tip:作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。
推荐:体系化学习Java(Java面试专题)
一、ConcurrentHashMap 底层原理
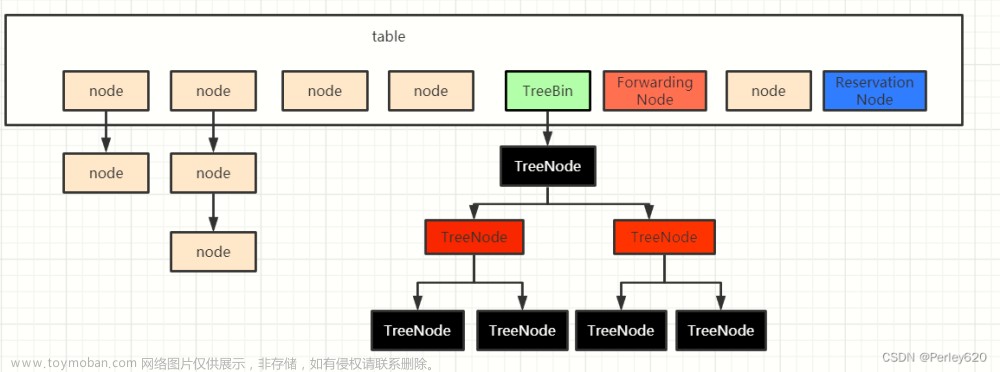
ConcurrentHashMap 是线程安全的哈希表,它是 Java 并发包中提供的一种高效的并发 Map 实现。ConcurrentHashMap 底层采用了分段锁的机制,不同的段(Segment)可以被不同的线程同时访问,从而提高了并发性能。
ConcurrentHashMap 采用了数组 + 链表 + 红黑树的数据结构来实现哈希表。数组的每个元素都是一个段(Segment),每个段都是一个独立的哈希表,包含了若干个键值对。每个段都有自己的锁,不同的段可以被不同的线程同时访问,从而提高了并发性能。
ConcurrentHashMap 的 put 操作和 get 操作都是非常高效的,因为它们都可以并发进行,不需要对整个哈希表加锁。在进行 put 操作时,先根据 key 的哈希值找到对应的段,然后对该段加锁,再在该段中进行插入操作;在进行 get 操作时,也是先根据 key 的哈希值找到对应的段,然后对该段加锁,再在该段中进行查找操作。这样就可以实现高并发的插入和查找操作。
ConcurrentHashMap 的扩容过程也是非常高效的。当某个段的元素个数超过了阈值时,就会触发扩容操作。在进行扩容操作时,只需要对该段加锁,不需要对整个哈希表加锁。同时,扩容时只需要将旧的元素重新分配到新的段中即可,不需要像 HashMap 那样重新计算所有元素的哈希值,因此扩容的效率更高。
总之,ConcurrentHashMap 底层采用了分段锁的机制,不同的段可以被不同的线程同时访问,从而提高了并发性能。同时,它采用了数组 + 链表 + 红黑树的数据结构来实现哈希表,具有高效的插入、查找、扩容等操作。
二、ConcurrentHashMap在java8和java7它的实现一样吗?
Java 8 中的 ConcurrentHashMap 引入了新的实现方式,称为基于 CAS(Compare and Swap)的实现,相比于 Java 7 中的基于分段锁的实现,具有更好的性能表现。此外,Java 8 中的 ConcurrentHashMap 还引入了新的方法,如 forEach、reduce、search 等,使得对 ConcurrentHashMap 的操作更加方便和高效。但是,Java 7 中的 ConcurrentHashMap 仍然可以使用,并且在某些场景下,其性能表现可能更好。
总结:
java 8:CAS + 分段锁
java 7:分段锁
三、Java 8 ConcurrentHashMap 主要实现方式
Java 8 中的 ConcurrentHashMap 实现采用了基于 CAS 的方式,其主要实现逻辑如下:
-
ConcurrentHashMap 内部采用了一个数组来存储数据,每个数组元素称为一个“桶”,每个桶又是一个链表或红黑树,用于存储键值对。数组的大小会根据当前元素数量动态调整。
-
ConcurrentHashMap 中的每个桶都有一个链表或红黑树,用于存储键值对。当链表长度超过阈值(默认为 8)时,会将链表转换为红黑树,以提高查找效率。
-
ConcurrentHashMap 中的每个桶都有一个“基准计数”,用于记录该桶中键值对的数量。同时,每个线程都会维护一个“本地计数”,用于记录该线程向 ConcurrentHashMap 中插入的键值对数量。
-
ConcurrentHashMap 中的 put 操作会先根据 key 的哈希值找到对应的桶,然后对该桶进行加锁(采用了一种乐观锁的方式,即不断尝试 CAS 操作),如果加锁成功,则进行插入操作。插入操作包括两个步骤:首先将键值对插入到桶中,然后将“基准计数”加 1。如果加锁失败,则重试插入操作。
-
ConcurrentHashMap 中的 get 操作也会先根据 key 的哈希值找到对应的桶,然后对该桶进行加锁,如果加锁成功,则在该桶中查找对应的键值对。查找操作包括两个步骤:首先遍历链表或红黑树,查找对应的键值对;然后将“本地计数”加 1。如果加锁失败,则重试查找操作。
-
ConcurrentHashMap 中的扩容操作会将所有的桶都进行扩容,扩容时会对每个桶进行加锁,不同的桶可以被不同的线程同时扩容。扩容操作包括两个步骤:首先将旧桶中的键值对重新分配到新桶中,然后将“基准计数”更新为新桶中键值对的数量。
总之,Java 8 中的 ConcurrentHashMap 实现采用了基于 CAS 的方式,同时引入了一些新的优化,如红黑树、基准计数、乐观锁等,使得其性能得到了很大的提升。文章来源:https://www.toymoban.com/news/detail-676587.html
四、应用
package com.pany.camp.base;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 插入数据
map.put("apple", 1);
map.put("banana", 2);
map.put("cherry", 3);
// 获取数据
System.out.println("apple: " + map.get("apple"));
System.out.println("banana: " + map.get("banana"));
System.out.println("cherry: " + map.get("cherry"));
// 遍历数据
map.forEach((key, value) -> System.out.println(key + ": " + value));
}
}
我们创建了一个 ConcurrentHashMap 对象,并向其中插入了三个键值对。然后,我们分别使用 get 方法获取了这三个键对应的值,并使用 forEach 方法遍历了整个 ConcurrentHashMap。这个例子展示了 ConcurrentHashMap 的基本用法,包括插入、获取和遍历数据。由于 ConcurrentHashMap 是线程安全的,因此在多线程环境下使用时,不需要额外的同步措施,可以保证数据的一致性和正确性。文章来源地址https://www.toymoban.com/news/detail-676587.html
到了这里,关于【Java 基础】ConcurrentHashMap 底层原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!