联邦学习中的安全多方计算
Secure Multi-party Computation in Federated Learning
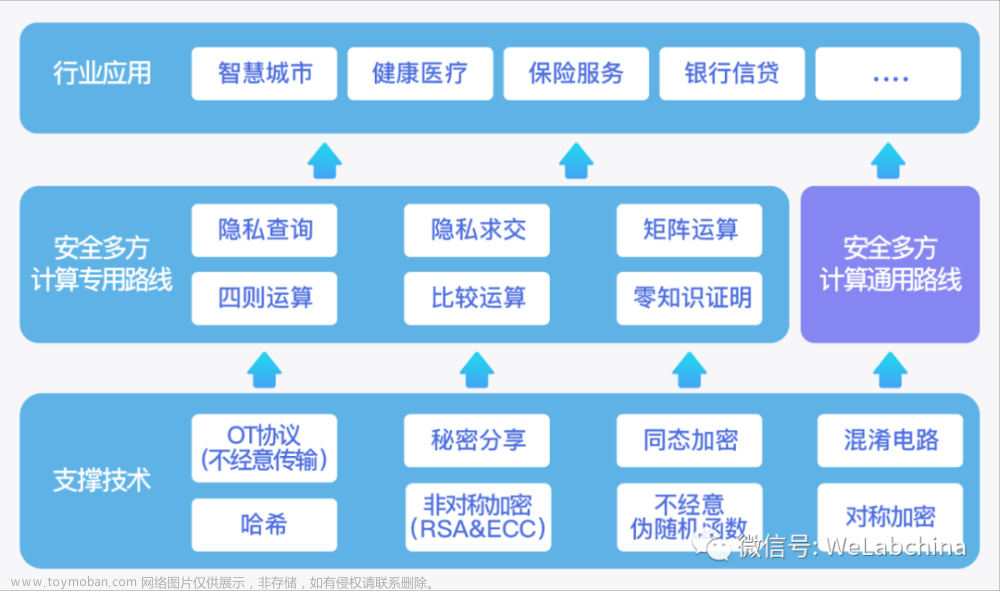
什么是安全多方计算
安全多方计算就是许多参与方需要共同工作完成一个计算任务或者执行一个数学函数,每个参与方针对这个执行构建自己的数据或份额,但不想泄露自己的数据给其他参与方。
在安全多方计算中的定义包括以下几个方面:
- 一组有私有输入的参与者,对他们的输入执行一些联合功能。
- 参与者希望保留一些安全属性,例如,选举协议中的隐私性和正确性。
- 安全性必须在面对某些参与者或外部各方的敌对行为时保持不变。
研究人员通常利用真实/理想的模型范式来探索安全协议的安全性。
- 在理想的模型中,安全性是绝对的,例如服务器是绝对可靠和可信的,并且对服务器进行成功攻击的概率为零。
- 在真实模型中,我们也可以通过各种方式来实现理想模型的安全性。任何可以从真实模型中学习或获得的信息敌手也可以从理想模型中学习或获得。换句话说,安全性在理想模型和真实模型之间是不可区分的。
举个例子:在理想模型中,假设有一个可信服务器能够聚合各参与方并且产生正确预期输出;在真实模型中,不存在可信服务器,参与方可以通过点对点方式交换输入和信息来达到这种形式。
安全多方计算中有三个安全模型:
- 半诚实敌手模型:被腐化的参与方忠实执行既定协议;而敌手尽可能收集所有信息以获得额外的机密信息
- 恶意敌手模型(强安全模型):腐化参与方可能在任何时候根据敌手指示违背协议。
- 隐蔽对手模型:介于上述两极端模型之间
安全多方计算的基础组件
不经意传输(茫然传输,Oblivious Transfer,OT)
不经意传输(OT):发送者S想发送n个消息中的一个给接受者R,目标是S不知道哪个消息被R接收,而且R没有获得S发送的其他n-1个消息中的任何信息。
一个标准的二选一函数被描述为\(F_{ot}\)如下:
- 输入:
- 发送方\(S\)输入两个消息\(m_1\), \(m_2\).
- 接收方输入一个随机比特\(\sigma \in [0,1]\).
- 输出:
- 发送方\(S\)没有输出.
- 接收方\(R\)获得\(m_\sigma\),并且没有获得关于\(m_{1-\sigma}\)的任何知识.
实现OT协议的方法有很多,例如RAS或基于离散对数问题的方法。
混淆电路
双方将共同协作实现:一方将设计一个逻辑电路,另一方将检查并使用该逻辑电路。
秘密共享
秘密共享(Secret Sharing, SS)是密码学中的一个重要元素。对称或非对称加密更侧重于两方之间的秘密共享。然而某些时候,例如在联邦学习中则需要在多个参与者之间共享一个秘密,此时就需要秘密共享。
一般来说,有三种类型的秘密共享协议:算术秘密共享、Shamir秘密共享和Goldreich-Micali-Wigderson(GMW)共享。算术秘密共享是利用数论的特征在两方之间共享一个秘密,而GMW共享主要使用XOR来隐藏私有值,而Shamir秘密共享可能是实践中最流行的秘密分享的原语。
在Shamir秘密共享中,一个秘密\(s\)将被分割成\(n\)个份额,这样任何\(t\)个份额都可以用来重建秘密\(s\);然而,任何小于\(t\)的份额都不能获得关于\(s\)的信息。
\((t,n)\)门限Shamir秘密共享方案:
由于每个参与者\(P_i\)都知道一对\((x_i,y_i)\),因此,当我们有\(t\)对\((x_i,y_i)\)时就可以获得秘密值\(K\)。然而,对于任意\(t-1\)对\((x_i,y_i)\),我们则不能确定\(K\)(给定一个很大的素数\(p\)有很多可能性)。
另一种流行的秘密共享方法是使用拉格朗日插值法。我们用一个简单的例子来说明这项技术。假设\(t=3\),那么我们找到一个阶数为3的多项式如下:
,其中\(d=f(0)\)是秘密值。
分配者可以在\(X\)轴上随机选择\(n\)个点,如\(x_1,x_2,...,x_n\)。根据\(a\)、\(b\)、\(c\)、\(d\)的知识,分配者可以轻松获得\(n\)对数据\((x_1,f(x_1)),(x_2,f(x_2)),...,(x_n,f(x_n))\)。然后他将把\(n\)对秘密份额分配给\(n\)个秘密持有人。
两种方法的主要区别:
- Shamir秘密共享是\(x_1\)到\(x_n\)是随机选取且公开的,之后随机选取\(t-1\)个多项式系数,求得y值进行分配,秘密份额是y值。需要分配方分发两次,一次公开的,一次秘密份额。
- 拉格朗日插值法是先找一个多项式,再随机选\(n\)个点,这样每个点(即\(x\)值和\(y\)值)共同作为秘密份额,\(x_1\)到\(x_n\)不公开。分配方只需要分发一次。
同态加密
目前同态加密的性能有很大挑战,阻碍了实践中的部署。
联邦学习中的安全多方计算
成对掩蔽技术(pairwise masking)数据聚合
假设我们有两个客户端\(u\)和\(v\),他们分别想将\(x_u\)和\(x_v\)上传到联邦学习服务器。为了不向服务器泄露他们的原始秘密值,\(u\)和\(v\)将协议产生一个虚拟数据\(s_{uv}\),其中一个客户端会将虚拟数据添加到真实数据中来输出,例如,\(y_u = x_u + s_{uv}\),而另一个客户端将输出\(y_v = x_v − s_{uv}\)。在服务器端,诚实但好奇的服务器通过将接收到的\(y_u\)和\(y_v\)相加,即可得到正确的聚合结果\(x_u + x_v\),与此同时服务器无法从接收到的消息中得到\(x_u\)和\(x_v\)。
对掩蔽方法进一步推广:假设有多个客户端参与该任务,使用客户端集合\(\mathcal{U}\)表示。我们将对集合中的每一对客户端\((u,v)\)生成一个共享的虚拟向量\(s_{uv}\)。此外我们还需要一个规则来决定谁将添加或减去共享的虚拟向量。一种解决方案是,我们随机地给每个客户端分配一个顺序,我们得到一个有序的用户列表\(1,2,...,|\mathcal{U}|\)。对于列表中的用户\(i\),他将添加用户\(1,2,...,i−1\)的共享虚拟向量,并减去与用户\(i + 1,i + 2,...,|\mathcal{U}|\)共享的虚拟向量。换句话说,用户\(u\)的掩码输出是:
我们注意到,上述掩蔽的正项或负项的数量是动态的,并取决于用户\(u\)在有序列表中的位置(每个不同位置的客户端正项和负项的数量都是不同的,但最后总和一定是互相抵消的,因为每个加减是成对出现的,例如客户端1要减掉其与客户端2共享的虚拟向量,客户端2要加上这个虚拟向量)。在服务器端,聚合的方式如下:
这里贴一下我理解的成对掩码加减的示意图,以便于理解:
此外注意:这里的每对客户端之间生成的虚拟向量应该是不保存的,直接加在真实值上面,因此如果发生掉线情况,就会出问题。
由于掩码是成对出现的,所以如果出现参与方掉线的情况就聚合之后的总和会出现问题,因此最重要的就是解决参与方掉线的问题。
联邦学习中的秘密共享
根据前文,可以使用秘密共享来解决客户端掉线问题。
在系统启动阶段,一个给定用户\(u\)将利用一个秘密共享方案来分发他的每个秘密值的\(t\)份额共享(\(u\)与其他用户之间有一个秘密值\(s_{uv},u \neq v\))。在掩蔽方案中,只有当所有预期的参与方都成功地上传了其所掩蔽的数据时,才能正确地完成聚合。否则,仅有部分参与方参与求和就远远不能得到正确的答案,因为一个缺失的参与者可能会导致很大的差异。
也就是说如果有一个客户端\(u\)掉线,那么与之相关的有\(n-1\)个秘密需要被恢复。而针对于用户\(u\)相关的其中一个秘密\(s_{u,v}\)来说,服务器至少需要从活跃参与方收集至少\(t\)个份额。即服务器总共需要手机\(t×(n-1)\)个份额才能完整复原所有与\(u\)有关的秘密值,从而使最终求和正确。这样开销显然太大了。
这里我本来有个疑问:此处为什么不用与他结对的客户端持有的值直接恢复?
我思考了一下之后觉得与它结对的客户端并不持有这个虚拟向量(我感觉这个虚拟向量就是个一次性的随机数),虚拟向量使用完之后两方都不存储。两方只是在生成之后根据这个虚拟向量值生成了秘密共享份额以备恢复它,但原始的虚拟向量值就销毁了,加完或减完只保留\(y_u\)值,不保留\(x_u\)值和\(s_{u,v}\)。
此外有一种潜在的攻击是服务器可能声称用户\(u\)掉线了(其实没掉线),从而获得客户端\(u\)的与其他客户端的所有\(n-1\)个秘密值(虚拟向量)。而攻击者可以通过这\(n-1\)个虚拟向量以及各个客户端上传的内容求得各个客户端持有的真实值(需要上传的真实值):
为了应对这种攻击,提出了一种双掩蔽方法(待后续学习)。
为了处理掉线带来的昂贵代价,Zheng等人提出了一个轻量级的加密解决方案:
 文章来源:https://www.toymoban.com/news/detail-677333.html
文章来源:https://www.toymoban.com/news/detail-677333.html
思路类似于DH密钥交换协议,每个客户端生成一个私钥和一个公钥,每两方通过密钥交换得到一个公共密钥,这个公共密钥就作为虚拟向量,这样子后续如果有一方掉线,而另一方知道这个公共密钥,可以直接恢复。文章来源地址https://www.toymoban.com/news/detail-677333.html
到了这里,关于联邦学习中的安全多方计算的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!