以下情况的概率:
一个随机选择的学生的IQ分数高于125的概率。
一个随机选择的学生的IQ分数在85到115之间的概率。
一个随机选择的学生的IQ分数低于70或高于130的概率。
答案
- 数据位置 (Measures of location)
答案:
-
加权平均数 = 18 =18 =18
-
为了计算截断均值,我们首先对数据进行排序,然后删除最高和最低的两个值,然后计算剩余数据的平均值。截断均值 = 11.69 =11.69 =11.69(四舍五入到两位小数)。
-
方差 = 5.69 =5.69 =5.69
-
标准差 = 2.39 =2.39 =2.39
- 数据散布 (Measures of spread/dispersion)
答案:
数据集已经被排序为:
7 , 9 , 9 , 10 , 10 , 11 , 11 , 12 , 12 , 12 , 13 , 14 , 14 , 15 , 16 7,9,9,10,10,11,11,12,12,12,13,14,14,15,16 7,9,9,10,10,11,11,12,12,12,13,14,14,15,16
Q 1 Q 1 Q1 的位置:
位置 = n + 1 4 \text { 位置 }=\frac{n+1}{4} 位置 =4n+1
对于我们的数据集, n = 15 n=15 n=15 ,所以
位置 = 15 + 1 4 = 4 \text { 位置 }=\frac{15+1}{4}=4 位置 =415+1=4
这意味着 Q 1 Q 1 Q1 正好是第 4 个数据点,即 10 。 Q 3 Q 3 Q3 的位置:
位置 = 3 ( n + 1 ) 4 \text { 位置 }=\frac{3(n+1)}{4} 位置 =43(n+1)
对于我们的数据集, n = 15 n=15 n=15 ,所以
位置 = 3 ( 15 + 1 ) 4 = 12 \text { 位置 }=\frac{3(15+1)}{4}=12 位置 =43(15+1)=12
这意味着 Q 3 Q 3 Q3 正好是第 12 个数据点,即 14 。
现在,我们可以计算四分位差:
I
Q
R
=
Q
3
−
Q
1
=
14
−
10
=
4
\mathrm{IQR}=Q 3-Q 1=14-10=4
IQR=Q3−Q1=14−10=4
因此,四分位差 (IQR) 是2。
- 随机变量的类型和概率分布
考虑这样一个实验,从一个包含 5 个红球和 3 个绿球的袋子中随机抽取 2 个球,并不放回。我们 定义一个随机变量 X X X 来表示抽取的红球数量。我们可以为 X X X 的每个可能值计算概率。
P
(
X
=
0
)
P(X=0)
P(X=0) : 抽取两个球都是绿色的。
这个概率可以这样计算:
首先,第一个球是绿色的概率是
3
8
\frac{3}{8}
83 。
接着,第二个球也是绿色的概率是
2
7
\frac{2}{7}
72 (因为已经有一个绿球被抽出,所以只剩下 2 个绿球和 7 个球总数)。
因此,两次事件的联合概率为:
P
(
X
=
0
)
=
3
8
×
2
7
=
6
56
P(X=0)=\frac{3}{8} \times \frac{2}{7}=\frac{6}{56}
P(X=0)=83×72=566 。
P
(
X
=
1
)
P(X=1)
P(X=1) : 抽取的其中一个球是红色,另一个是绿色。
这个概率可以分为两种情况:
第一种情况是首先抽到一个红球,然后抽到一个绿球。概率为
5
8
×
3
7
\frac{5}{8} \times \frac{3}{7}
85×73 。
第二种情况是首先抽到一个绿球,然后抽到一个红球。概率为
3
8
×
5
7
\frac{3}{8} \times \frac{5}{7}
83×75 。
把这两种情况的概率加起来,我们得到:
P
(
X
=
1
)
=
5
8
×
3
7
+
3
8
×
5
7
=
30
56
P(X=1)=\frac{5}{8} \times \frac{3}{7}+\frac{3}{8} \times \frac{5}{7}=\frac{30}{56}
P(X=1)=85×73+83×75=5630 。
P
(
X
=
2
)
P(X=2)
P(X=2) : 抽取两个球都是红色的。
这个概率可以这样计算:
首先,第一个球是红色的概率是
5
8
\frac{5}{8}
85 。
接着,第二个球也是红色的概率是
4
7
\frac{4}{7}
74 (因为已经有一个红球被抽出,所以只剩下 4 个红球和 7 个球总数)。
因此,两次事件的联合概率为:
P
(
X
=
2
)
=
5
8
×
4
7
=
20
56
P(X=2)=\frac{5}{8} \times \frac{4}{7}=\frac{20}{56}
P(X=2)=85×74=5620 。
- 二项分布
假设我们在生产线上随机选择了10个产品,而每个产品都是独立检查的。因此,每个产品不 合格的概率都是 0.05 ,合格的概率则是 0.95 。
现在,我们想要知道恰好有 2 个产品不合格的概率。我们可以使用二项分布公式来计算这一概 率:
P ( X = k ) = ( n k ) p k ( 1 − p ) n − k P(X=k)=\left(\begin{array}{l} n \\ k \end{array}\right) p^k(1-p)^{n-k} P(X=k)=(nk)pk(1−p)n−k
其中:
-
(
n
k
)
\left(\begin{array}{l}n \\ k\end{array}\right)
(nk) 是组合公式,表示从
n
\mathrm{n}
n 个中选择
k
\mathrm{k}
k 个的方法数。它的公式是:
( n k ) = n ! k ! ( n − k ) ! \left(\begin{array}{l} n \\ k \end{array}\right)=\frac{n !}{k !(n-k) !} (nk)=k!(n−k)!n! - n n n 是试验次数,此处为 10 。
- k k k 是成功的次数,此处为 2 。
-
p
p
p 是一次试验成功的概率,此处为 0.05 。
将上述值代入公式,我们可以计算得到恰好有 2 个不合格产品的概率:
P ( X = 2 ) = ( 10 2 ) × 0.0 5 2 × ( 1 − 0.05 ) 10 − 2 P(X=2)=\left(\begin{array}{c} 10 \\ 2 \end{array}\right) \times 0.05^2 \times(1-0.05)^{10-2} P(X=2)=(102)×0.052×(1−0.05)10−2
其中, ( 10 2 ) \left(\begin{array}{c}10 \\ 2\end{array}\right) (102) 是 10 中选择 2 的组合数,计算为:
( 10 2 ) = 10 ! 2 ! ( 10 − 2 ) ! = 10 × 9 2 × 1 = 45 \left(\begin{array}{c} 10 \\ 2 \end{array}\right)=\frac{10 !}{2 !(10-2) !}=\frac{10 \times 9}{2 \times 1}=45 (102)=2!(10−2)!10!=2×110×9=45
将上述值代入公式,我们得到:
P ( X = 2 ) = 45 × 0.0 5 2 × 0.9 5 8 ≈ 0.0746 P(X=2)=45 \times 0.05^2 \times 0.95^8 ≈0.0746 P(X=2)=45×0.052×0.958≈0.0746
- 正态分布
对于正态分布的随机变量 X X X ,我们通常使用以下的公式来计算其概率:
P ( a ≤ X ≤ b ) = P ( X ≤ b ) − P ( X ≤ a ) P(a \leq X \leq b)=P(X \leq b)-P(X \leq a) P(a≤X≤b)=P(X≤b)−P(X≤a)
其中, P ( X ≤ b ) P(X \leq b) P(X≤b) 和 P ( X ≤ a ) P(X \leq a) P(X≤a) 可以从正态分布的累积分布函数 (CDF) 中查找。
对于标准正态分布,均值 μ = 0 \mu=0 μ=0 ,标准差 σ = 1 \sigma=1 σ=1 。但在这个例子中,我们的分布不是标准 的,所以我们需要先将其转换为标准正态分布。这可以通过以下的公式实现:
Z = X − μ σ Z=\frac{X-\mu}{\sigma} Z=σX−μ
其中 Z Z Z 是标准正态分布的随机变量。
计算一个随机选择的学生的IQ分数高于125的概率:
首先, 我们将
I
Q
=
125
I Q=125
IQ=125 转换为标准正态变量:
Z
=
125
−
100
15
Z=\frac{125-100}{15}
Z=15125−100
接着,我们查找标准正态分布表 (或使用计算工具) 来找到
Z
Z
Z 对应的概率
P
(
Z
)
P(Z)
P(Z) 。 最后,我们使用
P
(
X
>
125
)
=
1
−
P
(
Z
)
P(X>125)=1-P(Z)
P(X>125)=1−P(Z) 来得到所求的概率。
计算一个随机选择的学生的IQ分数在85到115之间的概率:
我们首先将
∣
Q
=
85
\mid Q=85
∣Q=85 和
∣
Q
=
115
\mid \mathrm{Q}=115
∣Q=115 都转换为标准正态变量:
Z
1
=
85
−
100
15
Z
2
=
115
−
100
15
\begin{aligned} & Z_1=\frac{85-100}{15} \\ & Z_2=\frac{115-100}{15} \end{aligned}
Z1=1585−100Z2=15115−100
然后,我们查找标准正态分布表来找到
Z
1
Z_1
Z1 和
Z
2
Z_2
Z2 对应的概率
P
(
Z
1
)
P\left(Z_1\right)
P(Z1) 和
P
(
Z
2
)
P\left(Z_2\right)
P(Z2) 。 最后,我们使用上面的公式来计算
P
(
85
≤
X
≤
115
)
=
P
(
Z
2
)
−
P
(
Z
1
)
P(85 \leq X \leq 115)=P\left(Z_2\right)-P\left(Z_1\right)
P(85≤X≤115)=P(Z2)−P(Z1) 。
计算一个随机选择的学生的IQ分数低于70或高于 130 的概率:
我们首先将
1
Q
=
70
1 \mathrm{Q}=70
1Q=70 和
∣
Q
=
130
\mid \mathrm{Q}=130
∣Q=130 都转换为标准正态变量:
Z
1
=
70
−
100
15
Z
2
=
130
−
100
15
\begin{aligned} & Z_1=\frac{70-100}{15} \\ & Z_2=\frac{130-100}{15} \end{aligned}
Z1=1570−100Z2=15130−100
然后,我们查找标准正态分布表来找到
Z
1
Z_1
Z1 和
Z
2
Z_2
Z2 对应的概率
P
(
Z
1
)
P\left(Z_1\right)
P(Z1) 和
P
(
Z
2
)
P\left(Z_2\right)
P(Z2) 。 最后,我们使用以下的公式来得到所求的概率:
P
(
X
<
70
or
X
>
130
)
=
P
(
Z
1
)
+
(
1
−
P
(
Z
2
)
)
P(X<70 \text { or } X>130)=P\left(Z_1\right)+\left(1-P\left(Z_2\right)\right)
P(X<70 or X>130)=P(Z1)+(1−P(Z2))
基于正态分布的计算结果如下:
一个随机选择的学生的IQ分数高于125的概率是 0.0478 (保留四位小数)。
一个随机选择的学生的IQ分数在85到115之间的概率是 0.6827。文章来源:https://www.toymoban.com/news/detail-673234.html
一个随机选择的学生的IQ分数低于70或高于130的概率是 0.0455。文章来源地址https://www.toymoban.com/news/detail-673234.html
到了这里,关于概率论作业啊啊啊的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!