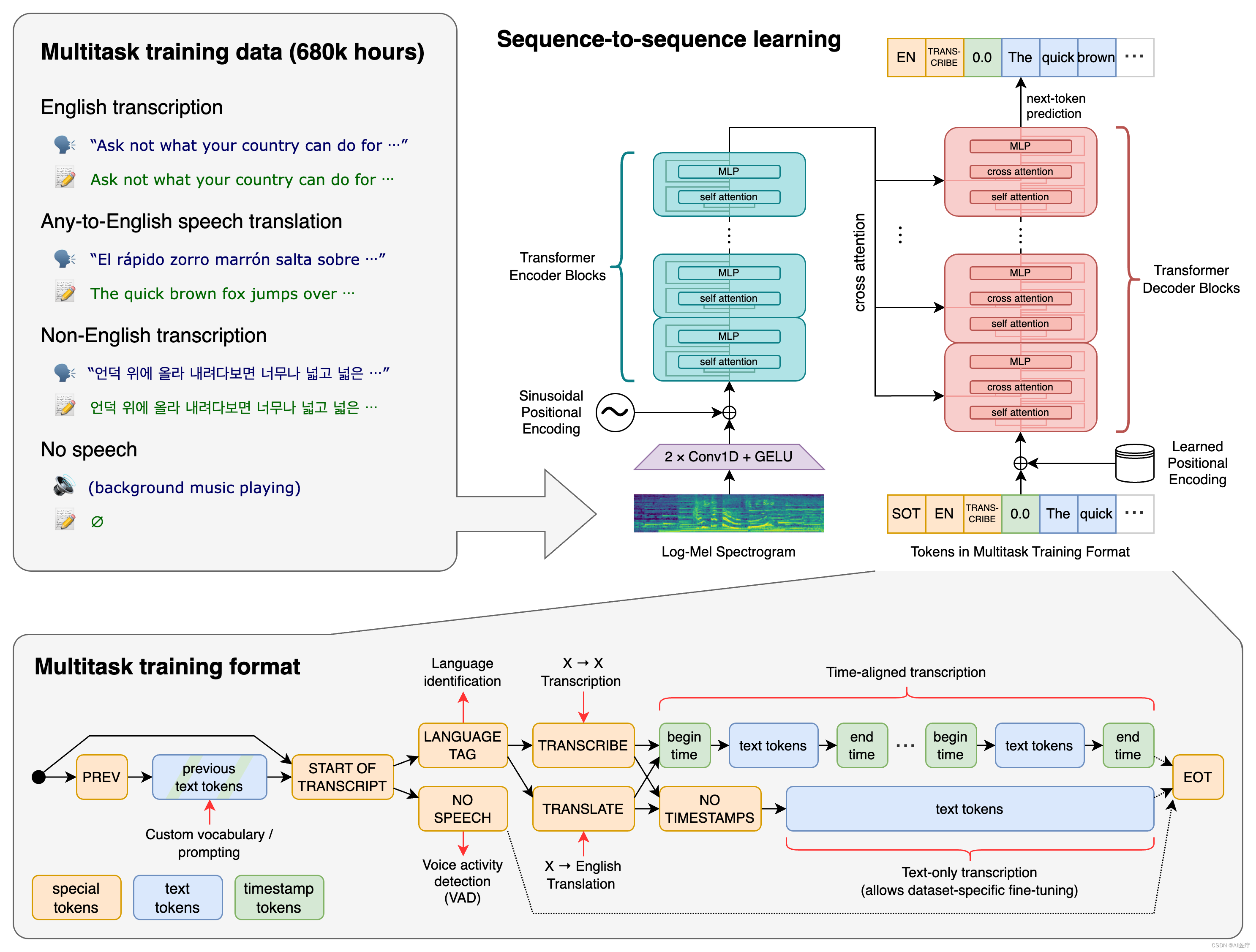
1. 首先安装依赖库
pip install playsound # 该库用于播放音频文件
pip install speech_recognition # 该库用于语音识别
pip install PocketSphinx # 语音识别模块中只有sphinx支持离线的,使用该模块需单独安装
pip install pyttsx3 # 该库用于将文本转换为语音播放
pip install comtypes # 该库可以从文本文件中获取输入转换为语音文件2. 播放音频文件
from playsound import playsound
playsound('audio_files\cnhello.mp3')3. 语音识别
默认只识别英文,如果需要支持中文,需要下载中文模型包,下载地址如下:
CMU Sphinx - Browse /Acoustic and Language Models at SourceForge.net

下载完解压到sphinx安装路径下:
D:\install\Anaconda\Lib\site-packages\speech_recognition\pocketsphinx-data


import speech_recognition as sr
r = sr.Recognizer()
harvard = sr.AudioFile('audio_files\harvard.wav')
with harvard as source:
# r.adjust_for_ambient_noise(source) # 消除环境背景音
audio = r.record(source) # record()函数,将整个音频文件读入AudioData实例
print(type(audio))
r.recognize_sphinx(audio) 4. 通过麦克风输入并识别
import speech_recognition as sr
mic = sr.Microphone()
with mic as source:
r.adjust_for_ambient_noise(source)
audio = r.listen(source)
r.recognize_sphinx(audio)5. 文本转语音播放
import pyttsx3
engine = pyttsx3.init()
engine.say("hello world")
engine.say("你好")
engine.runAndWait()
engine.stop()6. 文本转语音
# 文本转语音
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
engine = CreateObject("SAPI.SpVoice")
stream = CreateObject('SAPI.SpFileStream')
infile = 'demo.txt'
outfile = 'demo_audio.wav'
stream.open(outfile, SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream = stream
f = open(infile, 'r', encoding='utf-8')
theText = f.read()
f.close()
engine.speak(theText)
stream.close()7. 语音转文本(英文识别)
# 语音文件转文本文件
import speech_recognition as sr
r = sr.Recognizer()
harvard = sr.AudioFile('demo_audio.wav')
with harvard as source:
# r.adjust_for_ambient_noise(source)
audio = r.record(source)
r.recognize_sphinx(audio, language='en-US')
>>'hello everyone my name is bob'
8. 语音转文本(中文识别)
# 语音文件转文本文件
import speech_recognition as sr
r = sr.Recognizer()
harvard = sr.AudioFile('demo_audio.wav')
with harvard as source:
# r.adjust_for_ambient_noise(source)
audio = r.record(source)
r.recognize_sphinx(audio, language='zh-CN')
>> '好好 学习 天天 向上'
参考:
python实现语音识别功能文章来源:https://www.toymoban.com/news/detail-677851.html
从0开始语音识别文章来源地址https://www.toymoban.com/news/detail-677851.html
到了这里,关于python实现语音识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!