架构原理
一、高性能读写架构原理——顺序写+零拷贝
首先了解两个专业术语,研究kafka这个东西,你必须得搞清楚这两个概念,吞吐量,延迟。
写数据请求发送给kafka一直到他处理成功,你认为写请求成功,假设是1毫秒,这个就说明性能很高,这个就是延迟。
kafka,每毫秒可以处理1条数据,每秒可以处理1000条数据,这个单位时间内可以处理多少条数据,就叫做吞吐量,1000条数据,每条数据10kb,10mb,吞吐量相当于是每秒处理10mb的数据
1. Kafka是如何利用顺序磁盘写机制实现单机每秒几十万消息写入的?

kafka的特点:高吞吐低延迟
直接写入os的page cache中
文件,kafka仅仅是追加数据到文件末尾,磁盘顺序写,性能极高,几乎跟写内存是一样高的。磁盘随机写,你要随机在文件的某个位置修改数据,这个叫做磁盘随机写,性能是很低的,磁盘顺序写,仅仅追加数据到文件末尾
而且写磁盘的方式是顺序写,不是随机写,性能跟内存写几乎一样。就是仅仅在磁盘文件的末尾追加写,不能在文件随机位置写入
假设基于上面说的os cache写 + 磁盘顺序写,0.01毫秒,低延迟,高吞吐,每毫秒可以处理100条数据,每秒可以处理10万条数据,不需要依托类似spark straeming那种batch微批处理的机制
正是依靠了这个超高的写入性能,单物理机可以做到每秒几十万条消息写入Kafka
这种方式让kafka的写性能极高,最大程度减少了每条数据处理的时间开销,反过来就大幅度提升了每秒处理数据的吞吐量,一般kafka部署在物理机上,单机每秒写入几万到几十万条消息是没问题的
这种方式是不是就兼顾了低延迟和高吞吐两个要求,尽量把每条消息的写入性能压榨到极致,就可以实现低延迟的写入,同时对应的每秒的吞吐量自然就提升了
所以这是kafka非常核心的一个底层机制
而且这里很关键的一点,比如rabbitmq这种消息中间件,他会先把数据写入内存里,然后到了一定时候再把数据一次性从内存写入磁盘里,但是kafka不是这种机制,他收到数据直接写磁盘
只不过是先写的page cache,然后是磁盘顺序写,所以写入的性能非常高,而且这样不需要让kafka自身的jvm进程占用过多内存,可以更多的把内存空间留给os的page cache来缓存磁盘文件的数据
只要能让更多的磁盘数据缓存在os cache里,那么后续消费数据从磁盘读的时候,就可以直接走os cache读数据了,性能是非常高的
2. Kafka是如何利用零拷贝和页缓存技术实现高性能读取的?

那么在消费数据的时候,需要从磁盘文件里读取数据后通过网络发送出去,这个时候怎么提升性能呢?
首先就是利用了page cache技术,之前说过,kafka写入数据到磁盘文件的时候,实际上是写入page cache的,没有直接发生磁盘IO,所以写入的数据大部分都是停留在os层的page cache里的
这个本质其实跟elasticsearch的实现原理是类似的
然后在读取的时候,如果正常情况下从磁盘读取数据,先尝试从page cache读,读不到才从磁盘IO读,读到数据以后先会放在os层的一个page cache里,接着会发生上下文切换到系统那边,把os的读缓存数据拷贝到应用缓存里
接着再次发生上下文二切换到os层,把应用缓存的数据拷贝到os的socket缓存中,最后数据再发送到网卡上
这个过程里,发生了好几次上下文切换,而且还涉及到了好几次数据拷贝,如果不考虑跟硬件之间的交互,起码是从os cache到用户缓存,从用户缓存到socket缓存,有两次拷贝是绝对没必要的
但是如果用零拷贝技术,就是linux的sendfile,就可以直接把操作交给os,os看page cache里是否有数据,如果没有就从磁盘上读取,如果有的话直接把os cache里的数据拷贝给网卡了,中间不用走那么多步骤了
对比一下,是不是所谓的零考别了?
所以呢,通过零拷贝技术来读取磁盘上的数据,还有page cahce的帮助,这个性能就非常高了
3. Kafka的底层数据存储结构:日志文件以及offset

基本上可以认为每个partition就是一个日志文件,存在于某台Kafka服务器上,然后这个日志里写入了很多消息,每个消息在partition日志文件里都有一个序号,叫做offset,代表这个消息是日志文件里的第几条消息
但是在消费消息的时候也有一个所谓的offset,这个offset是代表消费者目前在partition日志文件里消费到了第几条消息,是两回事儿
4. Kafka是如何通过精心设计消息格式节约磁盘空间占用开销的?
kafka的消息格式如下:
crc32,magic,attribute,时间戳,key长度,key,value长度,value
kafka是直接通过NIO的ByteBuffer以二进制的方式来保存消息的,这种二级制紧凑保存格式可以比使用Java对象保存消息要节约40%的内存空间
然后这个消息实际上是封装在一个log entry里的,你可以认为是一个日志条目吧,在kafka里认为每个partition实际上就是一个磁盘上的日志文件,写到parttion里去的消息就是一个日志,所以log entry就是一个日志
这个日志条目包含了一个offset,一个消息的大小,然后是消息自身,就是上面那个数据结构,但是这里要注意的一点,就是这个message里可能会包含多条消息压缩在一起,所以可能找一条消息,需要从这个压缩数据里遍历搜索
而且这里还有一个概念就是消息集合,一个消息集合里包含多个日志,最新名称叫做RecordBatch
后来消息格式演化为了如下所示:
(1)消息总长度
(2)属性:废弃了,已经不用
(3)时间戳增量:跟RecordBatch的时间戳的增量差值
(4)offset增量:跟RecordBatch的offset的增量差值
(5)key长度
(6)key
(7)value长度
(8)value
(9)header个数
(10)header:自定义的消息元数据,key-value对
通过时间戳、offset、key长度等都用可变长度来尽可能减少空间占用,v2版本的数据格式比v1版本的数据格式要节约很多磁盘开销
5. 如何实现TB量级的数据在Kafka集群中分布式的存储?
但是这里有一个很大的问题,就是不可能说把TB量级的数据都放在一台Kafka服务器上吧?这样肯定会遇到容量有限的问题,所以Kafka是支持分布式存储的,也就是说你的一个topic,代表了逻辑上的一个数据集
你大概可以认为一个业务上的数据集合吧,比如说用户行为日志都走一个topic,数据库里的每个表的数据分别是一个topic,订单表的增删改的变更记录进入一个topic,促销表的增删改的变更记录进入一个topic
每个topic都有很多个partition,你认为是数据分区,或者是数据分片,大概这些意思都可以,就是说这个topic假设有10TB的数据量需要存储在磁盘上,此时你给他分配了5个partition,那么每个partition都可以存放2TB的数据
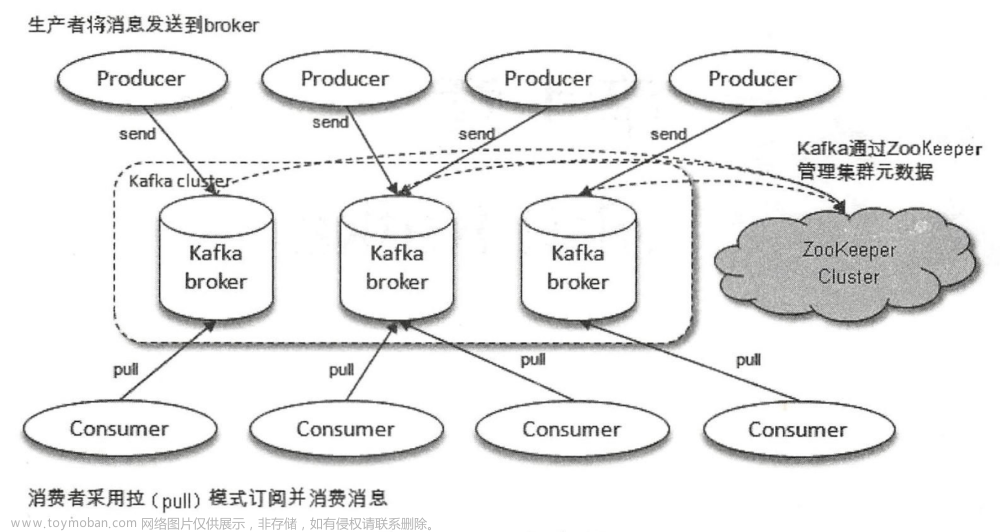
然后每个partition不就可以放在一台机器上,通过这个方式就可以实现数据的分布式存储了,每台机器上都运行一个Kafka的进程,叫做Broker,以后大家记住,broker就是一个kafka进程,在一台服务器上就可以了
二、高可用架构原理——异步复制+ISR列表
1. 如何基于多副本冗余机制保证Kafka宕机时还具备高可用性?
但是这里就有一个问题了,如果此时Kafka某台机器宕机了,那么一个topic就丢失了一个partition的数据,此时不就导致数据丢失了吗?所以啊,所以对数据做多副本冗余,也就是每个parttion都有副本
比如最基本的就是每个partition做一个副本,副本放在另外一台机器上
然后呢kafka自动从一个partition的多个副本中选举出来一个leader partition,这个leader partition就负责对外提供这个partiton的数据读写,接收到写过来的数据,就可以把数据复制到副本partition上去
这个时候如果说某台机器宕机了,上面的leader partition没了,此时怎么办呢?通过zookeeper来维持跟每个kafka的会话,如果一个kafka进程宕机了,此时kafka集群就会重新选举一个leader partition,就是用他的某个副本partition即可
通过副本partition可以继续体统这个partition的数据写入和读取,这样就可以实现容错了,这个副本partition的专业术语叫做follower partition,所以每个partitino都有多个副本,其中一个是leader,是选举出来的,其他的都是follower partition
多副本冗余的机制,就可以实现Kafka高可用架构
2. 保证写入Kafka的数据不丢失:ISR机制到底是什么意思?

光是依靠多副本机制能保证Kafka的高可用性,但是能保证数据不丢失吗?不行,因为如果leader宕机,但是leader的数据还没同步到follower上去,此时即使选举了follower作为新的leader,当时刚才的数据已经丢失了
ISR是:in-sync replica,就是跟leader partition保持同步的follower partition的数量,只有处于ISR列表中的follower才可以在leader宕机之后被选举为新的leader,因为在这个ISR列表里代表他的数据跟leader是同步的
如果要保证写入kafka的数据不丢失,首先需要保证ISR中至少有一个follower,其次就是在一条数据写入了leader partition之后,要求必须复制给ISR中所有的follower partition,才能说代表这条数据已提交,绝对不会丢失,这是Kafka给出的承诺
3. 如何让Kafka集群处理请求的时候实现负载均衡的效果?
假如说很多partition的leader都在一台机器上,那么不就会导致大量的客户端都请求那一台机器?这样是不对的,kafka集群会自动实现负载均衡的算法,尽量把leader partition均匀分布在集群各个机器上
然后客户端在请求的时候,就会尽可能均匀的请求到kafka集群的每一台机器上去了,假如出现了partition leader的变动,那么客户端会感知到,然后下次就可以请求最新的那个leader partition了
4. 基于ZooKeeper实现Kafka无状态可伸缩的架构设计思路

5. Kafka集群是如何基于Zookeeper实现节点发现与故障感知的?

6. 再看ISR机制:Leader宕机时只能选举同步的Follower
7. Partition的几个核心offset:高水位offset、LEO代表了什么?

实际上来说,每次leader接收到一条消息,都会更新自己的LEO,也就是log end offset,把最后一位offset + 1,这个大家都能理解吧?接着各个follower会从leader请求同步数据,这是持续进行的
offset = 0 ~ offset = 4,LEO = 5,代表了最后一条数据后面的offset,下一次将要写入的数据的offset,LEO,你一定要明白他的名词
然后follower同步到数据之后,就会更新自己的LEO
并不是leader主动推送数据给follower,他实际上是follower主动向leader尝试获取数据,不断的发送请求到leader来fetch最新的数据
然后对于接收到的某一条数据,所有follower的LEO都更新之后,leader才会把自己的HW(High Water Mark)高水位offset + 1,这个高水位offset表示的就是最新的一条所有follower都同步完成的消息
partition中最开始的一条数据的offset是base offset
LEO和HW分别是干什么的呢?
LEO很重要的一个功能,是负责用来更新HW的,就是如果leader和follower的LEO同步了,此时HW就可以更新
所有对于消费者来说,他只能看到base offset到HW offset之间的数据因为只有这之间的数据才表明是所有follower都同步完成的,这些数据叫做“已提交”的,也就是committed,是可以被消费到的
HW offset到LEO之间的数据,是“未提交的”,这时候消费者是看不到的
HW offset表示的是当前已经提交的数据offset,LEO表示的是下一个要写入的数据的offset
8. 深入探究Leader与Follower上的LEO是如何更新的?

首先leader接收到数据字后就会更新自己的LEO值
接着follower会不断的向leader发送fetch请求同步数据,然后每次一条数据同步到follower之后,他的LEO就会更新,同时leader发送数据给follower的时候,在leader端会维护所有follower的LEO值
follower发送fetch请求给leader的时候会带上自己的LEO值,然后leader每次收到一个fetch请求就会更新自己维护的每个follower的LEO值
所以这里大家要知道的是,leader上是会保存所有follower的LEO值的,这个是非常关键和核心的一点
9. 深入探究Leader与Follower上的高水位offset是如何更新的?

每次leader发送数据给follower的时候,都会发送自己的HW值,然后follower获取到leader HW之后,就会跟自己的LEO比较一下,取里面小的那个值作为自己的HW值,换句话说,如果follower的LEO比leader HW大了,那么follower的HW就是leader HW
但是如果follower的LEO比leader HW小,说明自己明显落后于leader,那么follower的HW就是自己的LEO值
然后leader上的HW就很明显了,那就是主要是他在接收follower的fetch请求的时候,就会在更新自己维护的所有follower的LEO之后,判断一下当前自己的LEO是否跟所有follower都保持一致,那么就会自动更新自己的HW值
这个leader partition的HW值,代表了从这个partition的哪个offset之前可以被消费数据
10. 用真实场景图解剖析Leader与Follower的LEO与高水位如何更新?

假设leader收到第一条数据,此时leader LEO = 1,HW = 0,因为他发现其他follower的LEO也是0,所以HW必须是0
接着follower来发送fetch请求给leader同步数据,带过去follower的LEO = 0,所以leader上维护的follower LEO = 0,更新了一下,此时发现follower的LEO还是0,所以leader的HW继续是0
接着leader发送一条数据给follower,这里带上了leader的HW = 0,因为发现leader的HW = 0,此时follower LEO更新为1,但是follower HW = 0,取leader HW
接着下次follower再次发送fetch请求给leader的时候,就会带上自己的LEO = 1,leader更新自己维护的follower LEO = 1,此时发现follower跟自己的LEO同步了,那么leader的HW更新为1
接着leader发送给follower的数据里包含了HW = 1,此时follower发现leader HW = 1,自己的LEO = 1,此时follower的HW有更新为1
5个数据:全部都要往前推进更新,需要2次请求,第一次请求是仅仅是更新两边的LEO,第二次请求是更新另外leader管理的follower LEO,以及两个HW
11. 高水位机制可能导致leader切换时发生数据丢失问题
基于之前说的高水位机制,可能会导致一些问题,比如数据丢失
假如说生产者的min.insync.replicas设置为1,这个就会导致说生产者发送消息给leader,leader写入log成功后,生产者就会认为写成功了,此时假设生产者发送了两条数据给leader,leader写成功了
此时leader的LEO = 1,HW = 0,因为follower还没同步,HW肯定是0
接着follower发送fetch请求,此时leader发现follower LEO = 0,所以HW还是0,给follower带回去的HW也是0,然后follower开始同步数据也写入了两条数据,自己的LEO = 1,但是HW = 0,因为leader HW为0
接着follower再次发送fetch请求过来,自己的LEO = 1,leader发现自己LEO = 1,follower LEO = 1,所以HW更新为1,同时会把HW = 1带回给follower,但是此时follower还没更新HW的时候,HW还是0
这个时候假如说follower机器宕机了,重启机器之后,follower的LEO会自动被调整为0,因为会依据HW来调整LEO,而且自己的那两条数据会被从日志文件里删除,数据就没了
这个时候如果leader宕机,就会选举follower为leader,此时HW = 0,接着leader那台机器被重启后作为follower,这个follower会从leader同步HW是0,此时会截断自己的日志,删除两条数据
这种场景就会导致数据的丢失
非常极端的一个场景,数据可能会莫名其妙的丢失
12. 高水位机制可能导致leader切换时发生数据不一致问题

假设min.insync.replicas = 1,那么只要leader写入成功,生产者而就会认为写入成功
如果leader写入了两条数据,但是follower才同步了一条数据,第二条数据还没同步,假设这个时候leader HW = 2,follower HW = 1,因为follower LEO小于leader HW,所以follower HW取自己的LEO
这个时候如果leader挂掉,切换follower变成leader,此时HW = 1,就一条数据,然后生产者又发了一条数据给新leader,此时HW变为2,但是第二条数据是新的数据。接着老leader重启变为follower,这个时候发现两者的HW都是2
所以他们俩就会继续运行了
这个时候他们俩数据是不一致的,本来合理的应该是新的follower要删掉自己原来的第二条数据,跟新leader同步的,让他们俩的数据一致,但是因为依赖HW发现一样,所以就不会截断数据了
13. Kafka 0.11.x版本引入leader epoch机制解决高水位机制弊端

所谓的leader epoch大致理解为每个leader的版本号,以及自己是从哪个offset开始写数据的,类似[epoch = 0, offset = 0],这个就是epoch是版本号的意思,接着的话,按照之前的那个故障场景
假如说follower先宕机再重启,他会找leader继续同步最新的数据,更新自己的LEO和HW,不会截断数据,因为他会看看自己这里有没有[epoch, offset]对,如果有的话,除非是自己的offset大于了leader的offset,才会截断自己的数据
而且人家leader的最新offset = 1,自己的offset = 0,明显自己落后于人家,有什么资格去截断数据呢?对不对,就是这个道理。而且还会去从leader同步最新的数据过来,此时自己跟Leader数据一致。
如果此时leader宕机,切换到follower上,此时就会更新自己的[epoch = 1, offset = 2],意思是自己的leader版本号是epoch = 1,自己从offset = 2开始写数据的
然后接着老leader恢复变为follower,从新leader看一下epoch跟自己对比,人家offset = 2,自己的offset = 0,也不需要做任何数据截断,直接同步人家数据就可以了
然后针对数据不一致的场景,如果说老leader恢复之后作为follower,从新leader看到[epoch = 1, offset = 1],此时会发现自己的offset也是1,但是人家新leader是从offset = 1开始写的,自己的offset = 1怎么已经有数据了呢?
此时就会截断掉自己一条数据,然后跟人家同步保持数据一致
14. Kafka为Partition维护ISR列表的底层机制是如何设计的?
很多公司比较常用的一个kafka的版本,是0.8.2.x系列,这个系列的版本是非常经典的,在过去几年相当大比例的公司都是用这个版本的kafka。当然,现在很多公司开始用更新版本的kafka了,就是0.9.x或者是1.x系列的
我们先说说在0.9.x之前的版本里,这个kafka到底是如何维护ISR列表的,什么样的follower才有资格放到ISR列表里呢?
在之前的版本里,有一个核心的参数:replica.lag.max.messages。这个参数就规定了follower如果落后leader的消息数量超过了这个参数指定的数量之后,就会认为follower是out-of-sync,就会从ISR列表里移除了
咱们来举个例子好了,假设一个partition有3个副本,其中一个leader,两个follower,然后replica.lag.max.messages = 3,刚开始的时候leader和follower都有3条数据,此时HW和LEO都是offset = 2的位置,大家都同步上来了
现在来了一条数据,leader和其中一个follower都写入了,但是另外一个follower因为自身所在机器性能突然降低,导致没及时去同步数据,follower所在机器的网络负载、内存负载、磁盘负载过高,导致整体性能下降了,此时leader partition的HW还是offset = 2的位置,没动,但是LEO变成了offset = 3的位置
依托LEO来更新ISR的话,在每个follower不断的发送Fetch请求过来的时候,就会判断leader和follower的LEO相差了多少,如果差的数量超过了replica.lag.max.messages参数设置的一个阈值之后,就会把follower给踢出ISR列表
但是这个时候第二个follower的LEO就落后了leader才1个offset,还没到replica.lag.max.messages = 3,所以第二个follower实际上还在ISR列表里,只不过刚才那条消息没有算“提交的”,在HW外面,所以消费者是读不到的
而且这个时候,生产者写数据的时候,如果默认值是要求必须同步所有follower才算写成功的,可能这个时候会导致生产者一直卡在那儿,认为自己还没写成功,这个是有可能的
一共有3个副本,1个leaderr,2个是follower,此时其中一个follower落后,被ISR踢掉了,ISR里还有2个副本,此时一个leader和另外一个follower都同步成功了,此时就可以让那些卡住的生产者就可以返回,认为写数据就成功了
min.sync.replicas = 2,ack = -1,生产者要求你必须要有2个副本在isr里,才可以写,此外,必须isr里的副本全部都接受到数据,才可以算写入成功了,一旦说你的isr副本里面少于2了,其实还是可能会导致你生产数据被卡住的
假设这个时候,第二个follower fullgc持续了几百毫秒然后结束了,接着从leader同步了那条数据,此时大家LEO都一样,而且leader发现所有follower都同步了这条数据,leader就会把HW推进一位,HW变成offset = 3
这个时候,消费者就可以读到这条在HW范围内的数据了,而且生产者认为写成功了
但是要是此时follower fullgc一直持续了好几秒钟,此时其他的生产者一直在发送数据过来,leader和第一个follower的LEO又推进了2位,LEO offset = 5,但是HW还是停留在offset = 2,这个时候HW后面的数据都是消费不了的,而且HW后面的那几条数据的生产者可能都会认为写未成功
现在导致第二个follower的LEO跟leader的LEO差距超过3了,此时触发阈值,follower认为是out-of-sync,就会从ISR列表里移除了
一旦第二个follower从ISR列表里移除了,世界清静了,此时ISR列表里就leader和第一个follower两个副本了,此时leader和第一个follower的LEO都是offset = 5,是同步的,leader就会把HW推进到offset = 5,此时消费者就可以消费全部数据了,生产者也认为他们的写操作成功了
那如果第二个follower后来他的fullgc结束了,开始大力追赶leader的数据,慢慢LEO又控制在replica.lag.max.messages限定的范围内了,此时follower会重新加回到ISR列表里去
上面就是ISR的工作原理和机制,一般导致follower跟不上的情况主要就是以下三种:
(1)follower所在机器的性能变差,比如说网络负载过高,IO负载过高,CPU负载过高,机器负载过高,都可能导致机器性能变差,同步 过慢,这个时候就可能导致某个follower的LEO一直跟不上leader,就从ISR列表里移除了
我们生产环境遇到的一些问题,kafka,机器层面,某台机器磁盘坏了,物理机的磁盘有故障,写入性能特别差,此时就会导致follower,CPU负载太高了,线程间的切换太频繁了,CPU忙不过来了,网卡被其他的程序给打满了,就导致网络传输的速度特别慢
(2)follower所在的broker进程卡顿,常见的就是fullgc问题
kafka自己本身对jvm的使用是很有限的,生产集群部署的时候,他主要是接收到数据直接写本地磁盘,写入os cache,他一般不怎么在自己的内存里维护过多的数据,主要是依托os cache(缓存)来提高读和写的性能的
(3)kafka是支持动态调节副本数量的,如果动态增加了partition的副本,就会增加新的follower,此时新的follower会拼命从leader上同步数据,但是这个是需要过程的,所以此时需要等待一段时间才能跟leader同步
replica.lag.max.messages主要是解决第一种情况的,还有一个replica.lag.time.max.ms是解决第二种情况的,比如设置为500ms,那么如果在500ms内,follower没法送请求找leader来同步数据,说明他可能在fullgc,此时就会从ISR里移除
15. Kafka 0.8.2.x版本的ISR机制在生产环境有什么缺陷?
之前说的那套ISR机制是kafka 0.8.x系列的机制,其实是有缺陷的,那个参数默认的值是4000,也就是follower落后4000条数据就认为是out-of-sync,但是这里有一个问题,就是这个数字是固定死的
如果说现在生产端突然之间涌入几万条数据呢?是不是有可能leader瞬间刚接收到几万条消息,然后所有follower还没来得及同步过去,此时所有follower都会被踢出ISR列表?然后同步了之后,再回到ISR列表
所以这种依靠固定参数判断的机制,会导致可能在系统高峰时期,follower会频繁的踢出ISR列表再回到ISR列表,这种完全无意义的事情
一般来说在kafka 0.8.2.x系列版本上生产的时候,一遍都会把这个ISR落后 判定阈值设置的大一些,避免上述的情况出现,你可以设置个几万,10万,4000,如果你公司里没那么大的高峰并发量,每秒就是几千的并发,那就没问题了
16. Kafka 0.9x版本之后的ISR机制做了哪些优化适应生产环境?
kafka 0.9.x之后去掉了原来的replica.lag.max.messages参数,引入了一个新的replica.lag.time.max.ms参数,默认值是10秒,这个就不按照落后的条数来判断了,而是说如果某个follower的LEO一直落后leader超过了10秒,那么才判定这个follower是out-of-sync的
这样假如说线上出现了流量洪峰,一下子导致几个follower都落后了不少数据,但是只要尽快追上来,在10秒内别一直落后,就不会认为是out-of-sync,这个机制在线上实践会发现效果要好多了
三、稀疏索引文件底层原理
1. 深入看看Kafka在磁盘上是如何采用分段机制保存日志的?
每个分区对应的目录,就是“topic-分区号”的格式,比如说有个topic叫做“order-topic”,那么假设他有3个分区,每个分区在一台机器上,那么3台机器上分别会有3个目录,“order-topic-0”,“order-topic-1”,“order-topic-2”
每个分区里面就是很多的log segment file,也就是日志段文件,每个分区的数据会被拆分为多个段,放在多个文件里,每个文件还有自己的索引文件,大概格式可能如下所示:
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个9936472之类的数字,就是代表了这个日志段文件里包含的起始offset,也就说明这个分区里至少都写入了接近1000万条数据了
kafka broker有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB,一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling
正在被写入的那个日志段文件,叫做active log segment
2. 引入索引文件之后如何基于二分查找快速定位数据?
日志段文件,.log文件会对应一个.index和.timeindex两个索引文件
kafka在写入日志文件的时候,同时会写索引文件,就是.index和.timeindex,一个是位移索引,一个是时间戳索引,是两种索引
默认情况下,有个参数log.index.interval.bytes限定了在日志文件写入多少数据,就要在索引文件写一条索引,默认是4KB,写4kb的数据然后在索引里写一条索引,所以索引本身是稀疏格式的索引,不是每条数据对应一条索引的
而且索引文件里的数据是按照位移和时间戳升序排序的,所以kafka在查找索引的时候,会用二分查找,时间复杂度是O(logN),找到索引,就可以在.log文件里定位到数据了
.index
44576 物理文件(.log位置)
57976 物理文件(.log位置)
64352 物理文件(.log位置)
offset = 58892 => 57976这条数据对应的.log文件的位置
接着就可以从.log文件里的57976这条数对应的位置开始查找,去找offset = 58892这条数据在.log里的完整数据
.timeindex是时间戳索引文件,如果要查找某段时间范围内的时间,先在这个文件里二分查找找到offset,然后再去.index里根据offset二分查找找对应的.log文件里的位置,最后就去.log文件里查找对应的数据
3. 磁盘上的日志文件是按照什么策略定期清理腾出空间的?
大家可以想,不可能说每天涌入的数据都一直留存在磁盘上,本质kafka是一个流式数据的中间件,不需要跟离线存储系统一样保存全量的大数据,所以kafka是会定期清理掉数据的,这里有几个清理策略
kafka默认是保留最近7天的数据,每天都会把7天以前的数据给清理掉,包括.log、.index和.timeindex几个文件,log.retention.hours参数,可以自己设置数据要保留多少天,你可以根据自己线上的场景来判断一下
只要你的数据保留在kafka里,你随时可以通过offset的指定,随时可以从kafka楼出来几天之前的数据,数据回放一遍,下游的数据,有多么的重要,如果是特别核心的数据,在kafka这个层面,可以保留7天,甚至是15天的数据
下游的消费者消费了数据之后,数据丢失了,你需要从kafka里楼出来3天前的数据,重新来回放处理一遍
在大数据的实时分析的项目里,其实就会涉及到这个东西的一个使用,如果你今天实时分析的一些数据出错了,此时你就需要把过去几天的数据重新楼出来回放一遍,重新来算一遍。实时数据分析的结果和hadoop离线分析的结果做一个比对
你每天都会从kafka里搂出来几天前的数据,算一下,跟离线数据的结果做一个比对
kafka broker会在后台启动线程异步的进行日志清理的工作
四、Reactor网络模型
1. Kafka是如何自定义TCP之上的通信协议以及使用长连接通信的
kafka的通信主要发生于生产端和broker之间,broker和消费端之间,broker和broker之间,这些通信都是基于TCP协议进行的,大家自己看看网络课程,底层基于TCP连接和传输数据,应用层的协议,是Kafka自己自定义的
所谓自定义协议,就是定好传输数据的格式,请求格式、响应格式,这样大家就可以统一按照规定好的格式来封装、传输和解析数据了
生产端发送数据到kafka broker来,此时发送的数据是这样子的:
sent data: 一大串数据
kafka broker直接就从sent data:截取一大段数据就可以用了,如果你没有自定义一套完整的协议,是没办法进行通信的
http协议,生产端也可以发送http协议的数据给kafka broker,http请求,http响应。应用层的协议,规定了数据请求和响应的种种复杂的格式,大家全部按照这个格式和规范来走,不要乱来
request v1.1
isCache: true
一大串数据
对于生产端和broker,消费端和broker来说,还会基于TCP建立长连接(具体见网络课程),也就是维护一批长连接,然后通过固定的连接不断的传输数据,避免频繁的创建连接和销毁连接的开销
broker端会构造一个请求队列,然后不停的获取请求放入队列,后台再搞一堆的线程来获取请求进行处理
2. Broker是如何基于Reactor模式进行多路复用请求处理的?

每个broker上都有一个acceptor线程和很多个processor线程,可以用num.network.threads参数设置processor线程的数量,默认是3,client跟一个broker之间只会创建一个socket长连接,他会复用
然后broker就用一个acceptor来监听每个socket连接的接入,分配这个socket连接给一个processor线程,processor线程负责处理这个socket连接,监听socket连接的数据传输以及客户端发送过来的请求,acceptor线程会不停的轮询各个processor来分配接入的socket连接
proessor需要处理多个客户端的socket连接,就是通过java nio的selector多路复用思想来实现的,用一个selector监听各个socket连接,看其是否有请求发送过来,这样一个processor就可以处理多个客户端的socket连接了
processor线程会负责把请求放入一个broker全局唯一的请求队列,默认大小是500,是queued.max.requests参数控制的,所以那几个processor会不停的把请求放入这个请求队列中
接着就是一个KafkaRequestHandler线程池负责不停的从请求队列中获取请求来处理,这个线程池大小默认是8个,由num.io.threads参数来控制,处理完请求后的响应,会放入每个processor自己的响应队列里
每个processor其实就是负责对多个socket连接不停的监听其传入的请求,放入请求队列让KafkaRequestHandler来处理,然后会监听自己的响应队列,把响应拿出来通过socket连接发送回客户端
五、Controller选举与故障转移原理剖析
1. 如何对Kafka集群进行整体控制:Controller是什么东西?
不知道大家有没有思考过一个问题,就是Kafka集群中某个broker宕机之后,是谁负责感知到他的宕机,以及负责进行Leader Partition的选举?如果你在Kafka集群里新加入了一些机器,此时谁来负责把集群里的数据进行负载均衡的迁移?
包括你的kafka集群的各种元数据,比如说每台机器上有哪些partition,谁是leader,谁是follower,是谁来管理的?如果你要删除一个topic,那么背后的各种partition如何删除,是谁来控制?
还有就是比如kafka集群扩容加入一个新的broker,是谁负责监听这个broker的加入?如果某个broker崩溃了,是谁负责监听这个broker崩溃?
这里就需要一个kafka集群的总控组件,Controller。他负责管理整个kafka集群范围内的各种东西
2. 如何基于Zookeeper实现Controller的选举以及故障转移
在kafka集群启动的时候,会自动选举一台broker出来承担controller的责任,然后负责管理整个集群,这个过程就是说集群中每个broker都会尝试在zk上创建一个/controller临时节点
zk的一些基础知识和临时节点是什么,百度一下zookeeper入门
但是zk会保证只有一个人可以创建成功,这个人就是所谓controller角色
一旦controller所在broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,保证有一台新的broker会成为controller角色
3. 创建Topic时Kafka Controller是如何完成Leader选举的呢?
如果你现在创建一个Topic,肯定会分配几个Partition,每个partition还会指定几个副本,这个时候创建的过程中就会在zookeeper中注册对应的topic的元数据,包括他有几个partition,每个partition有几个副本,每个partition副本的状态,此时状态都是:NonExistentReplica
然后Kafka Controller本质其实是会监听zk上的数据变更的,所以此时就会感知到topic变动,接着会从zk中加载所有partition副本到内存里,把这些partition副本状态变更为:NewReplica,然后选择的第一个副本作为leader,其他都是follower,并且把他们都放到partition的ISR列表中
比如说你创建一topic,order_topic,3个partition,每个partition有2个副本,写入zk里去
/topics/order_topic
partitions = 3, replica_factor = 2
[partition0_1, partition0_2]
[partition1_1, partition1_2]
[partition2_1, partition2_2]
从每个parititon的副本列表中取出来第一个作为leader,其他的就是follower,把这些东西给放到partition对应的ISR列表里去
每个partition的副本在哪台机器上呢?会做一个均匀的分配,把partition分散在各个机器上面,通过算法来保证,尽可能把每个leader partition均匀分配在各个机器上,读写请求流量都是打在leader partition上的
同时还会设置整个Partition的状态:OnlinePartition
接着Controller会把这个partition和副本所有的信息(包括谁是leader,谁是follower,ISR列表),都发送给所有broker让他们知晓,在kafka集群里,controller负责集群的整体控制,但是每个broker都有一份元数据
4. 删除Topic时又是如何通过Kafka Controller控制数据清理?
如果你要是删除某个Topic的话,Controller会发送请求给这个Topic所有Partition所在的broker机器,通知设置所有Partition副本的状态为:OfflineReplica,也就是让副本全部下线,接着Controller接续将全部副本状态变为:ReplicaDeletionStarted
然后Controller还要发送请求给broker,把各个partition副本的数据给删了,其实对应的就是删除磁盘上的那些文件,删除成功之后,副本状态变为:ReplicaDeletionSuccessful,接着再变为NonExistentReplica文章来源:https://www.toymoban.com/news/detail-676188.html
而且还会设置分区状态为:Offline文章来源地址https://www.toymoban.com/news/detail-676188.html
5. Kafka Controller是如何基于ZK感知Broker的上线以及崩溃的?
到了这里,关于Kafka核心原理第一弹——更新中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!