一、浏览器驱动下载
Selenium需要浏览器驱动程序才能与所选浏览器交互。例如,Firefox需要安装geckodriver。确保它在PATH中。
主流浏览器驱动下载地址如下:
| 浏览器 | 驱动名称 | 打开方式及注意事项 | 地址 |
|---|---|---|---|
| Chrome | chromedriver |
driver = webdriver.Chrome()下载浏览器对应版本的chromedriver.exe 一定要创建对象,不然打开会闪退!!! |
https://registry.npmmirror.com/binary.html?path=chromedriver |
| Firefox | geckodriver |
webdriver.Firefox()下载最新版本的geckodriver.exe |
https://github.com/mozilla/geckodriver/releases |
| Edge | MicrosoftWebDriver |
driver = webdriver.Edge()最好在官网下载对应版本的浏览器:https://www.microsoft.com/en-us/edge,然后下载浏览器对应版本的msedgedriver.exe 一定要创建对象,不然打开会闪退!!! windows10运行代码时:将msedgedriver.exe重命名为MicrosoftWebDriver.exe,不然运行程序会报错!!! windows11运行代码时:msedgedriver.exe不要重命名!!! |
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver |
| IE | IEDriverServer |
webdriver.Ie()下载selenium对应版本的IEDriverServer.exe |
https://registry.npmmirror.com/binary.html?path=selenium |
具体,可以查看:chromedriver、geckodriver、MicrosoftWebDriver、IEDriverServer和operadriver之间的恩怨纠葛
ps:最新版chromedriver的下载地址:
https://googlechromelabs.github.io/chrome-for-testing/#stable
二、selenium-python安装(打开网站、操作元素)
1.安装
pip install -U selenium
注:-U就是指定下载最新版本的selenium
2. 控制浏览器
2.1 打开浏览器
from selenium import webdriver
# 打开浏览器
driver = webdriver.Chrome()
或者,可以指定驱动路径:
driver = webdriver.Chrome(executable_path=r'D:\Program Files\Python36\chromedriver.exe')
关闭浏览器及其对应驱动:
driver.quit()
还可以通过上下文来控制其执行操作后自动关闭:
with webdriver.Chrome(executable_path='chromedriver.exe') as driver:
driver......
2.2 打开网站
driver.get('https://blog.csdn.net/testleaf/article/details/123269042')
延时3秒:
import time
time.sleep(3)
2.3 定位元素
传说中的八大元素定位方法:
driver.find_element_by_id() # 通过id属性定位(唯一);常用
driver.find_element_by_xpath() # 通过xpath表达式定位;常用
driver.find_element_by_class_name() # 通过类名定位;常用
driver.find_element_by_name() # 通过name属性定位
driver.find_element_by_tag_name() # 通过标签名定位
driver.find_element_by_css_selector() # 通过css选择器定位
driver.find_element_by_link_text() # 通过链接标签的text类容定位
driver.find_element_by_partial_link_text() # 通过匹配链接标签的text类容定位
上面的都是找到第一个元素,每一个方法都有对应多个元素的方法:
如:driver.find_elements_by_id()
示例1:
driver.find_element_by_id(“toolbar-search-input”)
示例2:
driver.find_element_by_name(“wd”)
2.4 操作元素
# 定位搜索框
element = driver.find_element_by_id("toolbar-search-input")
# 输入搜索内容
element.send_keys('web自动化框架:selenium入门')
# 定位搜索按钮
search_button = driver.find_element_by_id('toolbar-search-button')
# 点击搜索按钮
search_button.click()
三、网页解析(HTML、xpath)
1.HTML
HTML【Hyper Text Markup Language】:超文本标记语言,不是编程语言,用来描述网页的。也称为:网页的源码、html源码、html文档、document。
具体,可以查看:
网页的源码,html源码,html文档,document
HTML常用标签
HTML示例:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
#table {
border: 1px solid
}
.th {
font-size: 20px
}
</style>
</head>
<body>
<div>我是一个div标签</div>
<h1>我是一个大<span style="color:red">标签</span></h1>
<p></p>
<a href="https://blog.csdn.net/testleaf">testleaf</a>
<table id="table">
<thead>
<tr>
<th class="th aaa">字段1</th>
<th class="th">字段2</th>
<th class="th">字段3</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>2</td>
<td>3</td>
</tr>
</tbody>
</table>
<form action="">
<p>用户名: <input type="text"></p>
<p>密码:<input type="password"></p>
<p><input type="submit"></p>
</form>
</body>
</html>
2.xpath
xpath:一个解析html/xml的语言。
- 语法
- 选取节点
- nodename 选取此节点的所有子节点
- / 从根节点选取
- // 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置
- . 选取当前节点
- … 表示选取当前节点的父节点,如:
//div[@class="active"]/.. - @ 选取属性
- 案例
-
//div获取文档中的所有的div
-
- 谓语 用来查找特定的节点,或者包含指定值的节点
- 谓语被包裹在中括号中
//div[@class="active"]//div[@class="active" and @id="kw"]//div[@class="active" or @id="kw"]//div[@class="active"]/span[last()]
- 轴 用来查找相对于当前节点的节点
- 使用语法 轴名称::节点名称[谓语]
- ancestor 选取当前节点的所有父辈节点
- parent 选取当前节点的父节点
- 如:
//div[@class="active"]/child::book - …详见 https://www.w3school.com.cn/xpath/xpath_axes.asp
- 函数
- text() 元素的text内容
//li[text()="强烈推荐"]
- contains(@属性名/text(), value)包含的内容
//li[contains(@class, "ls")]
- text() 元素的text内容
- 选取节点
在浏览器中进行验证:
$x('//div')

四、selenium基本操作
Pycharm-Terminal操作:
IPYTHON
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.quit()
exit()

浏览器-Console操作:
window.scrollTo(0,100)

1、元素定位八种方法
传说中的八大元素定位方法:
driver.find_element_by_id() # 通过id属性定位(唯一);常用
driver.find_element_by_xpath() # 通过xpath表达式定位;常用
driver.find_element_by_class_name() # 通过类名定位;常用
driver.find_element_by_name() # 通过name属性定位
driver.find_element_by_tag_name() # 通过标签名定位
driver.find_element_by_css_selector() # 通过css选择器定位
driver.find_element_by_link_text() # 通过链接标签的text类容定位
driver.find_element_by_partial_link_text() # 通过匹配链接标签的text类容定位
以上方法只会返回匹配到的第一个元素;
返回的是 selenium.webdriver.remote.webelement.WebElement的对象;
返回多个元素在element后加s即可,例如:driver.find_elements_by_xpath(),使用时要小心;
凡是elements的方法返回的是列表;
from selenium import webdriver
driver = webdriver.Chrome()
# 打开百度页面
driver.get('https://www.baidu.com')
# 1. 获取搜索框
search_input = driver.find_element_by_id('kw')
print(type(search_input))
print('1.搜索框的name属性值=', search_input.get_attribute('name'))
# 2. 搜索按钮
search_btn = driver.find_element_by_xpath('//input[@value="百度一下"]')
print('2.搜索按钮的id=', search_btn.get_attribute('id'))
# 3. 百度logo
logo = driver.find_element_by_class_name('index-logo-src')
print('3.百度logo的src=', logo.get_attribute('src'))
# 4. 通过name属性定位搜索框
search_input_by_name = driver.find_element_by_name('wd')
print('4.搜索框的id=', search_input_by_name.get_attribute('id'))
# 5. 热搜榜中的链接
hot_ul = driver.find_element_by_xpath('//ul[@id="hotsearch-content-wrapper"]')
# hot_ul = driver.find_element_by_xpath('//ul[@text()="热榜"]')
hot_a_s = hot_ul.find_element_by_tag_name('a')
print('5.热搜榜第一的标题是:', hot_a_s.text)
# 6. 通过css选择器定位搜索框
search_input_by_css = driver.find_element_by_css_selector('#kw')
print('6.搜索框的name=', search_input_by_css.get_attribute('name'))
# 7. 新闻栏目
el_a = driver.find_element_by_link_text('新闻')
print('7.新闻栏目的url=', el_a.get_attribute('href'))
# 8. 通过部分text匹配新闻栏目
el_a1 = driver.find_element_by_partial_link_text('新')
print('8.新闻栏目的url=', el_a1.get_attribute('href'))
driver.quit()
2、元素动态定位
问题:元素的定位方式不确定,可能是id,可能是xpath,需要通过不同的方式动态指定定位方法;
办法:加判断语句,不需要我们写,selenium底层定位就是这么做的;
driver.find_element(by,value)
driver.find_elements(by,value)
by: 定位方式
value: 定位表达式
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 打开百度页面
driver.get('https://www.baidu.com')
id_loc = 'kw'
xpath_loc = '//input[@id="kw"]'
e1 = driver.find_element(By.ID, id_loc)
# send_keys往输入框输入文本
e1.send_keys('我通过id定位')
time.sleep(3)
# e2 = driver.find_element(By.XPATH, xpath_loc)
e2 = driver.find_element('xpath', xpath_loc)
e2.clear() # 清空原有内容
e2.send_keys('我通过xpath定位')
time.sleep(3)
driver.quit()
3、iframe切换
当页面中包含iframe时,不能直接操作iframe中的元素,需要先切换进iframe才行;
selenium通过driver.switch_to.frame(frame_reference)来切换;
selenium切换iframe有三种方式:
- 1.通过webelement:
- 使用webelement进行切换是最灵活的选择,先定位到iframe然后切换到它;
- 2.通过name或id:
- iframe一般都会有id或name属性,则可以使用该属性进行切换,如果name或id在页面上不唯一,name将切换到找到的第一个;
- 3.通过iframe在页面中的索引进行切换(从0开始):
- 在浏览器console调试工具中使用
window.ampInaboxIframes可以查询当前页面中的iframe;退出iframe:driver.switch_to.default_content();
- 在浏览器console调试工具中使用
import time
from selenium import webdriver
# 使用with语句进行上下文管理
# 异常时也会关闭浏览器驱动
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=eg_html_form_radio')
# 切换iframe
# 1. webelement的方式
# 先获取到iframe
iframe = driver.find_element_by_id('iframeResult')
# 再切换到
driver.switch_to.frame(iframe)
# 2. name/id的方式
# 直接通过name/id切换
driver.switch_to.frame('iframeResult')
# 3. 使用索引
# 切换到第二个iframe
time.sleep(1)
driver.switch_to.frame(1)
# 找到female单选框
female = driver.find_element_by_xpath('//input[@value="female"]')
print(female)
# 4. 离开iframe,回到主页面
driver.switch_to.default_content()
driver.find_element_by_xpath('//a[text()="运行代码"]')
4、填充表单_填充文本框
import time
from selenium import webdriver
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
# 搜索框定位
search_input = driver.find_element_by_id('kw')
# element.send_keys(string)输入文本
# 所有可输入的标签都适用
search_input.send_keys('软件测试')
# 搜索按钮定位
search_btn = driver.find_element_by_xpath('//input[@value="百度一下"]')
# 点击
# element.click()点击
search_btn.click()
time.sleep(3)
5、填充表单_单选按钮
import time
from selenium import webdriver
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=eg_html_form_radio')
# 切换iframe
iframe = driver.find_element_by_id('iframeResult')
driver.switch_to.frame(iframe)
# 找到female单选框
female = driver.find_element_by_xpath('//input[@value="female"]')
# 在元素上点击
female.click() # 选中
time.sleep(5)
6、填充表单_下拉列表
下拉框有两种处理方法:
(1)直接定位到要选中的option选项,然后点击
(2)通过selenium.webdriver.support.ui.Select类
import time
from selenium import webdriver
from selenium.webdriver.support.ui import Select
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=eg_html_elements_select')
# 切换iframe
iframe = driver.find_element_by_id('iframeResult')
driver.switch_to.frame(iframe)
# 找到audi选项
# 1. 通过option直接操作
option = driver.find_element_by_xpath('//option[@value="audi"]')
option.click()
time.sleep(1)
# 2. 通过select类
# 找到select
select = Select(driver.find_element_by_xpath('//select[@name="cars"]'))
#
# # 选中索引为1的选项,索引从0开始
select.select_by_index(1)
time.sleep(1)
#
# # 选中value等于audi的选项
select.select_by_value('audi')
time.sleep(1)
#
# # 选中option的文本为Volvo的选项
select.select_by_visible_text('Volvo')
time.sleep(3)
7、切换窗口和标签页
webdriver 不区分窗口和标签页。打开一个新的标签页或者窗口,selenium会使用窗口句柄来处理它。
每个窗口都有一个唯一的标识符,该标识符在单个会话中保持持久性。
(1)获取当前窗口句柄:driver.current_window_handle;
(2)切换窗口或标签页:通过循环遍历的方式来切换;
import time
from selenium import webdriver
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
# 找到搜索框
search_input = driver.find_element_by_id('kw')
search_input.send_keys('图片')
# 点击搜索按钮
driver.find_element_by_id('su').click()
time.sleep(1)
# 获取原窗口的handle
original_window = driver.current_window_handle
print('当前窗口句柄', original_window)
print('窗口的title', driver.title)
# 选取第一个结果并点击
driver.find_element_by_xpath('//div[@id="3001"]//a').click()
# time.sleep(1)
for handle in driver.window_handles:
if handle != original_window:
# 切换到新窗口
driver.switch_to.window(handle)
break
# 打印当前窗口句柄
print('新打开的搜索页面句柄', driver.current_window_handle)
print('新打开的页面的title', driver.title)
time.sleep(5)
8、显式等待
浏览器渲染页面的时候需要时间,如果没有渲染完成就对元素进行定位将会找不到到该元素;
所以需要加延时进行等待,有三种等待方式:
(1)time.sleep()
前面已经反复使用了;等待时间固定,不稳定;等待时间多半不确定;
(2)显式等待
显式等待就是在元素操作前循环判断操作的条件是否满足,满足后再操作;
selenium通过selenium.webdriver.support.ui.WebDriverWait类的对象来实现显式等待;webDriverWait类实例化时可以接收3个参数:
- driver: webdriver对象
- timeout:超时时间,最多等待多少秒
- poll_frequency: 检查频率,默认0.5秒
until方法接受1个参数:
- conditions:条件在
selenium.webdriver.support.expected_conditions模块中;
常见条件:
presence_of_element_located:元素存在于dom中
visibility_of_element_located:元素可见
element_to_be_clickable:元素可点击
element_to_be_selected:元素可选择
实例化条件需要传入一个定位参数,是一个二元元组:(by, loc_expression)
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import selenium.webdriver.support.expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
# 找到搜索框
search_input = driver.find_element_by_id('kw')
search_input.send_keys('图片')
# 点击搜索按钮
driver.find_element_by_id('su').click()
# 获取原窗口的id
original_window = driver.current_window_handle
print('当前窗口句柄', original_window)
print('窗口的title', driver.title)
# 选取第一个结果并点击
#
# WebDriverWait(driver, timeout=3).until(
# EC.visibility_of_element_located((By.XPATH, '//div[@id="3001"]//a'))
# ).click()
s_time = time.time()
btn = WebDriverWait(driver, timeout=3).until(
EC.visibility_of_element_located((By.ID, '3001'))
)
btn.click()
e_time = time.time()
print(e_time-s_time)
# WebDriverWait(driver, timeout=3).until(
# EC.visibility_of_element_located(('id', '3001'))
# ).click()
# 会等待id为3001的元素可见,timeout=3表示最多等待3秒钟,超时就抛出异常
# driver.find_element_by_xpath('//div[@id="3001"]//a').click()
# time.sleep(1)
for handle in driver.window_handles:
if handle != original_window:
# 切换到新窗口
driver.switch_to.window(handle)
break
# 打印当前窗口句柄
print('新打开的搜索页面句柄', driver.current_window_handle)
print('新打开的页面的title', driver.title)
time.sleep(5)
9、隐式等待
(3)隐式等待
隐式等待本质上是设置了一个全局等待时间,WebDriver在试图查找任何元素时都会轮询一定时间,默认情况下隐式等待是禁用的。
警告:不要混用隐式等待和显示等待,这样会导致不可预测的等待时间。
例如:隐式等待设置10秒,显式等待设置15秒,可能导致在20秒后发生超时;
隐式等待是告诉WebDriver如果在查找一个或多个不是立即可用的元素时轮询DOM一段时间。默认设置为0,表示禁用。一旦设置好,隐式等待就会被设置为会话的生命周期。
import time
from selenium import webdriver
with webdriver.Chrome() as driver:
# 设置隐式等待5秒
driver.implicitly_wait(5)
driver.get('https://www.baidu.com')
# 找到搜索框
search_input = driver.find_element_by_id('kw')
search_input.send_keys('图片')
# 点击搜索按钮
driver.find_element_by_id('su').click()
# 获取原窗口的id
original_window = driver.current_window_handle
print('当前窗口句柄', original_window)
print('窗口的title', driver.title)
# 选取第一个结果并点击
driver.find_element_by_xpath('//div[@id="3001"]//a').click()
for handle in driver.window_handles:
if handle != original_window:
# 切换到新窗口
driver.switch_to.window(handle)
break
# 打印当前窗口句柄
print('新打开的搜索页面句柄', driver.current_window_handle)
print('新打开的页面的title', driver.title)
time.sleep(5)
10、警告框
WebDriver提供了一个API,用于处理JavaScript提供的三种类型的原生弹窗消息
(1)Alerts警告框
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=js_alert')
driver.switch_to.frame('iframeResult')
button = WebDriverWait(driver, timeout=3).until(
EC.visibility_of_element_located(('xpath', '//button')))
# 有时候需要结合sleep来处理
# time.sleep(1)
button.click()
# time.sleep(3)
# 等待alert弹出
alert = WebDriverWait(driver, timeout=3).until(EC.alert_is_present())
# time.sleep(1)
# alert = driver.switch_to.alert
# 获取弹出框文本
text = alert.text
print(text)
time.sleep(1)
# # 确认
alert.accept()
time.sleep(1)
11、confirm确认框
(2) confirm确认框
与警告框不同,确认框还有取消按钮;
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=js_confirm')
driver.switch_to.frame('iframeResult')
button = WebDriverWait(driver, timeout=3).until(
EC.visibility_of_element_located(('xpath', '//button')))
button.click()
# # 等待confirm弹出
WebDriverWait(driver, timeout=3).until(EC.alert_is_present())
#
# # 获取alert
alert = driver.switch_to.alert
#
# # 获取弹出框文本
text = alert.text
print(text)
time.sleep(2)
# # 取消
# 点击取消后 当前的alert对象就会被销毁
alert.dismiss()
# alert.accept() 确认
time.sleep(2)
12、prompt提示框
(3)prompt提示框
还可以输入文本;
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get('https://www.w3school.com.cn/tiy/t.asp?f=js_prompt')
driver.switch_to.frame('iframeResult')
button = WebDriverWait(driver, timeout=3).until(
EC.visibility_of_element_located(('xpath', '//button')))
# 避免js没有绑定出现意外问题,加一秒延时
time.sleep(1)
button.click()
# 等待alert弹出
WebDriverWait(driver, timeout=3).until(EC.alert_is_present())
# 获取alert
alert = driver.switch_to.alert
# 输入信息
alert.send_keys('testleaf')
time.sleep(3)
# 确认
alert.accept()
# alert.dismiss() 取消
time.sleep(3)
13、鼠标操作动作链
鼠标是通过使用底层接口执行的,需要调用ActionChains对象来执行对应的方法。
(1)clickAndHold:它将移动到该元素,然后在给定元素的中间单击(不释放);
(2)contextClick:此方法首先将鼠标移动到元素的位置, 然后在给定元素执行上下文点击(右键单击);
(3)doubleClick:它将移动到该元素, 并在给定元素的中间双击;
(4)moveToElement:此方法将鼠标移到元素的中间. 执行此操作时, 该元素也会滚动到视图中;
(5)moveByOffset:此方法将鼠标从其当前位置(或0,0)移动给定的偏移量. 如果坐标在视图窗口之外, 则鼠标最终将在浏览器窗口之外;
(6)dragAndDrop:此方法首先在源元素上单击并按住,然后移动到目标元素的位置后释放鼠标;
(7)release:此操作将释放按下的鼠标左键. 如果WebElement转移了, 它将释放给定WebElement上按下的鼠标左键;
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get(r'file://D:\project\action.html')
div = WebDriverWait(driver, timeout=3).until(EC.visibility_of_element_located(('xpath', '//div[@οnmοuseοver="mOver(this)"]')))
# 移动到指定元素 move_to_element
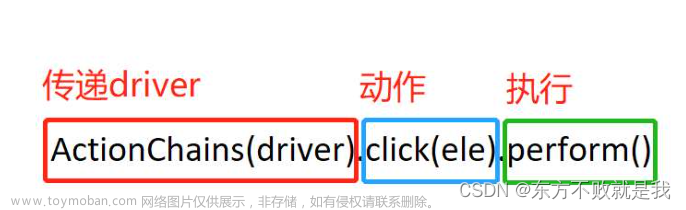
webdriver.ActionChains(driver).move_to_element(div).perform()
time.sleep(2)
# 移开多大位置x,y move_by_offset
webdriver.ActionChains(driver).move_by_offset(xoffset=500, yoffset=500).perform()
time.sleep(2)
# 点住不放 click_and_hold
div = driver.find_element_by_xpath('//div[@οnmοusedοwn="mDown(this)"]')
webdriver.ActionChains(driver).click_and_hold(div).perform()
time.sleep(2)
# 松开鼠标 release
webdriver.ActionChains(driver).release(div).perform()
time.sleep(2)
# double_click 双击
button = driver.find_element_by_xpath('//button[@ondblclick]')
webdriver.ActionChains(driver).double_click(button).perform()
time.sleep(2)
# drag 将div1拖拽到div2上
div1 = driver.find_element_by_id('draggable')
div2 = driver.find_element_by_id('droppable')
webdriver.ActionChains(driver).drag_and_drop(div1, div2).perform()
time.sleep(3)
# contextClick 点击鼠标右键
div = driver.find_element_by_xpath('//div[@οnmοusedοwn="whichButton(event)"]')
webdriver.ActionChains(driver).context_click(div).perform()
time.sleep(2)
14、执行js代码_滚动1
selenium执行js有几个方法,这里我们使用最常用的方法execute_script;
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get('https://image.baidu.com')
search_input = WebDriverWait(driver, 3).until(EC.visibility_of_element_located(('id', 'kw')))
search_input.send_keys('软件测试')
WebDriverWait(driver, 3).until(EC.element_to_be_clickable(('xpath', '//input[@value="百度一下"]'))).click()
time.sleep(3)
# 滚动到(0px,100px)的位置
driver.execute_script("window.scrollTo(0,100)")
time.sleep(1)
driver.execute_script("window.scrollTo(0,200)")
time.sleep(1)
driver.execute_script("window.scrollTo(0,300)")
time.sleep(3)
# 移动到底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(3)
# 移动到顶部
driver.execute_script("window.scrollTo(0,0)")
time.sleep(3)
15、执行js代码_滚动2
selenium执行js有几个方法,这里我们使用最常用的方法execute_script;
执行js时,还可以传递参数给js脚本;
下面的案例:
打开页面,并滚动到指定的元素可见为止;
下面的代码 div 被传递给了arguments,通过切片的方式可以取出;
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get(r'file://D:\project\scroll.html')
time.sleep(2)
div = driver.find_element_by_xpath('//div')
# 移动到元素的底端与当前窗口的底部对齐
driver.execute_script("arguments[0].scrollIntoView(false);", div)
time.sleep(2)
# 移动到元素的顶端与当前窗口的顶端对齐
driver.execute_script("arguments[0].scrollIntoView();", div)
time.sleep(2)
16、上传操作_input上传
selenium只支持input元素的上传,直接使用send_keys将文件绝对地址写入元素即可;
import time
from selenium import webdriver
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
span = driver.find_element_by_xpath('//span[@class="soutu-btn"]')
span.click()
time.sleep(1)
input = driver.find_element_by_xpath('//input[@class="upload-pic"]')
input.send_keys(r'D:\project\find.jpg')
# 有可能还需要提交的操作,百度是不需要
time.sleep(10)
17、上传操作_非input上传_pywinauto
很多时候页面不是使用input来进行文件上传,这是就需要通过其他第三方包来操作系统界面;
(1)pywinauto
缺点: 只能在windwows上使用;
优点:可以选择多个文件,路径中有中文也可以;
import time
from selenium import webdriver
from pywinauto.keyboard import send_keys
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
span = driver.find_element_by_xpath('//span[@class="soutu-btn"]')
span.click()
time.sleep(1)
# select_span = driver.find_element_by_xpath('//span[text()="选择文件"]')
select_span = driver.find_element_by_xpath('//div[@class="upload-wrap"]')
# 点击打开选择文件窗口
select_span.click()
time.sleep(3)
# 选择文件
send_keys(r'D:\project\find.jpg')
time.sleep(1)
# # 选择确定
send_keys('{ENTER}')
time.sleep(10)
18、上传操作_非input上传_pyautogui
很多时候页面不是使用input来进行文件上传,这里就需要通过其他第三方包来操作系统界面;
(2)pyautogui
缺点: 只能选择一个文件,文件路径有中文会出问题;
优点:跨平台(windows,mac,linux);
import time
from selenium import webdriver
import pyautogui
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
span = driver.find_element_by_xpath('//span[@class="soutu-btn"]')
span.click()
time.sleep(1)
# select_span = driver.find_element_by_xpath('//span[text()="选择文件"]')
select_span = driver.find_element_by_xpath('//div[@class="upload-wrap"]')
# 点击打开选择文件窗口
select_span.click()
time.sleep(3)
# 选择文件
pyautogui.write(r"D:\project\find.jpg")
time.sleep(1)
# 选择确定
pyautogui.press('enter', 2)
time.sleep(10)
五、selenium调整窗口大小
selenium调整窗口到指定大小:
driver.set_window_size(900,1000)
浏览器最大化:
driver.maximize_window()
六、判断元素是否允许被操作
driver.find_element_by_name("XXX").is_enabled() # 是否可以编辑,或者按钮是否可以点击
driver.find_element_by_name("XXX").is_displayed() # 判断元素是否显示
element=driver.find_element_by_name("XXX").is_selected() # 判断元素是否选中状态
七、获取某个元素的html
driver.find_element_by_id('XXX').get_attribute('innerHTML')
八、其他问题
1、svg定位
问题描述:
使用xpath方法对svg下元素进行定位,会发现无法定位到svg下的元素:
driver.find_element(xpath,"/html/body/div[19]/svg")
解决方法1【错误】:
从svg元素开始,下面的元素都要以*[name()=‘svg element’] 这种形式进行编写
driver.find_element(xpath,"/html/body/div[19]/*[name()='svg']/*[name()='path']")
会发现仍然定位不到;
解决办法2【正确】:
绝对路径的话,*[name()='svg']前面得加双斜杠,不然定位不到:
driver.find_element(xpath,"/html/body/div[19]//*[name()='svg']")
相对路径的话,*[name()='svg']前就不用加双斜杠,只用单斜杠:
driver.find_element(xpath,"//*[@id='userinfo']/*[name()='svg']/*[name()='use']")
2、处理chrome显示通知弹框
使用chrome打开weibo.com会出现以下界面的弹出框:
这东西不属于页面alert弹框,而是属于浏览器的设置项。
要关掉它,需要对浏览器进行属于配置。具体见下面脚本:
from selenium import webdriver
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values':{
'notifications':2
}
}
options.add_experimental_option('prefs',prefs)
driver = webdriver.Chrome(options = options)
driver.get("https://blog.csdn.net/testleaf/article/details/123269042")
3、获取元素的文本
①element.text
②get_attribute(“textContent”)
优点:可以获取隐藏元素的文本
缺点:IE不支持;获取有些元素的文本时,结果中带有空字符串;(没有尝试过)
③get_attribute("innerText")
优点:可以获取隐藏元素的文本
缺点:FireFox不支持;(每个博客能搜到的都说这个缺点,但实际操作发现可以获取到每次所需的文本)
4、切换网址
直接进行切换就可以了,如下:文章来源:https://www.toymoban.com/news/detail-674801.html
driver.get('https://blog.csdn.net/testleaf/article/details/123269042')
time.sleep(2)
driver.get('https://blog.csdn.net/testleaf/article/details/123302863')
5、find_element_by_xpath()被弃用解决方案
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome() #启动chromedriver
driver.get('http://www.baidu.com') #打开http://www.baidu.com
driver.find_element(By.XPATH,'//div[@class="detail-item-ctn"][1]').click() #点击按钮
免责声明:
1.编写此文是为了更好地学习selenium的使用,如果损害了有关人的利益,请联系删除;
2.如果文中描述欠妥,请在评论中进行指正;
3.文字编写不易,若感觉有用,点赞收藏关注会让博主很开心哦;
4.此外,本文支持任何形式的转载,转载请注明出处,非常感谢!!!
本文源自:https://blog.csdn.net/testleaf/article/details/123269042文章来源地址https://www.toymoban.com/news/detail-674801.html
到了这里,关于web自动化框架:selenium学习使用操作大全(Python版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!