「作者主页」:士别三日wyx
「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者
「推荐专栏」:小白零基础《Python入门到精通》

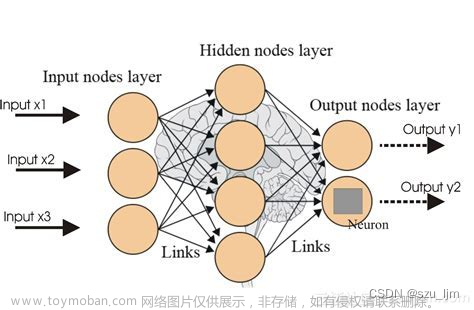
决策树是一种 「二叉树形式」的预测模型,每个 「节点」对应一个 「判断条件」, 「满足」上一个条件才能 「进入下一个」判断条件。
就比如找对象,第一个条件肯定是长得帅,长得帅的才考虑下一个条件;长得不帅就直接pass,不往下考虑了。

决策树的「核心」在于:如何找到「最高效」的「决策顺序」。
1、决策树API
sklearn.tree.DecisionTreeClassifier() 是决策树分类算法的API
参数
- criterion:(可选)衡量分裂的质量,可选值有
gini、entropy、log_loss,默认值gini - splitter:(可选)给每个节点选择分割的策略,可选值有
best、random,默认值best - max_depth:(可选)树的最大深度,默认值
None - min_samples_split:(可选)分割节点所需要的的最小样本数,默认值 2
- min_samples_leaf:(可选)叶节点上所需要的的最小样本数,默认值 1
- min_weight_fraction_leaf:(可选)叶节点的权重总和的最小加权分数,默认值 0.0
- max_features:(可选)寻找最佳分割时要考虑的特征数量,默认值
None - random_state:(可选)控制分裂特征的随机数,默认值
None - max_leaf_nodes:(可选)最大叶子节点数,默认值
None - min_impurity_decrease:(可选)如果分裂指标的减少量大于该值,就进行分裂,默认值 0.0
- class_weight:(可选)每个类的权重,默认值
None - ccp_alpha:(可选)将选择成本复杂度最大且小于ccp_alpha的子树。默认情况下,不执行修剪。
函数
- fit( x_train, y_train ):接收训练集特征 和 训练集目标
- predict( x_test ):接收测试集特征,返回数据的类标签。
- score( x_test, y_test ):接收测试集特征 和 测试集目标,返回准确率。
- predict_log_proba():预测样本的类对数概率
属性
- classes_:类标签
- feature_importances_:特征的重要性
- max_features_:最大特征推断值
- n_classes_:类的数量
- n_features_in_:特征数
- feature_names_in_:特征名称
- n_outputs_:输出的数量
- tree_:底层的tree对象
2、决策时实际应用
2.1、获取数据集
这里使用sklearn自带的鸢尾花数据集进行演示。
from sklearn import datasets
# 1、获取数据集
iris = datasets.load_iris()
2.2、划分数据集
传入数据集的特征值和目标值,按照默认的比例划分数据集。
from sklearn import datasets
from sklearn import model_selection
# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
2.3、决策树处理
实例化对象,传入训练集特征值和目标值,开始训练。
from sklearn import datasets
from sklearn import model_selection
from sklearn import tree
# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
# # 3、决策树处理
estimator = tree.DecisionTreeClassifier()
estimator.fit(x_train, y_train)
2.4、模型评估
对比测试集,验证准确率。
from sklearn import datasets
from sklearn import model_selection
from sklearn import tree
# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
# # 3、决策树处理
estimator = tree.DecisionTreeClassifier()
estimator.fit(x_train, y_train)
# # 4、模型评估
y_predict = estimator.predict(x_test)
print('对比真实值和预测值', y_test == y_predict)
score = estimator.score(x_test, y_test)
print('准确率:', score)
输出:文章来源:https://www.toymoban.com/news/detail-677302.html
对比真实值和预测值 [ True True True True True False True True True True True True
False True True True True True True True True True True True
True True True True True True True True True True True True
True True]
准确率: 0.9473684210526315
从结果可以看到,准确率达到了94%文章来源地址https://www.toymoban.com/news/detail-677302.html
到了这里,关于《机器学习核心技术》分类算法 - 决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!