提高wasm性能的途径包括 : 编译期优化标志,使用多线程,使用SIMD内在函数()和wasm_webgpu等 SIMD是其中一个方向。
SIMD
SIMD(单指令多数据流)即一条指令可以一次处理多个数据,属于数据级并行优化手段。SIMD在X86、ARM CPU架构下都有相应的指令集实现。Flynn分类法根据指令和数据进入CPU的方式,将计算机架构分为四种不同的类型
- 单指令流单数据流(SISD, Single Instruction stream Single Data stream)
- 单指令流多数据流(SIMD, Single Instruction stream Multiple Data stream)
- 多指令流单数据流(MISD, Multiple Instruction stream Single Data stream)
- 多指令流多数据流(MIMD, Multiple Instruction stream Multiple Data stream)
| Data Stream | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Single | Multiple | ||||||||
| Instruction Stream |
Single | SISD a_1+b_1 |
SIMD a_1+b_1 a_2+b_2 a_3+b_3 |
||||||
| Multiple | SIMT a_1+b_1 a_1*b_1 a_1-b_1 |
MIMD a_1+b_1 a_2*b_2 a_3-b_3 |
|||||||
SIMD Elements per Data Type
由于通常没有内建的128bit和256bit数据类型,SIMD指令使用自己构建的数据类型,这些类型以union实现,这些数据类型可以称作向量,一般来说,MMX指令是__m64 类型的数据,SSE是__m128类型(一次操作128bit数据,128bit = 16byte = 4*float)的数据等等。
| char | short | int | int64_t | float | double | |
|---|---|---|---|---|---|---|
| MMX | 8 | 4 | 2 | 1 | 0 | 0 |
| SSE | 0 | 0 | 0 | 0 | 4 | 0 |
| SSE2 | 16 | 8 | 4 | 2 | 4 | 2 |
| AVX | 16 | 8 | 4 | 2 | 8 | 4 |
| AVX2 | 32 | 16 | 8 | 4 | 8 | 4 |
| AVX512F | 32 | 16 | 16 | 8 | 16 | 8 |
| AVX512BW | 64 | 32 | 16 | 8 | 16 | 8 |
| Data type | Intrinsic prefex | |
|---|---|---|
| SSE |
__m128 (float)
__m128d (double)
__m128i (int)
|
_mm_ |
| AVX |
__m256 (float) __m256d (double) __m256i (int) |
_mm256_ |
| AVX512 |
__m512 (float) __m512d (double) __m512i (int) |
_mm512_ |
函数指南
-
https://chryswoods.com/vector_c++/immintrin.html
-
x86/x64 SIMD Instruction List (SSE to AVX512)
-
有关每个 SSE 内在函数的详细信息,请访问优秀的SSE1 英特尔内在函数指南。
-
www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
-
WebAssembly中simd使用调研
x86 SIMD 内在函数的头文件 immintrin.h
- 当前,通常可以只使用<immintrin.h>. 它包括一切。
- 从历史上看(在immintrin.h拉入所有内容之前),您必须手动包含所需的最高级别内在函数的标头。这对于 MSVC 和 ICC 仍然有用,可以阻止您使用不需要的指令集。
<mmintrin.h> MMX
<xmmintrin.h> SSE
<emmintrin.h> SSE2
<pmmintrin.h> SSE3
<tmmintrin.h> SSSE3
<smmintrin.h> SSE4.1
<nmmintrin.h> SSE4.2
<ammintrin.h> SSE4A
<wmmintrin.h> AES
<immintrin.h> AVX, AVX2, FMA
例子
float input1[4] = { 1.2f, 3.5f, 1.7f, 2.8f };
float input2[4] = { -0.7f, 2.6f, 3.3f, -0.8f };
float output[4];
__m128 a = _mm_load_ps(input1);// https://www.csie.ntu.edu.tw/~r89004/hive/sse/page_4.html 要注意的是,這裡是假設這兩個浮點數陣列都是對齊在 16 bytes 的邊上。如果不是的話,就不能用 _mm_load_ps 這個 intrinsic 來載入,而要改用 _mm_loadu_ps 這個 intrinsic。它是專門用來處理沒有對齊在 16 bytes 邊上的資料的。但是,它的速度會比較慢。
__m128 b = _mm_load_ps(input2);
__m128 t = _mm_add_ps(a, b);
_mm_store_ps(output, t);
另外,因為 x86 的 little endian 特性,位址較低的 byte 會放在暫存器的右邊。也就是說,若以上面的 input1 為例,在載入到 XMM 暫存器後,暫存器中的 DATA0 會是 1.2,而 DATA1 是 3.5,DATA2 是 1.7,DATA3 是 2.8。如果需要以相反的順序載入的話,可以用 _mm_loadr_ps 這個 intrinsic。當然,在這個例子中,順序並不影響結果,所以不需要利用這個 intrinsic。
一般來說,宣告一個 float 的陣列,並不會對齊在 16 bytes 的邊上。如果希望它會對齊在 16 bytes 的邊上,以便利用 SSE 指令的話,Visual C++ 6.0 Processor Pack 和 Intel C++ compiler 都可以指定對齊方式。指定的方式如下:
__declspec(align(16)) float input1[4];
WebAssembly+SIMD
-
https://emscripten.org/docs/porting/simd.html
-
目前仅支持 SSE1、SSE2、SSE3、SSSE3、SSE4.1、SSE4.2 和 128 位 AVX 指令集。
-
使用 WebAssembly LLVM 后端时,Emscripten 支持WebAssembly SIMD 建议。要启用 SIMD,请在编译时传递
-msimd128标志。这还将打开 LLVM 的自动矢量化通道,因此无需修改源代码即可从 SIMD 中受益。 -
在源代码级别,可以使用GCC/Clang SIMD 矢量扩展,并将在可能的情况下降低为 WebAssembly SIMD 指令。此外,还有一个可以使用的可移植内在函数头文件
#include <wasm_simd128.h>。 -
内在函数头的单独文档正在开发中,但其用法很简单,其源代码可以在wasm_simd128.h中找到。这些内在函数正在与 SIMD 提案同时积极开发,不应被视为比提案本身更稳定。请注意,大多数引擎还需要一个额外的标志来启用 SIMD。例如,Node 需要–experimental-wasm-simd。
-
Emscripten 支持通过将-msse指令传递给编译器并包含头文件
<xmmintrin.h>来编译使用 x86 SSE 的现有代码库(编译针对 x86 SSE 指令集的 SIMD 代码)。
code
1.编译针对 x86 SSE 指令集的 SIMD 代码
// 将两个数组a和b的元素逐个相乘,并将结果存储在数组c中。函数使用了AVX指令集中的256位浮点数寄存器__m256来进行向量化计算
void multiply(void) {
unsigned i;
__m256 A, B, C;
for(i=0; i<(N & ((~(unsigned)0x7))); i+=8) {// 循环的终止条件是i小于数组长度N并且i是8的倍数,这是因为AVX指令集中的256位浮点数寄存器可以同时处理8个单精度浮点数。
A = _mm256_load_ps(&a[i]);
B = _mm256_load_ps(&b[i]);
C = _mm256_mul_ps(A, B);
_mm256_store_ps(&c[i], C);// 使用_mm256_store_ps函数将寄存器C中的结果存储回数组c
}
for(; i<N; i++) {// 如果数组长度N不是8的倍数,那么循环结束后还会有一些元素没有被处理到。因此,函数使用另一个循环来处理剩下的元素。在这个循环中,函数直接将数组a和b中对应位置的元素相乘,并将结果存储在数组c中。
c[i] = a[i] * b[i];
}
}
- 完整代码
// https://juejin.cn/post/7091571543239000078
// emcc main.c -s ALLOW_MEMORY_GROWTH=1 -Os -msimd128 -msse -D USE_SSE -o wasm_sse_os.html
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "sys/time.h"
// simd内置函数 头文件
#include <immintrin.h>
#define N 178257920 // 170M
#define SEED 0x1234
float *a, *b, *c;
#if defined(NORMAL)
// 为3个float数组分配内存,每个数组包含 170 * 1024 * 1024 个元素
void gen_data(void) {
unsigned i;
a = (float*) malloc(N*sizeof(float));
b = (float*) malloc(N*sizeof(float));
c = (float*) malloc(N*sizeof(float));
srand(SEED);
for(i=0; i<N; i++) {
a[i] = b[i] = (float)(rand() % N);
}
}
void free_data(void) {
free(a);
free(b);
free(c);
}
void multiply(void) {
unsigned i;
for(i=0; i<N; i++) {
c[i] = a[i] * b[i];
}
}
#elif defined(USE_SSE)
void gen_data(void) {
unsigned i;
a = (float*) _mm_malloc(N*sizeof(float), 16);
b = (float*) _mm_malloc(N*sizeof(float), 16);
c = (float*) _mm_malloc(N*sizeof(float), 16);
srand(SEED);
for(i=0; i<N; i++) {
a[i] = b[i] = (float)(rand() % N);
}
}
void free_data(void) {
_mm_free(a);
_mm_free(b);
_mm_free(c);
}
void multiply(void) {
unsigned i;
__m128 A, B, C; // 向量类型 __m128 = 4xfloat
for(i=0; i<(N & ((~(unsigned)0x3))); i+=4) {
A = _mm_load_ps(&a[i]);
B = _mm_load_ps(&b[i]);
C = _mm_mul_ps(A, B);
_mm_store_ps(&c[i], C);
}
for(; i<N; i++) {
c[i] = a[i] * b[i];
}
}
#elif defined(USE_AVX)
void gen_data(void) {
unsigned i;
a = (float*) _mm_malloc(N*sizeof(float), 32);
b = (float*) _mm_malloc(N*sizeof(float), 32);
c = (float*) _mm_malloc(N*sizeof(float), 32);
srand(SEED);
for(i=0; i<N; i++) {
a[i] = b[i] = (float)(rand() % N);
}
}
void free_data(void) {
_mm_free(a);
_mm_free(b);
_mm_free(c);
}
// 将两个数组a和b的元素逐个相乘,并将结果存储在数组c中。函数使用了AVX指令集中的256位浮点数寄存器__m256来进行向量化计算
void multiply(void) {
unsigned i;
__m256 A, B, C;
for(i=0; i<(N & ((~(unsigned)0x7))); i+=8) {// 循环的终止条件是i小于数组长度N并且i是8的倍数,这是因为AVX指令集中的256位浮点数寄存器可以同时处理8个单精度浮点数。
A = _mm256_load_ps(&a[i]);
B = _mm256_load_ps(&b[i]);
C = _mm256_mul_ps(A, B);
_mm256_store_ps(&c[i], C);// 使用_mm256_store_ps函数将寄存器C中的结果存储回数组c
}
for(; i<N; i++) {// 如果数组长度N不是8的倍数,那么循环结束后还会有一些元素没有被处理到。因此,函数使用另一个循环来处理剩下的元素。在这个循环中,函数直接将数组a和b中对应位置的元素相乘,并将结果存储在数组c中。
c[i] = a[i] * b[i];
}
}
#endif
void print_data(void) {
printf("%f, %f, %f, %f\n", c[0], c[1], c[N-2], c[N-1]);
}
gettimeofday();
int main(void) {
double start=0.0, stop=0.0, msecs;
struct timeval before, after;
printf("gen data start... \n");
gen_data();
printf("gen data end... \n");
gettimeofday(&before, NULL);
multiply();
gettimeofday(&after, NULL);
msecs = (after.tv_sec - before.tv_sec)*1000.0 + (after.tv_usec - before.tv_usec)/1000.0;
print_data();
printf("Execution time = %2.3lf ms\n", msecs);
free_data();
return 0;
}
2.使用<wasm_simd128.h>方式
- https://jeromewu.github.io/improving-performance-using-webassembly-simd-intrinsics/
#include<stdio.h>
#include<time.h>
#include <wasm_simd128.h>
void multiply_mats(int* out, int* in_a, int* in_b, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
out[i*n+j] = 0;
int sum_arr[] = {0, 0, 0, 0};
v128_t sum = wasm_v128_load(sum_arr);
for (int k = 0; k < n; k+=4) {
v128_t a = wasm_v128_load(&in_a[i*n+k]);
v128_t b = wasm_v128_load(&in_b[j*n+k]);
v128_t prod = wasm_i32x4_mul(a, b);
sum = wasm_i32x4_add(sum, prod);
}
v128_t sum_duo = wasm_i32x4_add(sum, wasm_i32x4_shuffle(sum, sum, 2, 3, 0, 0));
v128_t sum_one = wasm_i32x4_add(sum_duo, wasm_i32x4_shuffle(sum_duo, sum_duo, 1, 0, 0, 0));
out[i*n+j] += wasm_i32x4_extract_lane(sum_one, 0);
}
}
}
$:~/ggml/ggml/examples/mnist/web$ emcc new.cpp -o new.js
new.cpp:10:20: error: always_inline function 'wasm_v128_load' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
10 | v128_t sum = wasm_v128_load(sum_arr);
| ^
new.cpp:12:16: error: always_inline function 'wasm_v128_load' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
12 | v128_t a = wasm_v128_load(&in_a[i*n+k]);
| ^
new.cpp:13:16: error: always_inline function 'wasm_v128_load' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
13 | v128_t b = wasm_v128_load(&in_b[j*n+k]);
| ^
new.cpp:14:19: error: always_inline function 'wasm_i32x4_mul' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
14 | v128_t prod = wasm_i32x4_mul(a, b);
| ^
new.cpp:15:15: error: always_inline function 'wasm_i32x4_add' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
15 | sum = wasm_i32x4_add(sum, prod);
| ^
new.cpp:17:44: error: '__builtin_wasm_shuffle_i8x16' needs target feature simd128
17 | v128_t sum_duo = wasm_i32x4_add(sum, wasm_i32x4_shuffle(sum, sum, 2, 3, 0, 0));
| ^
/home/pdd/Downloads/emsdk/upstream/lib/clang/17/include/wasm_simd128.h:1445:12: note: expanded from macro 'wasm_i32x4_shuffle'
1445 | ((v128_t)__builtin_wasm_shuffle_i8x16( \
| ^
new.cpp:17:24: error: always_inline function 'wasm_i32x4_add' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
17 | v128_t sum_duo = wasm_i32x4_add(sum, wasm_i32x4_shuffle(sum, sum, 2, 3, 0, 0));
| ^
new.cpp:18:48: error: '__builtin_wasm_shuffle_i8x16' needs target feature simd128
18 | v128_t sum_one = wasm_i32x4_add(sum_duo, wasm_i32x4_shuffle(sum_duo, sum_duo, 1, 0, 0, 0));
| ^
/home/pdd/Downloads/emsdk/upstream/lib/clang/17/include/wasm_simd128.h:1445:12: note: expanded from macro 'wasm_i32x4_shuffle'
1445 | ((v128_t)__builtin_wasm_shuffle_i8x16( \
| ^
new.cpp:18:24: error: always_inline function 'wasm_i32x4_add' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
18 | v128_t sum_one = wasm_i32x4_add(sum_duo, wasm_i32x4_shuffle(sum_duo, sum_duo, 1, 0, 0, 0));
| ^
new.cpp:19:21: error: always_inline function 'wasm_i32x4_extract_lane' requires target feature 'simd128', but would be inlined into function 'multiply_mats' that is compiled without support for 'simd128'
19 | out[i*n+j] += wasm_i32x4_extract_lane(sum_one, 0);
| ^
10 errors generated.
emcc: error: '/home/pdd/Downloads/emsdk/upstream/bin/clang++ -target wasm32-unknown-emscripten -fignore-exceptions -fvisibility=default -mllvm -combiner-global-alias-analysis=false -mllvm -enable-emscripten-sjlj -mllvm -disable-lsr -DEMSCRIPTEN --sysroot=/home/pdd/Downloads/emsdk/upstream/emscripten/cache/sysroot -Xclang -iwithsysroot/include/fakesdl -Xclang -iwithsysroot/include/compat new.cpp -c -o /tmp/emscripten_temp_28ovmxxx/new_0.o' failed (returned 1)
$:~/ggml/ggml/examples/mnist/web$ emcc new.cpp -o new.js -msimd128
$:~/ggml/ggml/examples/mnist/web$ node new.js
multiply matrixs: 3.378s
$:~/ggml/ggml/examples/mnist/web$ emcc new.cpp -o new.js -O3 -msimd128
cache:INFO: generating system asset: symbol_lists/e0d283f526f4ef916e7ac46fde880e1f497e1610.json... (this will be cached in "/home/pdd/Downloads/emsdk/upstream/emscripten/cache/symbol_lists/e0d283f526f4ef916e7ac46fde880e1f497e1610.json" for subsequent builds)
cache:INFO: - ok
$:~/ggml/ggml/examples/mnist/web$ node new.js
multiply matrixs: 0.338s
限制和行为差异
-
Emscripten 不支持 x86 或任何其他本机内联 SIMD 程序集或构建 .s 程序集文件,因此应编写所有代码以使用 SIMD 内部函数或编译器向量扩展。
-
WebAssembly SIMD 无法控制管理浮点舍入模式或处理非正规数。
-
缓存行预取指令不可用,对这些函数的调用将编译,但被视为无操作。文章来源:https://www.toymoban.com/news/detail-677257.html
-
非对称内存栅栏操作不可用,但在启用 SharedArrayBuffer (-pthread) 时将实现为完全同步内存栅栏,或者在未启用多线程(默认)时实现为无操作。文章来源地址https://www.toymoban.com/news/detail-677257.html
CG
- https://blog.csdn.net/qq_32916805/article/details/117637192
- https://www.uio.no/studier/emner/matnat/ifi/IN3200/v19/teaching-material/avx512.pdf
- 头文件 immintrin.h : https://stackoverflow.com/questions/11228855/header-files-for-x86-simd-intrinsics
- https://www.tommesani.com/Docs.html
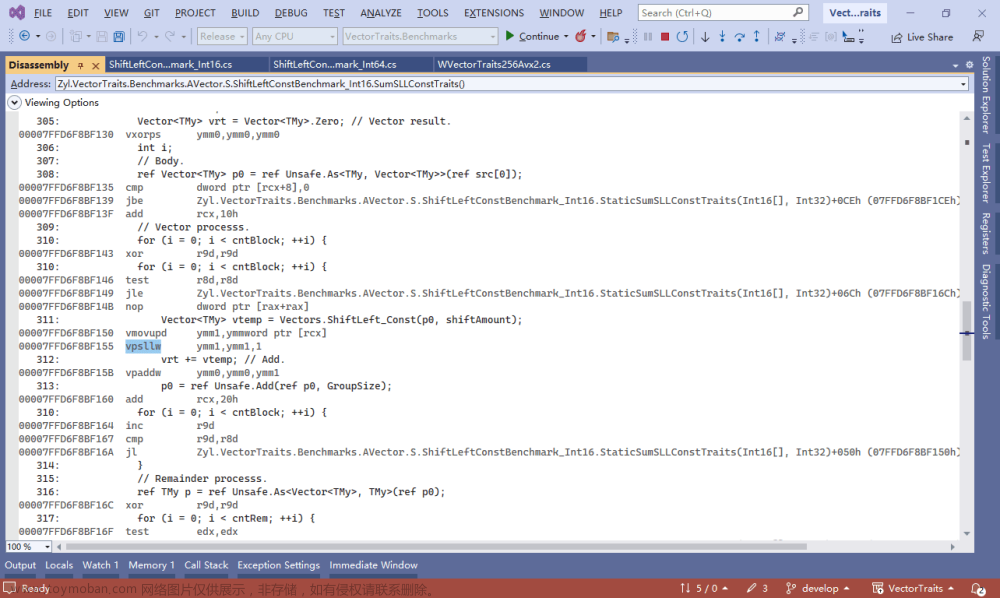
- SIMD指令编程demo
- https://zzqcn.github.io/perf/simd_demo.html
- 【manim】动画演示SSE指令集SIMD intrinsics(第二期:整数篇)
- [GSoC 2020] OpenCV.js: WASM SIMD optimization 2.0
- meshoptimizer: WebAssembly SIMD
- AssemblyScript A TypeScript-like language for WebAssembly
到了这里,关于webassembly006 SIMD 矢量运算的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!