目录
一、JVM 简介
1.1 JVM 发展史
1.Sun Classic VM
2.Exact VM
3.HotSpot VM
4.JRockit
5.J9 JVM
6.Taobao JVM(国产研发)
1.2 JVM 和《Java虚拟机规范》
二、 JVM 运行流程
JVM 执行流程
三、JVM 运行时数据区
3.1 堆(线程共享)
3.2 Java虚拟机栈(线程私有)
3.3 本地方法栈(线程私有)
3.4 程序计数器(线程私有)
3.5 方法区(线程共享)
3.6 内存布局中的异常问题
① Java堆溢出
② 虚拟机栈和本地方法栈溢出
四、JVM 类加载
① 类加载过程
1) 加载
2) 验证
3) 准备
4) 解析
5) 初始化
② 双亲委派模型
③ 破坏双亲委派模型
五、垃圾回收相关
① 死亡对象的判断算法
a) 引用计数算法
b) 可达性分析算法
② 垃圾回收算法
a) 标记-清除算法
b) 复制算法
c) 标记-整理算法
d) 分代算法
③ 垃圾收集器
为什么会有这么多垃圾收集器?
a) Serial收集器(新生代收集器,串行GC)
b) ParNew收集器(新生代收集器,并行GC)
c) Parallel Scavenge收集器(新生代收集器,并行GC)
d) Serial Old收集器(老年代收集器,串行GC)【选学】
e) Parallel Old收集器(老年代收集器,并行GC)
f) CMS收集器(老年代收集器,并发GC)
g) G1收集器(唯一一款全区域的垃圾回收器)
④ 总结:一个对象的一生
六、JMM
① 主内存与工作内存
② 内存间交互操作
③ volatile型变量的特殊规则
一、JVM 简介
1. VMwave 与 Virtual Box 是通过软件模拟物理 CPU 的指令集,物理系统中会有很多的寄存器;2. JVM 则是通过软件模拟 Java 字节码的指令集, JVM 中只是主要保留了 PC 寄存器,其他的寄存器都进行了裁剪。
1.1 JVM 发展史
1.Sun Classic VM
2.Exact VM
1. 热点探测(将热点代码编译为字节码加速程序执行);2. 编译器与解析器混合工作模式。
3.HotSpot VM
1. 最初由一家名为 “Longview Technologies” 的小公司设计;2. 1997 年,此公司被 Sun 收购; 2009 年, Sun 公司被甲骨文收购。3. JDK1.3 时, HotSpot VM 成为默认虚拟机
4.JRockit
5.J9 JVM
6.Taobao JVM(国产研发)
1. 创新的 GCIH(GC invisible heap) 技术实现了 off-heap ,即将生命周期较长的 Java 对象从 heap 中移到heap 之外,并且 GC 不能管理 GCIH 内部的 Java 对象,以此达到降低 GC 的回收评率和提升 GC 的回收效率的目的。2. GCIH 中的对象还能够在多个 Java 虚拟机进程中实现共享。3. 使用 crc32 指令实现 JVM intrinsic 降低 JNI 的调用开销;4. PMU hardware 的 Java profiling tool 和诊断协助功能;5. 针对大数据场景的 ZenGC 。
1.2 JVM 和《Java虚拟机规范》
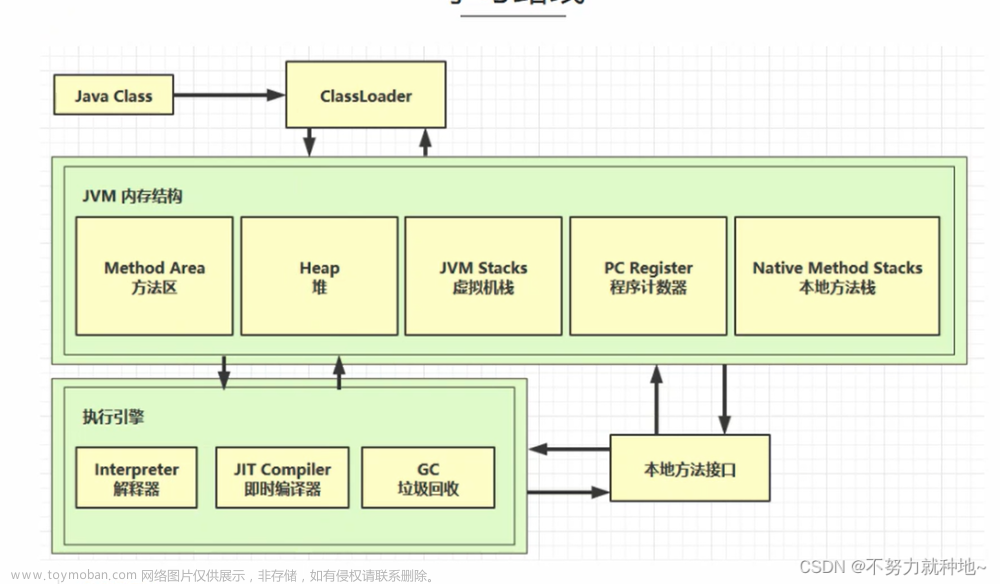
二、 JVM 运行流程
JVM 执行流程

1. 类加载器( ClassLoader )2. 运行时数据区( Runtime Data Area )3. 执行引擎( Execution Engine )4. 本地库接口( Native Interface )
三、JVM 运行时数据区

3.1 堆(线程共享)

3.2 Java虚拟机栈(线程私有)

1. 局部变量表: 存放了编译器可知的各种基本数据类型 (8 大基本数据类型 ) 、对象引用。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在执行期间不会改变局部变量表大小。简单来说就是存放方法参数和局部变量。2. 操作栈:每个方法会生成一个先进后出的操作栈。3. 动态链接:指向运行时常量池的方法引用。4. 方法返回地址: PC 寄存器的地址。
3.3 本地方法栈(线程私有)
3.4 程序计数器(线程私有)
3.5 方法区(线程共享)
1. 对于 HotSpot 来说, JDK 8 元空间的内存属于本地内存,这样元空间的大小就不在受 JVM 最大内存的参数影响了,而是与本地内存的大小有关。2. JDK 8 中将字符串常量池移动到了堆中。

3.6 内存布局中的异常问题
① Java堆溢出


/**
* JVM 参数为:-Xmx20m -Xms20m -XX:+HeapDumpOnOutOfMemoryError
* @author 38134
*
*/
public class Test {
static class OOMObject {
}
public static void main(String[] args) {
List<OOMObject> list =
new ArrayList<>();
while(true) {
list.add(new OOMObject());
}
}
}② 虚拟机栈和本地方法栈溢出
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,会抛出StackOverFlow异常
- 如果虚拟机在拓展栈时无法申请到足够的内存空间,则会抛出OOM异常
/**
* JVM参数为:-Xss128k
* @author 38134
*
*/
public class Test {
private int stackLength = 1;
public void stackLeak() {
stackLength++;
stackLeak();
}
public static void main(String[] args) {
Test test = new Test();
try {
test.stackLeak();
} catch (Throwable e) {
System.out.println("Stack Length: "+test.stackLength);
throw e;
}
}
}/**
* JVM参数为:-Xss2M
* @author 38134
*
*/
public class Test {
private void dontStop() {
while(true) {
}
}
public void stackLeakByThread() {
while(true) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
dontStop();
}
});
thread.start();
}
}
public static void main(String[] args) {
Test test = new Test();
test.stackLeakByThread();
}
}
四、JVM 类加载
① 类加载过程

1. 加载2. 连接1. 验证2. 准备3. 解析3. 初始化
1) 加载
1 )通过一个类的全限定名来获取定义此类的二进制字节流。2 )将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。3 )在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口。
2) 验证
- 文件格式验证
- 字节码验证
- 符号引用验证...
3) 准备
4) 解析
5) 初始化
② 双亲委派模型


- 启动类加载器:加载 JDK 中 lib 目录中 Java 的核心类库,即$JAVA_HOME/lib目录。 扩展类加载器。加载 lib/ext 目录下的类。
- 应用程序类加载器:加载我们写的应用程序。
- 自定义类加载器:根据自己的需求定制类加载器。
1. 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。2. 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模 型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
③ 破坏双亲委派模型
public class JdbcTest {
public static void main(String[] args){
Connection connection = null;
try {
connection =
DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/test", "root",
"awakeyo");
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println(connection.getClass().getClassLoader());
System.out.println(Thread.currentThread().getContextClassLoader());
System.out.println(Connection.class.getClassLoader());
}
}

由双亲委派模型的加载流程可知 rt.jar 是有顶级父类 Bootstrap ClassLoader 加载的,如下图所示:
 文章来源:https://www.toymoban.com/news/detail-676410.html
文章来源:https://www.toymoban.com/news/detail-676410.html
@CallerSensitive
public static Connection getConnection(String url,
java.util.Properties info) throws SQLException {
return (getConnection(url, info, Reflection.getCallerClass()));
}
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws
SQLException {
ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;
synchronized(DriverManager.class) {
// synchronize loading of the correct classloader.
if (callerCL == null) {
//获取线程上下为类加载器
callerCL = Thread.currentThread().getContextClassLoader();
}
}
if(url == null) {
throw new SQLException("The url cannot be null", "08001");
}
println("DriverManager.getConnection(\"" + url + "\")");
SQLException reason = null;
for(DriverInfo aDriver : registeredDrivers) {
// isDriverAllowed 对于 mysql 连接 jar 进行加载
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
println(" trying " +
aDriver.driver.getClass().getName());
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " +
aDriver.driver.getClass().getName());
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
if (reason != null) {
println("getConnection failed: " + reason);
throw reason;
}
println("getConnection: no suitable driver found for "+ url);
throw new SQLException("No suitable driver found for "+ url, "08001");
}

五、垃圾回收相关
① 死亡对象的判断算法
a) 引用计数算法
/**
* JVM参数 :-XX:+PrintGC
* @author 38134
*
*/
public class Test {
public Object instance = null;
private static int _1MB = 1024 * 1024;
private byte[] bigSize = new byte[2 * _1MB];
public static void testGC() {
Test test1 = new Test();
Test test2 = new Test();
test1.instance = test2;
test2.instance = test1;
test1 = null;
test2 = null;
// 强制jvm进行垃圾回收
System.gc();
}
public static void main(String[] args) {
testGC();
}
}[GC (System.gc()) 6092K->856K(125952K), 0.0007504 secs]b) 可达性分析算法

1. 虚拟机栈 ( 栈帧中的本地变量表 ) 中引用的对象;2. 方法区中类静态属性引用的对象;3. 方法区中常量引用的对象;4. 本地方法栈中 JNI(Native 方法 ) 引用的对象。
② 垃圾回收算法
a) 标记-清除算法

b) 复制算法

1. 当 Eden 区满的时候 , 会触发第一次 Minor gc, 把还活着的对象拷贝到 Survivor From 区;当Eden 区再次触发 Minor gc 的时候 , 会扫描 Eden 区和 From 区域 , 对两个区域进行垃圾回收 , 经过这次回收后还存活的对象 , 则直接复制到 To 区域 , 并将 Eden 和 From 区域清空。2. 当后续 Eden 又发生 Minor gc 的时候 , 会对 Eden 和 To 区域进行垃圾回收 , 存活的对象复制到From 区域 , 并将 Eden 和 To 区域清空。3. 部分对象会在 From 和 To 区域中复制来复制去 , 如此交换 15 次 ( 由 JVM 参数MaxTenuringThreshold 决定 , 这个参数默认是 15), 最终如果还是存活 , 就存入到老年代
 文章来源地址https://www.toymoban.com/news/detail-676410.html
文章来源地址https://www.toymoban.com/news/detail-676410.html
c) 标记-整理算法

d) 分代算法
- 新生代:一般创建的对象都会进入新生代;
- 老年代:大对象和经历了 N 次(一般情况默认是 15 次)垃圾回收依然存活下来的对象会从新生代移动到老年代。
1. Minor GC 又称为新生代 GC : 指的是发生在新生代的垃圾收集。因为 Java 对象大多都具备朝生夕灭的特性,因此Minor GC( 采用复制算法 ) 非常频繁,一般回收速度也比较快。2. Full GC 又称为 老年代 GC 或者 Major GC : 指发生在老年代的垃圾收集。出现了 Major GC ,经常会伴随至少一次的Minor GC( 并非绝对,在 Parallel Scavenge 收集器中就有直接进行 Full GC的策略选择过程 ) 。 Major GC 的速度一般会比 Minor GC 慢 10 倍以上。
③ 垃圾收集器

- 并行(Parallel) : 指多条垃圾收集线程并行工作,用户线程仍处于等待状态
- 并发(Concurrent) : 指用户线程与垃圾收集线程同时执行(不一定并行,可能会交替执行),用户程序继续运行,而垃圾收集程序在另外一个CPU上。
- 吞吐量:就是CPU用于运行用户代码的时间与CPU总消耗时间的比值。

为什么会有这么多垃圾收集器?
a) Serial收集器(新生代收集器,串行GC)

b) ParNew收集器(新生代收集器,并行GC)

c) Parallel Scavenge收集器(新生代收集器,并行GC)
XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间
XX:GCRatio 直接设置吞吐量的大小
d) Serial Old收集器(老年代收集器,串行GC)【选学】

e) Parallel Old收集器(老年代收集器,并行GC)

f) CMS收集器(老年代收集器,并发GC)

g) G1收集器(唯一一款全区域的垃圾回收器)



④ 总结:一个对象的一生

六、JMM
① 主内存与工作内存

② 内存间交互操作
- lock(锁定) : 作用于主内存的变量,它把一个变量标识为一条线程独占的状态
- unlock(解锁) : 作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取) : 作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。
- load(载入) : 作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用) : 作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎。
- assign(赋值) : 作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量。
- store(存储) : 作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便后续的write操作使用。
- write(写入) : 作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
③ volatile型变量的特殊规则
package com.company;
public class Main {
public static volatile int num = 0;
public static void increase() {
num++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[10];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 100; j++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(num);
}
}1. 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值2. 变量不需要与其他的状态变量共同参与不变约束
volatile boolean shutdownRequested;
public void shutdown() {
shutdownRequested = true;
}
public void work() {
while(!shutdownRequested) {
//do stuff
}
}//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5Map configOptions;
char[] configText;
volatile boolean initialized = false;
//假设以下代码在线程A执行
//模拟读取配置文件信息,当读取完成后将initialized设置为true以通知其他线程配置可用
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText,configOptions);
initialized = true;
//假设以下代码在线程B执行
//等待initialized为true,代表线程A已经把配置信息初始化完成
while(!initialized) {
sleep();
}
//使用线程A初始化好的配置信息
doSomethingWithConfig();public static Singleton getSingleton(){
if(instance==null){ //Single Checked
synchronized (Singleton.class){
if(instance==null){ //Double Checked
instance=new Singleton();
}
}
}
return instance;
}class Singleton{
// 确保产生的对象完整性
private volatile static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if(instance==null) { // 检查对象是否初始化
synchronized (Singleton.class) {
if(instance==null) // 确保多线程情况下对象只有一个
instance = new Singleton();
}
}
return instance;
}
}到了这里,关于什么是JVM ?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!







![java八股文面试[JVM]——JVM参数](https://imgs.yssmx.com/Uploads/2024/02/667453-1.png)



