全文共4000余字,预计阅读时间约17~30分钟 | 满满干货(附代码),建议收藏!
本文目标:明确获取OpenAI API密钥的流程,理解如何调用OpenAI的各类大模型,并了解其对应的相关参数

代码下载点这里
一、获取OpenAI的API keys
前提:拥有OpenAI账户,并可以魔法上网,如果涉及账户或魔法上网问题,可参考本文末尾的内容,自行配置!
参考 OpenAI 官网,获取OpenAI的API keys具体的流程如下
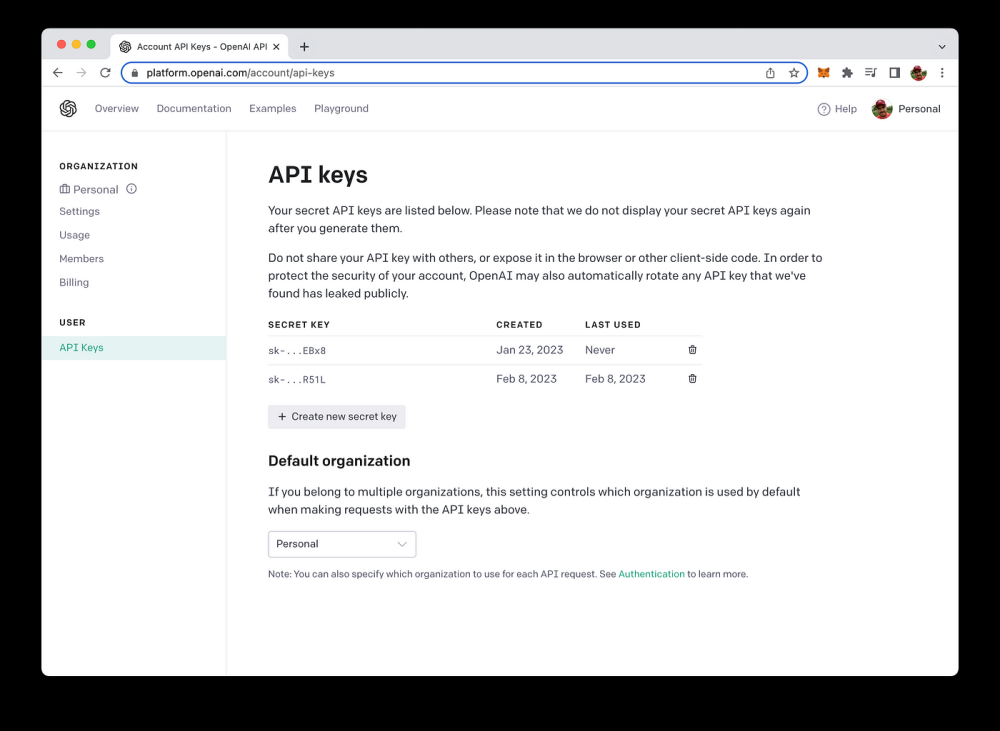
- Step 1:登录OpenAI 账户
使用电子邮件地址和密码登录到 OpenAI 账户

- Step 2:创建 API Key
选择左侧菜单栏的“API Keys”,然后单击“+ Create new API key”按钮.

- Step 3:自定义名称
在弹出的窗口中,为该 API Key 创建一个名称

然后复制保存完成的key编码,注意:要保留好,这个key只在创建的时候可以复制。
二、设置环境变量存储秘钥
将API密钥存储在环境变量中,而不是直接写在代码中,这样做的根本目的是降低泄露密钥的风险。这样,即使有人不小心看到了你的代码,他们也无法获得你的API密钥。毕竟这东西是花钱的,让别人盗用肯定是有风险的!
同时,如果在测试开发中,这样做也易于管理,如果有多个项目都使用了OpenAI API,只需修改环境变量,所有项目都能自动使用新的密钥,省时省力!
在Windows开发环境下的配置方法如下:
- Step 1:进入环境变量

- Step 2:新建系统变量
设置变量名为OPENAI_API_KEY,变量值为OpenAI API秘钥(即上一步复制的那个key),注意:配置完后,要重启电脑才会生效

三、连通性测试
OpenAI官网文档

- Step 1: 安装openai库
!pip install openai
- Step 2:获取系统变量中的秘钥
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
# 如果你不想通过环境变量的方式读取OpenAI API Keys,直接这样写代码
openai.api_key= "API Key"
- Step 3: 测试连通性
# 创建一个 GPT-3 请求
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "user", "content": "Hello, Nice to meet you"}
]
)
print(completion.choices[0].message)
测试成功!

四、OpenAI API的基本参数
4.1 GPT3.5 系列接口


GPT-3.5系列是一系列在2021年第四季度之前的文本和代码混合训练的模型。
以下是GPT-3.5系列中的几个模型
-
code-davinci-oo2是一个基础模型,适用于纯代码补全任务。
-
text-davinci-002是基于code-davinci-002的lnstructGPT模型。
-
text-davinci-003是text-davinci-002的改进版。
-
gpt-3.5-turbo-0301是在text-davinci-003的基础上进行了改进,针对聊天应用进行了优化。
4.2 GPT 4接口
2023年7月7日,OpenAI在官网宣布,gpt-4 api全面开放使用。所有付费api用户都可直接访问8k上下文的gpt-4,无需任何等待。再也不用等申请了!

GPT-4是一个大型多模态模型(目前接受文本输入并生成文本输出,未来将支持图像输入),与gpt-3.5-turbo类似,GPT-4在聊天方面进行了优化,但在传统的完成任务中也能表现出色,都可以使用Chat Completions API。
以下是GPT-4系列中的几个模型
- gpt-4 比任何GPT-3.5模型更强大,能够执行更复杂的任务,并且针对聊天进行了优化。
- gpt-4-32k 与基础gpt-4模型具有相同的功能,但上下文长度增加了4倍。将随最新模型迭代进行更新。
五、API使用方法
5.1 Completions基本调用方法
当调用Completions api时,如果给定一个提示,该模型将返回一个或多个预测的结果,并且还可以返回每个位置上备选标记的概率。
OpenAI官网给出的调用方式是:
openai.ChatCompletion.create()

其重要及常用参数如下:

代码调用方法如下:
completions_reponse = openai.Completion.create(
model="text-davinci-003",
prompt="test Completions api",
)
看一下返回结果:

5.2 Chat Completions基本调用方法
Chat Completions是一种专门用于聊天补全的语言模型,可以接受消息列表作为输入,并返回模型生成的消息作为输出。类似于使用的ChatGPT对话,可以进行角色扮演,回答一系列问题,其参数如下:

Chat模型中,通过给messages中的role参数设置不同的角色关键字,可以给当前输入赋予不同的能力,如以下代码:
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
# 通过给role设置为system,给Chat模型的此处对话赋予角色定位
{"role": "system", "content": "你是一位精通机器学习和自然语言处理的AI领域专家,具备20年相关经验"},
# 通过给role设置为user,告诉Chat模型此输入是这次会话的提问者
{"role": "user", "content": "我是一个小白,我想入门AI领域,我需要学习哪些知识"}
]
)
输出结果如下:

简单来说,上述代码调用Chat模型获取回答的思路就是:先让Chat模型扮演一位AI领域的专家这个角色,然后以这个角色身份来回答我要怎么学习AI这个问题
5.3 Chat Completions实现多轮对话的思路
我们更熟悉的ChatGPT在一段连续的对话中是有上下文记忆能力的,那其实ChatGPT背后使用的API也是gpt3.5和gpt4,对于直接使用代码调用来说,如果要进行多轮对话,和ChatGPT一样,思路就是:把上一个的输出也传递给gpt api,拼接起来共同作为输入给到gpt api,从而起到上下文记忆的能力,代码示例如下:
- Step 1:进行第一轮对话
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "你是一位精通机器学习和自然语言处理的AI领域专家,具备20年相关经验"},
{"role": "user", "content": "我是一个小白,我想入门AI领域,我需要学习哪些知识"}
]
)
看下模型的回复:

可以这样查看其内容:

- Step 2:将模型第一轮对话的回复与新输入拼接
在Chat模型的messages中添加模型第一轮的回复结果,也就是content中的内容,同时设置该条内容的role = assistant,代码如下:
completion_second = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "你是一位精通机器学习和自然语言处理的AI领域专家,具备20年相关经验"},
{"role": "user", "content": "我是一个小白,我想入门AI领域,我需要学习哪些知识"},
# 注意:这里通过设置role = assistant可以告诉Chat模型,这个输入是模型返回的答案
{"role": "assistant", "content": "\u4f5c\u4e3a\u4e00\u4e2a\u521d\u5b66\u8005\uff0c\u4f60\u53ef\u4ee5\u6309\u7167\u4ee5\u4e0b\u6b65\u9aa4\u6765\u5b66\u4e60AI\u9886\u57df\u7684\u77e5\u8bc6\uff1a\n\n1. \u5148\u4e86\u89e3\u673a\u5668\u5b66\u4e60\u7684\u57fa\u672c\u6982\u5ff5\uff1a\u673a\u5668\u5b66\u4e60\u662f\u4e00\u79cd\u8ba9\u8ba1\u7b97\u673a\u901a\u8fc7\u6570\u636e\u5b66\u4e60\u548c\u63d0\u9ad8\u6027\u80fd\u7684\u65b9\u6cd5\u3002\u4f60\u53ef\u4ee5\u5b66\u4e60\u673a\u5668\u5b66\u4e60\u7684\u57fa\u672c\u6982\u5ff5\uff0c\u5982\u76d1\u7763\u5b66\u4e60\u3001\u65e0\u76d1\u7763\u5b66\u4e60\u3001\u5f3a\u5316\u5b66\u4e60\u7b49\u3002\n\n2. \u5b66\u4e60Python\u7f16\u7a0b\u8bed\u8a00\uff1aPython\u662fAI\u9886\u57df\u5e38\u7528\u7684\u7f16\u7a0b\u8bed\u8a00\u4e4b\u4e00\uff0c\u5b66\u4e60Python\u5bf9\u4e8e\u8fdb\u884c\u6570\u636e\u5904\u7406\u548c\u7b97\u6cd5\u5b9e\u73b0\u975e\u5e38\u91cd\u8981\u3002\u4f60\u53ef\u4ee5\u901a\u8fc7\u5728\u7ebf\u6559\u7a0b\u3001\u89c6\u9891\u6559\u7a0b\u6216\u8005\u53c2\u52a0\u57f9\u8bad\u73ed\u6765\u5b66\u4e60Python\u3002\n\n3. \u638c\u63e1\u6570\u636e\u5904\u7406\u548c\u6570\u636e\u5206\u6790\u6280\u80fd\uff1aAI\u7684\u6838\u5fc3\u5728\u4e8e\u6570\u636e\uff0c\u638c\u63e1\u6570\u636e\u5904\u7406\u548c\u6570\u636e\u5206\u6790\u6280\u80fd\u662f\u975e\u5e38\u91cd\u8981\u7684\u3002\u4f60\u53ef\u4ee5\u5b66\u4e60\u6570\u636e\u6e05\u6d17\u3001\u6570\u636e\u53ef\u89c6\u5316\u3001\u6570\u636e\u7edf\u8ba1\u7b49\u76f8\u5173\u77e5\u8bc6\u3002\n\n4. \u5b66\u4e60\u673a\u5668\u5b66\u4e60\u7b97\u6cd5\uff1a\u5b66\u4e60\u4e00\u4e9b\u5e38\u7528\u7684\u673a\u5668\u5b66\u4e60\u7b97\u6cd5\uff0c\u5982\u7ebf\u6027\u56de\u5f52\u3001\u903b\u8f91\u56de\u5f52\u3001\u51b3\u7b56\u6811\u3001\u652f\u6301\u5411\u91cf\u673a\u3001\u795e\u7ecf\u7f51\u7edc\u7b49\u3002\u4e86\u89e3\u7b97\u6cd5\u7684\u539f\u7406\u548c\u9002\u7528\u573a\u666f\uff0c\u5e76\u5c1d\u8bd5\u5b9e\u73b0\u8fd9\u4e9b\u7b97\u6cd5\u3002\n\n5. \u5b66\u4e60\u6df1\u5ea6\u5b66\u4e60\uff1a\u6df1\u5ea6\u5b66\u4e60\u662fAI\u9886\u57df\u7684\u4e00\u4e2a\u70ed\u95e8\u65b9\u5411\uff0c\u5b83\u662f\u4e00\u79cd\u57fa\u4e8e\u795e\u7ecf\u7f51\u7edc\u7684\u5b66\u4e60\u65b9\u6cd5\u3002\u4f60\u53ef\u4ee5\u5b66\u4e60\u6df1\u5ea6\u5b66\u4e60\u7684\u57fa\u672c\u539f\u7406\u3001\u5e38\u7528\u7684\u795e\u7ecf\u7f51\u7edc\u67b6\u6784\u548c\u6df1\u5ea6\u5b66\u4e60\u6846\u67b6\u3002\n\n6. \u5b66\u4e60\u81ea\u7136\u8bed\u8a00\u5904\u7406\uff1a\u81ea\u7136\u8bed\u8a00\u5904\u7406\u662fAI\u9886\u57df\u7684\u4e00\u4e2a\u91cd\u8981\u65b9\u5411\uff0c\u5b83\u6d89\u53ca\u5230\u5bf9\u6587\u672c\u548c\u8bed\u8a00\u7684\u7406\u89e3\u548c\u5904\u7406\u3002\u4f60\u53ef\u4ee5\u5b66\u4e60\u6587\u672c\u5904\u7406\u3001\u8bcd\u5d4c\u5165\u3001\u60c5\u611f\u5206\u6790\u7b49\u76f8\u5173\u77e5\u8bc6\u3002\n\n7. \u5b9e\u8df5\u9879\u76ee\uff1a\u5e94\u7528\u6240\u5b66\u77e5\u8bc6\u8fdb\u884c\u5b9e\u8df5\u9879\u76ee\u662f\u5de9\u56fa\u548c\u63d0\u9ad8\u6280\u80fd\u7684\u91cd\u8981\u65b9\u5f0f\u3002\u4f60\u53ef\u4ee5\u53c2\u52a0\u4e00\u4e9b\u516c\u5f00\u7684\u673a\u5668\u5b66\u4e60\u7ade\u8d5b\uff0c\u6216\u8005\u81ea\u5df1\u627e\u4e00\u4e9b\u6570\u636e\u8fdb\u884c\u5b9e\u9645\u7684\u9879\u76ee\u5b9e\u8df5\u3002\n\n\u8bb0\u4f4f\uff0cAI\u9886\u57df\u662f\u4e00\u4e2a\u5feb\u901f\u53d1\u5c55\u7684\u9886\u57df\uff0c\u9700\u8981\u4e0d\u65ad\u5b66\u4e60\u548c\u5b9e\u8df5\u3002\u73b0\u5728\u6709\u5f88\u591a\u4f18\u8d28\u7684\u5728\u7ebf\u8d44\u6e90\u548c\u8bfe\u7a0b\u4f9b\u5b66\u4e60\u8005\u4f7f\u7528\uff0c\u4f60\u53ef\u4ee5\u9009\u62e9\u9002\u5408\u81ea\u5df1\u7684\u5b66\u4e60\u8def\u5f84\u548c\u65b9\u6cd5\u8fdb\u884c\u5b66\u4e60\u3002"},
{"role": "user", "content": "关于第5条深度学习方面,你帮我更加详细的介绍一下"}
]
)
看下模型的输出:

很明显能看出来,第二轮的回复是在第一轮对话的基础上继续进行的,这也提供了一种多轮对话的思路。
5.3 Images基本调用方法
Images模型可以根据给定的提示创建一个图像

ImagesAPI提供了三种与图片交互的方法:
1.根据文本提示从头开始创建图像
2.根据新文本提示创建现有图像的编辑
3.创建现有图像的变体
其参数如下:

看下代码:
openai.Image.create(
prompt="一只白色小猫\在野地上\奔跑",
n=1,
size='512x512'
)
输出如下:

点击链接可查看生成的图片,虽然有点难看,这需要提示工程,此处就做一个简单示例

还可以修改图片尺寸、编辑图片等,可以自己试一下,代码参考:
# 修改图片尺寸
from PIL import Image
def transfer(infile, outfile):
im = Image.open(infile)
reim=im.resize((512, 512))#宽*高
reim.save(outfile,dpi=(200.0,200.0)) ##200.0,200.0分别为想要设定的dpi值
if __name__ == '__main__':
infil=r"mask.png"
outfile=r"mask_512.png"
transfer(infil, outfile)
# edit 图片
openai.Image.create_edit(
image=open("小猫.png", "rb"),
mask=open("mask_512.png", "rb"),
prompt="小猫\趴着炕头上",
n=1,
size="512x512"
)
六:应用示例
6.1 创建一个编程问题解答助手
分享一个示例给大家提供一点思路,代码如下:
def programming_helper(question:str='Python中如何声明变量?'):
prompt = "你是一个编程问题解答助手,每当用户向你提出一个编程相关的问题,你都应尝试提供相关答案。" \
"如果问题太复杂或超出了你的知识范围,请回复 '建议查阅更详细的资料或论坛。'"
response = "Python中如何打印内容?" \
"\n\n你可以使用Python的print()函数来显示输出。例如:" \
"\n\nprint('你好,世界!') 将在屏幕上显示 '你好,世界!'。"
data = {
"model": "gpt-3.5-turbo-16k-0613",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 1,
"presence_penalty": 1,
"stream": False,
"messages": [
{"role": "system", "content": prompt},
{"role": "user", "content": "Python中如何打印内容?"},
{"role": "assistant", "content": response},
{"role": "user", "content": question}
]
}
return openai.ChatCompletion.create(**data)
# 示例
helper_response = programming_helper(question='Python中如何使用for循环?')
调用看一下输出:

这种方式是提示工程的Few-shot内容,此处不理解也没关系,后面的文章会讲到。
6.2 计算消耗的Tokens
调用API接口是按Tokens收费的,那么如何计算每次会话用了多少Tokens?
# !pip install tiktoken
import tiktoken
MODEL_NAME = "gpt-3.5-turbo-16k-0613"
encoder = tiktoken.encoding_for_model(MODEL_NAME)
def calculate_and_display_token_count(input_text:str):
encoded_text = encoder.encode(input_text)
token_count = len(encoded_text)
print(f"输入的文本: '{input_text}'")
print(f"对应的编码: {encoded_text}")
print(f"Token数量: {token_count}")
calculate_and_display_token_count(input_text='测试Token大小')
输出如下:
如果需要的话,还可以根据每个API的费用进一步添加费用计算等功能。
七、总结
本文明确如何获取和存储API keys,并进行连通性测试,确保正常使用。接着,介绍了OpenAI API的基本参数,尤其是针对GPT3.5和GPT 4的接口深入讲解了各种API的使用方法,包括Completions、Chat Completions以及Images的基本调用方式,并为Chat Completions实现多轮对话提供了思路。在应用示例部分,提供了如何创建编程问题解答助手以及如何计算消耗的Tokens。
感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
最后,给大家送上干货!建议大家点赞&收藏,Mark住别丢了。有高质量资料免费送!
1. 关于魔法,你需要知道的
2. 超全流程!OpenAI账户注册看这里!文章来源:https://www.toymoban.com/news/detail-674254.html
3. ChatGPT Plus 升级指南文章来源地址https://www.toymoban.com/news/detail-674254.html
到了这里,关于OpenAI 开发系列(四):掌握OpenAI API调用方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!