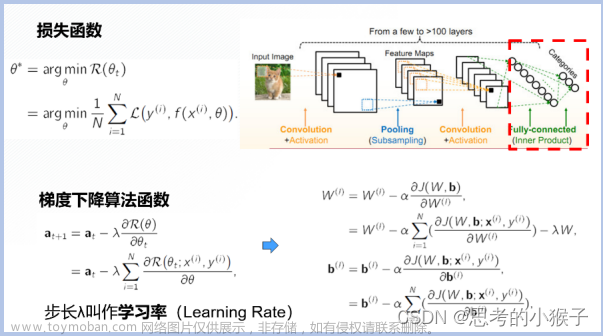
损失函数的作用是衡量模型输出与真实标签的差异。当我们有了这个loss之后,我们就可以通过反向传播机制得到参数的梯度,那么我们如何利用这个梯度进行更新参数使得模型的loss逐渐的降低呢?
优化器的作用
Pytorch的优化器: 管理并更新模型中可学习参数的值, 使得模型输出更接近真实标签。
Optimizer的基本属性

optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
-
defaults: 优化器超参数,里面会存储一些学习率, momentum的值,衰减系数等 -
state: 参数的缓存, 如momentum的缓存(使用前几次梯度进行平均) -
param_groups: 管理的参数组, 这是个列表,每一个元素是一个字典,在字典中有key,key里面的值才是我们真正的参数(这个很重要, 进行参数管理) -
_step_count: 记录更新次数, 学习率调整中使用, 比如迭代100次之后更新学习率的时候,就得记录这里的100.
Optimizer的基本方法

-
zero_grad(): 梯度清零。清空所管理参数的梯度, 这里注意Pytorch有一个特性就是张量梯度不自动清零 -
step(): 执行一步更新 -
add_param_group(): 添加参数组, 我们知道优化器管理很多参数,这些参数是可以分组的,我们对不同组的参数可以设置不同的超参数, 比如模型finetune中,我们希望前面特征提取的那些层学习率小一些,而后面我们新加的层学习率大一些更新快一点,就可以用这个方法。 -
state_dict(): 获取优化器当前状态信息字典 -
load_state_dict():加载状态信息字典,这两个方法用于模型断点的一个续训练, 所以我们在模型训练的时候,一般多少个epoch之后就要保存当前的状态信息。 -

这里就是optimizer的__init__初始化部分了,可以看到上面介绍的那几个属性和它们的初始化方法,当然这里有个最重要的就是参数组的添加,我们看看是怎么添加的
这里重点说一下这个,我们还记得初始化SGD的时候传入了一个形参:optim.SGD(model.parameters(), lr=LR, momentum=0.9),这里的model.parameters() 就是神经网络的每层的参数, SGD在初始化的时候, 会把这些参数以参数组的方式再存起来, 上图中的params就是神经网络每一层的参数。
def __init__(self, params, defaults):这里的params其实就是实参model.parameters() 传入进来的
这就是优化器的初始化工作了, 初始化完了之后, 我们就可以进行梯度清空,然后更新梯度即可:
动量
Momentum:结合当前梯度与上一次更新信息, 用于当前更新。这么说可能有点抽象, 那么我们可以举个比较形象的例子:
指数加权平均在时间序列中经常用于求取平均值的一个方法,它的思想是这样,我们要求取当前时刻的平均值,距离当前时刻越近的那些参数值,它的参考性越大,所占的权重就越大,这个权重是随时间间隔的增大呈指数下降,所以叫做指数滑动平均。公式如下:

vt 是当前时刻的一个平均值,这个平均值有两项构成
- 一项是当前时刻的参数值θt, 所占的权重是1 − β , 这个β是个参数。
- 另一项是上一时刻的一个平均值, 权重是β。
假设我想求第100天温度的一个平均值,那么根据上面的公式:
我们发现,距离当前时刻越远的那些 θ 值,它的权重是越来越小的,因为 β 小于1, 所以间隔越远,小于1的这些数连乘,权重越来越小,而且是呈指数下降,因为这里是βi 。
Momentum梯度下降:
当前梯度的更新量会考虑到之前梯度, 上一时刻的梯度,前一时刻的梯度,这样一直往前,只不过越往前权重越小而已。文章来源:https://www.toymoban.com/news/detail-673365.html
model.state_dict 和 optimizer.state_dict文章来源地址https://www.toymoban.com/news/detail-673365.html
到了这里,关于优化器调整策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[深度学习实战]基于PyTorch的深度学习实战(上)[变量、求导、损失函数、优化器]](https://imgs.yssmx.com/Uploads/2024/02/581963-1.png)