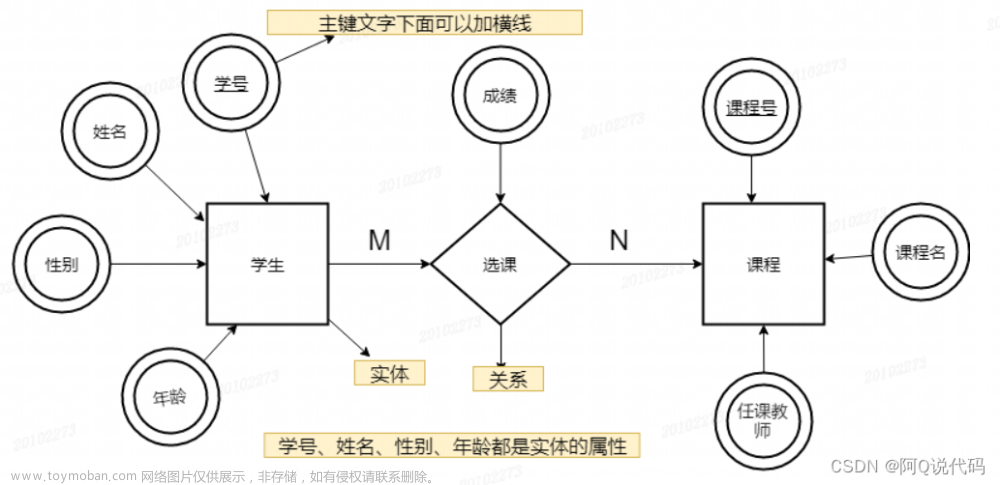
索引
索引分类
mysql有普通索引、空间索引、主键索引、唯一索引、组合索引和全文索引。
- 普通索引:使用字段关键字建立的索引,主要目的是提高查询速度。
- 空间索引:前只有MyISAM引擎支持,用于空间类型的字段,不允许为空。
- 唯一索引:索引列中的值必须是唯一的,但允许为空值。
- 主键索引:是一种特殊的唯一索引,不允许有空值
- 组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,遵循最左前缀集合原则。
- 全文索引:一种特殊类型的索引,主要用于全文搜索。
索引未命中的原因
- 没有查询条件,或查询条件中没有索引
- 条件中有or,并且不是所有的条件都有索引
- like左匹配或者int字段
- 索引列是字符串,但是sql中未加引号
- 条件中在索引列使用函数
- 采用not in/not exist查询
- B-tree索引 is null不走索引,is not null才走索引
- 联合索引不满足最左原则
性能调优命令Explain
explain用于解析sql的执行计划,执行计划是MySQL为了执行查询语句而制定的优化方案,包括数据的读取顺序、表的访问方式、索引的使用情况等信息。
以下是使用EXPLAIN指令的基本语法:
EXPLAIN SELECT column1, column2 FROM table_name WHERE condition;
使用EXPLAIN指令后,MySQL会返回一个表格,其中包含以下信息:
- id:查询的标识符,id越大的越先执行。
- select_type:查询的类型,如SIMPLE、PRIMARY、SUBQUERY等。
- table:被查询的表名。
- partitions:被查询的分区信息。
- type:访问表的方式,如ALL、INDEX、RANGE等。
– ALL: 全表扫描;
– INDEX: 索引全扫描。
– range: 范围扫描。
– ref: 使用非唯一索引,或唯一索引的前缀扫描,返回匹配某个单独值得记录行。
– eq_ref: 多表连接中使用,主键或唯一建作为关联条件。
– const/system: 单表中最多有一个匹配行。主要用于比较primary key 或unique索引,因为数据都是唯一的,所以性能最优。
– null: 不用访问表或索引,直接就能得到结果。 - possible_keys:可能使用的索引。
- key:实际使用的索引。
- key_len:使用的索引长度。
- ref:用于比较的值。
- rows:MySQL估计需要读取的行数,数值越大越不好,说明没用好索引。
- filtered:MySQL估计返回的行数占总行数的比例。
- Extra:附加信息,如使用了临时表、文件排序等。
回表
回表指当查询条件(where条件和返回列)不能被索引索引锁覆盖时,需要访问索引中没有的数据,需要通过回表技术访问数据所在页,获取具体得数据。
与回表相对应的是覆盖查询,即查询条件能够被索引所覆盖,不需要回表查询数据,这样查询效率会更高。因此,在设计数据库时,需要根据具体的情况选择合适的索引策略,以提高查询性能。
mysql性能优化
- 优化sql
1.1 使用explain命令解析sql执行计划
1.2 尽量命中索引
1.3 合理设计索引,不是越多越好 - 优化表结构
2.1 经常查询的表尽量避免过大。
2.2 多余常用的字段尽量冗余,避免大表进行联合查询。 - 分库分表进行表瘦身
3.1 水平分库:以字段为依据,将一个库中的数据进行拆分到多个库中。比如按年份进行分库。
3.2 水平分表:以字段为依据,将一个表中的数据进行才分到多张表中。
3.3 垂直分库:以表为依据,按业务将表分到不同的库中。
3.4 垂直分表:以字段为依据,按字段中的活跃度将表中的字段拆分到不同的表,比如主表和扩展表。
事务
四大特性
事务的四大特性ACID,ACID是原子性(Atomicity [ˌætəˈmɪsəti])、一致性(Consistency [kənˈsɪstənsi])、隔离性(Isolation [ˌaɪsəˈleɪʃn])、持久性(Durability [dərəˈbɪlɪti])的缩写,是数据库事务的基本属性,用于确保事务的可靠性和一致性。
- 原子性:事务是一个原子操作单元,事务的执行要么全部成功,要么全部失败回滚。
– 由undolog实现 - 一致性:事务必须保证数据库从一个状态改变为另一个状态,并保持数据的一致性和完整性。
– 由原子性、隔离性、持久性共同实现 - 隔离性:多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
– 锁+MVCC - 持久性:一旦事务提交,对数据库的修改是永久的,即使系统崩溃或故障也能保持。
– 由redolog实现
事务隔离级别
MySQL数据库的事务隔离级别有四个,分别是:读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
- 读未提交:事务中的修改,即使未提交,对其他事务也是可见的。
- 读提交:事务只能看见已经提交的数据修改,会产生不可重复读。
- 可重复读:同一事务中多次读取数据的结果是一致的,但是并发的事务可能会对数据产生影响,会导致导致 幻读。
- 串行化:最严格的事务隔离级别,通过锁机制实现,确保事务串行化顺序执行,能避免幻读,但是效率低下。
mysql默认的事务隔离级别是可重复读(Repeatable Read)。
幻读
幻读的本质,如果事务中都是快照读,那么不会产生幻读,但是快照读和当前读一起使用的时候就会产生幻读。
MySQL中,当前读和快照读都是读取数据的方式,具体含义如下:
- 当前读:也称锁定读(locking read),通过对读取到的数据(索引记录)加锁来保证数据一致性,当前读会对所有扫描到的索引记录进行加锁,无论该记录是否满足WHERE条件都会被加锁1。
- 快照读:MySQL使用MVCC(Multiversion Concurrency Control)机制来保证被读取到数据的一致性,读取数据时不需要对数据进行加锁,且快照读不会被其他事物阻塞1。
在读提交和可重复读两种事务隔离级别下,普通的SELECT操作使用"快照读",不会对数据加锁,也不会被事务阻塞。
设置事务隔离级别
在MySQL中,可以使用以下SQL语句设置事务的隔离级别:
SET TRANSACTION ISOLATION LEVEL <isolation_level>;
存储引擎
mysql主要的存储引擎是MyISAM和InnoDB,默认使用的是InnoDB引擎。
使用以下命令查询当前使用的存储引擎:
SHOW VARIABLES LIKE 'storage_engine';
使用以下命令查询所有存储引擎:
SHOW ENGINES;
- MyISAM:不支持事务、不支持外键,索引采用的是非聚簇索引。
- InnoDB:提供了具有提交、回滚等事务功能,支持自动增长列,外键等功能。采用聚簇索引,索引和数据是存储在同一个文件下。
聚簇索引和非聚簇索引
聚簇索引
- 数据挂载在主索引的叶子节点上。
- 辅助索引的叶子节点指向主索引。
非聚簇索引
主索引和辅助索引的叶子节点指向数据存储的位置。
最左前缀结合原则
最左前缀原则就是使用联合索引时,查询条件需要遵循索引中列的顺序,从左到右进行匹配。
在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。当创建(a,b,c)复合索引时,想要索引生效的话,只能使用a、ab、ac和abc四种组合。
select a,b,c from table where a = 'v' ; #索引生效,使用索引a
select a,b,c from table where a = 'v' and b='v1'; #索引生效,使用索引ab
select a,b,c from table where a = 'v' and c='v3'; #索引生效,使用索引a
select a,b,c from table where a = 'v' and b='v1' and c='v3'; #索引生效,使用索引abc
注意:实践证明,where后面的条件顺序并不会影响索引的命中条件,即 ba和ab效果一致。原因是mysql在执行前会对where语句进行自行调优。
全文索引
MySQL的全文索引是一种用于搜索文本内容的索引方式,它可以通过分析文本内容中的关键词,帮助提高检索效率。
MySQL使用全文索引主要分为以下步骤:
创建全文索引:
ALTER TABLE table_name ADD FULLTEXT(column_name);
创建全文索引的查询:
SELECT * FROM table_name WHERE MATCH(column_name) AGAINST('keywords');
在查询语句中,column_name是要查询的列名,keywords是要搜索的关键词。
需要注意的是,只有MyISAM和InnoDB存储引擎支持全文索引,其中MyISAM引擎默认全文索引,InnoDB引擎需要手动创建全文索引。全文索引的查询还需要考虑相关性和阈值,即匹配结果太少可能会查不到结果。
日志
slowlog
设置具体的时间,把执行超时的sql记录,在日志文件中,方便进行优化调整。
binlog
主要用来进行数据库之间的主从同步
errorlog
记录数据库进程中的一些错误信息
relaylog
在slaver机器中暂存同步过来的binlog数据
undolog
回滚日志,记录的是数据的历史版本信息,用来保证原子性和MVCC
redolog
前滚日志,将数据从内存到磁盘的操作进行顺序读写到redolog,当需要进行数据恢复的时候通过redolog进行数据恢复。
两阶段提交
DML操作日志写入redolog和binlog的流程如下:
1.将日志写入redolog,并标记状态为(prepare);
2.将日志写入binlog;
3.修改redolog里面的状态为commit。
当日志写入第一步成功后宕机,重启进行数据恢复时,在redolog中看到记录是prepare的,于是到binlog中查找有无与之对应的数据,如果没有,则将redolog中的该条记录删除,如果有则将状态改为commit。这样就保证了redolog和binlog中的数据一致性。
MVCC
MVCC(Multi-version concurrency controll),多版本并发控制,用来解决数据并发场景中并发读写问题的。
并发场景下,多线程共同读写会有线程安全问题,会产生脏读、幻读、不可重复读的问题。多线程共同写会产生丢失更新的问题。
MVCC底层实现由三部分组成:隐藏字段、undolog、readview。文章来源:https://www.toymoban.com/news/detail-675619.html
- 隐藏字段:对于用户不可见;
– DB_TXR_ID:创建这条记录或最后一次修改该记录的事务的id值。
– DB_ROLL_PTR: 回滚指针,指向的是上一个数据的版本。
– DB_ROW_ID:隐藏主键,如果数据表没有设置主键,会生成一个6个字节的rowid作为隐藏主键。 - undolog:回滚日志,表示在insert、delete、update操作产生的方便回滚的日志。undolog中存储的是通过DB_ROOLL_PTR链接起来的记录历史版本的一个链表,链表会有专门的线程负责清理。
- readview:读视图是在事务进行快照读的时候产生的读视图,保存的并不是数据的信息,而是事务的相关信息。包含以下三个部分:
– trx_list: 在生成readview时刻,当前系统正在活跃的事务列表。
– up_limit_id:当前活跃列表中事务id最小的值。
– low_limit_id: 系统尚未分配的笑一个事务id。
数据是否可读通过可见性算法进行判断,可见性算法的判断依据是readView+DB_TXR_ID,事务通过控制readView的生成时机来控制数据的是否可读。文章来源地址https://www.toymoban.com/news/detail-675619.html
到了这里,关于Mysql知识梳理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!