笔者的运行环境:python3.8+pytorch2.0.1+pycharm+kaggle
用到的网络框架:yolov5、crnn+ctc
项目地址:GitHub - WangPengxing/plate_identification: 利用yolov5、crnn+ctc进行车牌识别
1. 写在开始之前
在学习过目标检测和字符识别后想用yolov5、crnn+ctc做一个车牌识别项目,本意是参考大佬们的项目,怎奈钱包不允许。网上有关车牌检测的基本都是引流贴,甚至有的连用到的公共数据集都不放链接,索性我也不找了,直接找原始数据集,从头开始搞。
本文是一篇实战过程记录,仅记录我在车牌识别项目中的工作,不会牵涉过多理论知识。而且本次实战由于收集的数据集不太合适,导致效果较差,因此不建议读者直接搬用我收集的数据集。
2. 项目思路
功能:车牌识别分为车牌检测、识别两个部分,即先检测到车牌再识别检测到的车牌。不过我想在车牌检测、识别的基础上再加上车辆的检测,让项目变得更有意思一些。
思路一:找一个带有车辆、车牌标注的数据集,使用yolov5训练-->使用crnn+ctc网络训练车牌识别-->推理时将检测与识别组合在一起,以达到预期的功能。
可行性:没有找到合适的数据集,因此只能换一个思路了。
思路二:将车辆检测、车牌检测的训练分开,分别收集数据集,使用yolov5训练-->使用crnn+ctc网络训练车牌识别-->推理时将检测与识别组合在一起,以达到预期的功能。
可行性:数据集的收集较为容易,但是推理阶段的组合变得困难了。
3. 项目数据集
3.1. 车辆检测数据集
数据集名称:BITVehicle_data
数据集简介:北京理工大学实验室放出来的数据集,该数据集包含6个类别:公共汽车、微型巴士、小型货车、轿车、SUV和卡车,共9850张图片。数据集中不同时间和地点的两个相机捕获了大小为 16001200和 19201080的图像。图像包含照明条件、比例、车辆表面颜色和视点的变化。由于捕获延迟和车辆的大小,某些车辆的顶部或底部不包括在图像中。不过该数据集的标注是以.mat形式保存的,因此需要先转为适合yolov5的格式。
数据集预处理:将标注转为**.txt**格式;将源数据集分为训练数据集和评估数据集,train:val=6000:3850
import scipy.io as sio
import random
from shutil import copyfile
def label_process(root, val_num):
base_dir = root
load_fn = base_dir + "labels/VehicleInfo.mat"
load_data = sio.loadmat(load_fn)
data = load_data['VehicleInfo']
val_index = random.sample(range(data.size), val_num)
for i in range(len(data)):
item = data[i]
str = ""
print("-" * 30)
for j in range(item['vehicles'][0][0].size):
# Bus, Microbus, Minivan, Sedan, SUV, and Truck
vehicles = item['vehicles'][0][0][j]
height = item['height'][0][0][0]
width = item['width'][0][0][0]
left = vehicles[0][0][0]
top = vehicles[1][0][0]
right = vehicles[2][0][0]
bottom = vehicles[3][0][0]
# 边界框内的车辆类别
vehicles_type = vehicles[4][0]
if vehicles_type == 'Bus':
vehicles_type = 0
elif vehicles_type == 'Microbus':
vehicles_type = 1
elif vehicles_type == 'Minivan':
vehicles_type = 2
elif vehicles_type == 'Sedan':
vehicles_type = 3
elif vehicles_type == 'SUV':
vehicles_type = 4
elif vehicles_type == 'Truck':
vehicles_type = 5
# 边界框的信息描述,即(c, x, y, w, h)
str += '%s %s %s %s %s' % (vehicles_type, round(float((left + (right - left) / 2) / width), 6),
round(float((top + (bottom - top) / 2) / height), 6),
round(float((right - left) / width), 6),
round(float((bottom - top) / height), 6)) + '\n'
name = item['name'][0][0]
str = str[:str.rfind('\n')]
print(str)
if i in val_index:
with open(base_dir + "val/labels/" + name[:-3] + "txt", 'w') as f:
f.write(str + '\n')
copyfile(base_dir + "images/" + name, base_dir + "val/images/" + name)
else:
with open(base_dir + "train/labels/" + name[:-3] + "txt", 'w') as f:
f.write(str + '\n')
copyfile(base_dir + "images/" + name, base_dir + "train/images/" + name)
print('done--')
if __name__ == "__main__":
root = "../raw_data/BITVehicle_data/"
val_num = 3850
label_process(root, val_num)
备注:角度单一,只有俯拍角度;场景简单,每张图中只有几辆车,因此应再找一些其他角度的数据集,以提高模型的鲁棒性。
3.2. 车牌检测数据集
数据集名称:CCPD2019_data
数据集简介:CCPD是一个大型的、多样化的、经过仔细标注的中国城市车牌开源数据集。CCPD数据集主要分为CCPD2019数据集和CCPD2020(CCPD-Green)数据集。CCPD2019数据集车牌类型仅有普通车牌(蓝色车牌),CCPD2020数据集车牌类型仅有新能源车牌(绿色车牌)。CCPD2019数据集主要采集于合肥市停车场,采集时间为上午7:30到晚上10:00,停车场采集人员手持Android POS机对停车场的车辆拍照进行数据采集。所拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、雨天、雪天等。
标注介绍:CCPD数据集没有专门的标注文件,每张图像的文件名就是该图像对应的数据标注。如图片【025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg】,其文件名的含义如下:
- 025:车牌区域占整个画面的比例;
- 95_113: 车牌水平和垂直角度, 水平95°, 竖直113°;
- 154&383_386&473:标注框左上、右下坐标,左上(154, 383), 右下(386, 473);
- 86&473_177&454_154&383_363&402:标注框四个角点坐标,顺序为右下、左下、左上、右上;
- 0_0_22_27_27_33_16:车牌号码映射关系如下: 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为皖AY339S。
数据集预处理:由于该数据集很大,我挑选了部分用于项目;从图片名字中将车牌检测的标注转为.txt格式。以下是提取ccpd车牌边界框标注的代码。
import numpy as np
import os
import cv2
def imgname2bbox(images_path, labels_path):
dirs = os.listdir(images_path)
for image in dirs:
image_name = image.split(".")[0]
box = image_name.split("-")[2]
# 边界框信息
box = box.split("_")
box = [list(map(int, i.split('&'))) for i in box]
# 图片信息
image_path = f"{images_path}{image}"
img = cv2.imread(image_path)
with open(labels_path + image_name + ".txt", "w") as f:
x_min, y_min = box[0]
x_max, y_max = box[1]
x_center = (x_min + x_max) / 2 / img.shape[1]
y_center = (y_min + y_max) / 2 / img.shape[0]
width = (x_max - x_min) / img.shape[1]
height = (y_max - y_min) / img.shape[0]
f.write(f"0 {x_center:.6} {y_center:.6} {width:.6} {height:.6}")
if __name__ == "__main__":
images_train_path = "../data/CCPD_data/train/images/"
images_val_path = "../data/CCPD_data/val/images/"
labels_train_path = "../data/CCPD_data/train/labels/"
labels_val_path = "../data/CCPD_data/val/labels/"
# 从图片名字中提取ccpd的边界框信息,即(c, x, y, w, h)
dic_images = {0: images_train_path, 1: images_val_path}
dic_labels = {0: labels_train_path, 1: labels_val_path}
for i in dic_images:
imgname2bbox(dic_images[i], dic_labels[i])
3.3. 车牌识别数据集
数据集名称:CCPD2019_data
数据集预处理:从CCPD2019_data裁剪出车牌图像;从图片名字中将车牌提取车牌标签(车牌信息)。
import numpy as np
import os
import cv2
def ccpd_data2ccpd_plate_data(images_path, plate_images_path):
dirs = os.listdir(images_path)
for image in dirs:
# 读取图片
img = cv2.imread(f"{images_path}{image}")
# 图片名字
image_name = image.split(".")[0]
# 车牌的四个角点信息
points = image_name.split("-")[3]
points = points.split('_')
points = [list(map(int, i.split('&'))) for i in points]
# 将关键点的顺序变为从左上顺时针开始
points = points[-2:] + points[:2]
# 在图像上绘制车牌的四个角点
# for i, pt in enumerate(points):
# cv2.circle(img, pt, 5, (0, 222, 0), -1)
# 原车牌角点数组
pst1 = np.float32(points)
# 变换后的车牌角点数组
x_min, x_max = min(pst1[:, 0]), max(pst1[:, 0])
y_min, y_max = min(pst1[:, 1]), max(pst1[:, 1])
pst2 = np.float32([(0, 0), (x_max - x_min, 0), (x_max - x_min, y_max - y_min), (0, y_max - y_min)])
matrix = cv2.getPerspectiveTransform(pst1, pst2)
plate = cv2.warpPerspective(img, matrix, (int(x_max - x_min), int(y_max - y_min)))
cv2.imwrite(f"{plate_images_path}plate_{image}", plate)
# 省份列表,index对应ccpd
province_list = [
"皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云", "西", "陕", "甘", "青", "宁", "新"]
# 字母数字列表,index对应ccpd
word_list = [
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q", "R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
def imgname2plate_label(images_path, plate_labels_path):
dirs = os.listdir(images_path)
lst = []
for image in dirs:
# 图片名字
image_name = image.split(".")[0]
# 车牌的文字信息
label = image_name.split("-")[4]
# 读取车牌号
label = label.split("_")
province = province_list[int(label[0])]
words = [word_list[int(i)] for i in label[1:]]
# 车牌号
label = province + "".join(words)
lst.append(f"{image}---{label}")
with open(plate_labels_path + "imgnames_labels.txt", "w") as f:
for line in lst:
f.write(f"plate_{line}\n")
if __name__ == "__main__":
images_train_path = "../data/CCPD_data/train/images/"
images_val_path = "../data/CCPD_data/val/images/"
labels_train_path = "../data/CCPD_data/train/labels/"
labels_val_path = "../data/CCPD_data/val/labels/"
plate_images_train_path = "../data/CCPD_plate_data/train/images/"
plate_labels_train_path = "../data/CCPD_plate_data/train/labels/"
plate_images_val_path = "../data/CCPD_plate_data/val/images/"
plate_labels_val_path = "../data/CCPD_plate_data/val/labels/"
# 从ccpd数据集中提取车牌数据集
dic_images = {0: images_train_path, 1: images_val_path}
dic_plate_images = {0: plate_images_train_path, 1: plate_images_val_path}
for i in dic_images:
ccpd_data2ccpd_plate_data(dic_images[i], dic_plate_images[i])
dic_images = {0: images_train_path, 1: images_val_path}
dic_plate_labels = {0: plate_labels_train_path, 1: plate_labels_val_path}
for i in dic_images:
imgname2plate_label(dic_images[i], dic_plate_labels[i])
备注:由于主要是在合肥采集,因此“皖”牌照居多,导致对其他省份的简称识别较差。
4. 目标检测部分
模型:yolov5_v6s
训练:kaggle
数据:车辆检测---BITVehicle_data;车牌检测---CCPD2019_data
epochs:车辆检测---30;车牌检测---30
使用kaggle训练yolov5模型的具体过程,这里不在多言,如果读者对此不熟练可阅读这篇文章:【pytorch】目标检测:一文搞懂如何利用kaggle训练yolov5模型
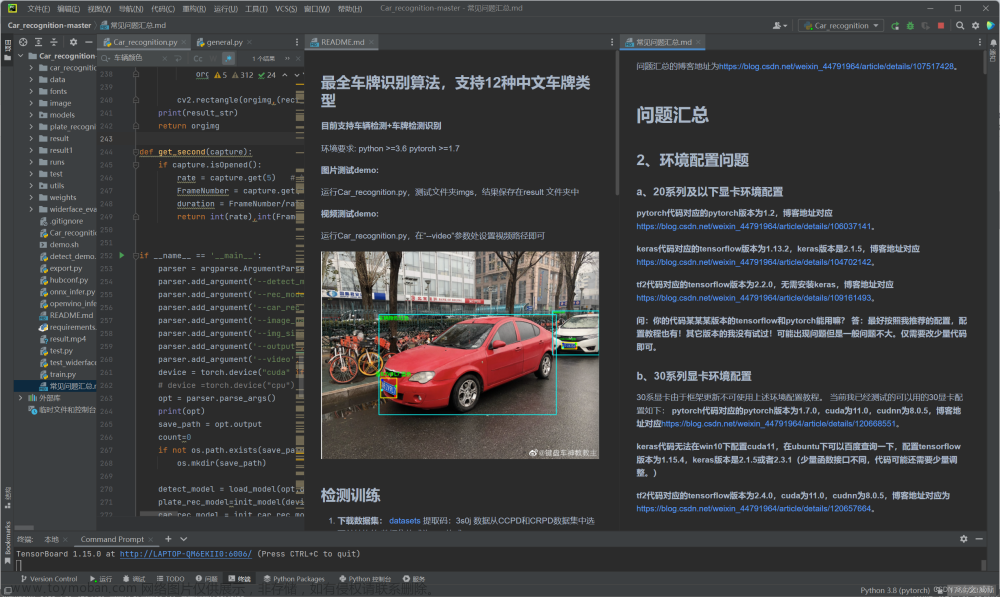
这里展示一下车辆检测的推理效果:
5. 字符识别部分
车牌的字符是规则文本形式,不存在弯曲、旋转等变化,比较适合运用crnn+ctc识别方法。只不过由于拍摄角度会存在透视问题,需要在推理时做一下矫正变换。
有关crnn+ctc的原理这里不再详述,推荐两篇文章,个人认为讲的很透彻。理论:一文读懂CRNN+CTC文字识别,代码:【OCR技术系列之八】端到端不定长文本识别CRNN代码实现 - Madcola - 博客园。
5.1. lmdb格式的数据
将图片、标签转为lmdb格式保存(可以减少训练时的寻址时间,特别是在图片尺寸小、数量多时,优势更明显)。转换的方法也很简单,就是首先读入图像和对应的文本标签,先使用字典将该组合存储起来(cache),再利用lmdb包的put函数把字典(cache)存储的k,v写成lmdb格式存储好(cache当有了1000个元素就put一次)。如果你对lmdb格式不了解,可以阅读python(八):python使用lmdb数据库 - jasonzhangxianrong - 博客园。
import lmdb
import cv2
import numpy as np
import os
out_path_train = "../data/CCPD_plate_data/train/train_lmdb"
in_path_train = "../data/CCPD_plate_data/train/labels/imgnames_labels.txt"
root_train = "../data/CCPD_plate_data/train/images/"
map_size_train = "524288000" # 500mb
out_path_val = "../data/CCPD_plate_data/val/val_lmdb"
in_path_val = "../data/CCPD_plate_data/val/labels/imgnames_labels.txt"
root_val = "../data/CCPD_plate_data/val/images/"
map_size_val = "104857600" # 100mb
out_path = {0: out_path_train, 1: out_path_val}
in_path = {0: in_path_train, 1: in_path_val}
root = {0: root_train, 1: root_val}
map_size = {0: map_size_train, 1: map_size_val}
def checkImageIsValid(imageBin):
if imageBin is None:
return False
try:
imageBuf = np.frombuffer(imageBin, dtype=np.uint8)
img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
imgH, imgW = img.shape[0], img.shape[1]
except:
return False
else:
if imgH * imgW == 0:
return False
return True
def writeCache(env, cache):
with env.begin(write=True) as txn:
for k, v in cache.items():
if isinstance(v, bytes):
txn.put(k.encode(), v)
else:
txn.put(k.encode(), v.encode())
def createDataset(outputPath, imagePathList, labelList, root, map_size, checkValid=True):
"""
为crnn的训练准备lmdb数据
:param outputPath: lmdb数据的输出路径
:param imagePathList: 图像数据的路径列表,即train.txt文件列表化
:param labelList: 图像数据对应的标签列表
:param checkValid: bool,辨别imagePathList中的路径是否为图片
:return:
"""
assert (len(imagePathList) == len(labelList))
nSamples = len(imagePathList)
# map_size定义最大储存容量,单位是b
env = lmdb.open(outputPath, map_size=int(map_size))
# 缓存字典
cache = {}
# 计数器
counter = 1
for i in range(nSamples):
imagePath = os.path.join(root, imagePathList[i]).split("---")[0]
label = ''.join(labelList[i])
with open(imagePath, 'rb') as f:
imageBin = f.read()
if checkValid:
if not checkImageIsValid(imageBin):
print('%s is not a valid image' % imagePath)
continue
imageKey = 'image-%09d' % counter
labelKey = 'label-%09d' % counter
cache[imageKey] = imageBin
cache[labelKey] = label
if counter % 1000 == 0:
writeCache(env, cache)
cache = {}
print('Written %d / %d' % (counter, nSamples))
counter += 1
print(counter)
nSamples = counter - 1
cache['num-samples'] = str(nSamples)
writeCache(env, cache)
print('Created dataset with %d samples' % nSamples)
if __name__ == '__main__':
for i in range(2):
out_path = out_path[i]
in_path = in_path[i]
root = root[i]
map_size = map_size[i]
outputPath = out_path
if not os.path.exists(out_path):
os.mkdir(out_path)
with open(in_path, "r") as imgdata:
imagePathList = list(imgdata)
labelList = []
for line in imagePathList:
word = line.split("---")[1].replace("\n", "")
labelList.append(word)
createDataset(outputPath, imagePathList, labelList, root, map_size=map_size)
5.2. 字符的编码与解码
在字符识别中还需要将文字标签数字化,即我们用数字来表示每一个文字。比如“我”字对应的id是1,“l”对应的id是1000,“?”对应的id是90,如此类推,这种编解码工作使用字典数据结构存储即可,训练时先把标签编码(encode),预测时就将网络输出结果解码(decode)成文字输出。在开始编码、解码前,我们需要先明确字母表,它就是一个字符串。
alphabets = "皖沪津渝冀晋蒙辽吉黑苏浙京闽赣鲁豫鄂湘粤桂琼川贵云西陕甘青宁新ABCDEFGHIJKLMNPQRSTUVWXYZ0123456789"
下面让我们来看一下该字母表对应的编码、解码函数。
class StrLabelConverter(object):
"""
作用:字符串与标签之间的转换
注意:需要在字母表中的首位置插入‘blank’, 为CTC计算损失做准备
参数:字母表(alphabet)
"""
def __init__(self, alphabet):
self.alphabet = '-' + alphabet
self.dict = {}
for i, char in enumerate(alphabet):
# 字典的值‘0’是为‘blank’准备的
self.dict[char] = i + 1
def ocr_encode(self, text):
"""
作用:将字符串进行编码为标签,支持single和batch模式
:param text:lmdb格式的标签,可以是single也可以是batch,是一个可迭代的对象
:return:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: length_x,是指第x个single
torch.IntTensor [n]: n个single,每个single的值m表明该single有m个字符
"""
length, result = [], []
for item in text:
item = item.decode("utf-8", "strict")
length.append(len(item))
for char in item:
index = self.dict[char]
result.append(index)
text = result
# print(text,length)
return torch.LongTensor(text), torch.LongTensor(length)
def ocr_decode(self, t, length, raw=False):
"""
作用:将标签进行码为字符串,支持single和batch模式
:param t: 将要进行解码的标签,可以是single也可以是batch,Tensor形式
:param length:若length含有n个元素,则表明有n个single,每个single的值m表明网络预测有m个字符
:param raw: bool,False:去重;True: 不去重
:return: 模型预测的字符串
"""
if length.numel() == 1:
length = length[0]
assert t.numel() == length, f"text with length: {t.numel()} does not match declared length: {length}"
if raw:
return ''.join([self.alphabet[i] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i]])
return ''.join(char_list)
else:
# batch模式,通过递归的方式实现该模式
assert t.numel() == length.sum(), f"texts with length: {t.numel()} does not match declared length: {length.sum()}"
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(self.ocr_decode(t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts
5.3. crnn网络设计
crnn的网络由cnn(卷积层)和rnn(循环层)组合而成,cnn负责图像特征提取、rnn负责文字的序列特征提取。由于项目的字符特性(即共有7个字符,第一个是汉字,第二个是字母,其余是字母和数字),我们是不是可以将rnn网络去除,只保留cnn网络并对cnn进行改进,以达到车牌识别的目的呢?这是笔者在进行这个项目时突然冒出的一个想法,由于时间原因并没有进行验证。这里我们就按照CRNN论文对网络进行构建,以期对crnn网络理解更加深入。
CRNN网络的构建代码:
import torch
import torch.nn.functional as F
class Vgg_16(torch.nn.Module):
def __init__(self):
super(Vgg_16, self).__init__()
self.convolution1 = torch.nn.Conv2d(1, 64, 3, padding=1)
self.pooling1 = torch.nn.MaxPool2d(2, stride=2)
self.convolution2 = torch.nn.Conv2d(64, 128, 3, padding=1)
self.pooling2 = torch.nn.MaxPool2d(2, stride=2)
self.convolution3 = torch.nn.Conv2d(128, 256, 3, padding=1)
self.convolution4 = torch.nn.Conv2d(256, 256, 3, padding=1)
self.pooling3 = torch.nn.MaxPool2d((1, 2), stride=(2, 1)) # notice stride of the non-square pooling
self.convolution5 = torch.nn.Conv2d(256, 512, 3, padding=1)
self.BatchNorm1 = torch.nn.BatchNorm2d(512)
self.convolution6 = torch.nn.Conv2d(512, 512, 3, padding=1)
self.BatchNorm2 = torch.nn.BatchNorm2d(512)
self.pooling4 = torch.nn.MaxPool2d((1, 2), stride=(2, 1))
self.convolution7 = torch.nn.Conv2d(512, 512, 2)
def forward(self, x):
x = F.relu(self.convolution1(x), inplace=True)
x = self.pooling1(x)
x = F.relu(self.convolution2(x), inplace=True)
x = self.pooling2(x)
x = F.relu(self.convolution3(x), inplace=True)
x = F.relu(self.convolution4(x), inplace=True)
x = self.pooling3(x)
x = self.convolution5(x)
x = F.relu(self.BatchNorm1(x), inplace=True)
x = self.convolution6(x)
x = F.relu(self.BatchNorm2(x), inplace=True)
x = self.pooling4(x)
x = F.relu(self.convolution7(x), inplace=True)
return x # b*512x1x22
class RNN(torch.nn.Module):
def __init__(self, class_num, hidden_unit):
super(RNN, self).__init__()
self.Bidirectional_LSTM1 = torch.nn.LSTM(512, hidden_unit, bidirectional=True)
self.embedding1 = torch.nn.Linear(hidden_unit * 2, 512)
self.Bidirectional_LSTM2 = torch.nn.LSTM(512, hidden_unit, bidirectional=True)
self.embedding2 = torch.nn.Linear(hidden_unit * 2, class_num)
def forward(self, x):
x = self.Bidirectional_LSTM1(x) # LSTM output: output, (h_n, c_n)
T, b, h = x[0].size() # x[0]: (seq_len, batch, num_directions * hidden_size)
x = self.embedding1(x[0].view(T * b, h)) # pytorch view() reshape as [T * b, nOut]
x = x.view(T, b, -1) # [22, b, 512]
x = self.Bidirectional_LSTM2(x)
T, b, h = x[0].size()
x = self.embedding2(x[0].view(T * b, h))
x = x.view(T, b, -1)
return x # [22,b,class_num]
# output: [s,b,class_num]
class CRNN(torch.nn.Module):
def __init__(self, class_num, hidden_unit=256):
super(CRNN, self).__init__()
self.cnn = torch.nn.Sequential()
self.cnn.add_module('vgg_16', Vgg_16())
self.rnn = torch.nn.Sequential()
self.rnn.add_module('rnn', RNN(class_num, hidden_unit))
def forward(self, x):
x = self.cnn(x)
b, c, h, w = x.size()
# print(x.size()) #: b,c,h,w,(64, 512, 1, 22)
assert h == 1 # 特征图的高度必须是1
x = x.squeeze(2) # 去除h维度, b *512 * width
x = x.permute(2, 0, 1) # [w, b, c] = [seq_len, batch, input_size]
# x = x.transpose(0, 2)
# x = x.transpose(1, 2)
x = self.rnn(x)
# print(x.size()) # (22, 64, 67)
return x
5.4. ctc损失函数
ctc损失函数(转录层)是为了解决训练时字符无法对齐的问题。ctc引入blank字符,解决有些位置没有字符的问题;通过递推,快速计算梯度。
pytorch中的ctc损失函数:CTCLoss — PyTorch 2.0 documentation
5.5. 网络的训练
下面我们来crnn+ctc网络的训练,训练过程和普通的cnn网络没有多大的区别。唯一需要注意的是ctc损失函数的构建,这里我建议读者在进行这部分代码阅读前一定要仔细阅读pytorch官方文档的ctc损失函数部分。下面是训练的核心代码:
import argparse
import copy
import os
import lib.alphabets as alphabets
import torch
import random
import numpy as np
from lib import dataset, convert
from torchvision import transforms
from torch.utils.data import DataLoader
from net.CRNN_Net import CRNN
import torch.optim as optim
from tqdm import tqdm
import time
train_data_path = "./data/CCPD_plate_data/train/train_lmdb"
val_data_path = "./data/CCPD_plate_data/val/val_lmdb"
weight = "./runs/train/trainbest_weights.pth"
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--train_data', type=str, default=train_data_path)
parser.add_argument('--val_data', type=str, default=val_data_path)
parser.add_argument('--image_size', type=tuple, default=(32, 100))
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--epochs', type=int, default=2)
parser.add_argument('--alphabet', type=str, default=alphabets.alphabets)
parser.add_argument('--project', default='./runs/train/')
parser.add_argument('--random_seed', type=int, default=111)
parser.add_argument('--using_cuda', type=bool, default=True)
parser.add_argument('--num_workers', type=int, default=0)
parser.add_argument('--pin_memory', type=bool, default=True)
parser.add_argument('--optimizer', type=str, default="RMSprop")
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--load_weight', type=bool, default=False)
parser.add_argument('--weight_path', type=str, default=weight)
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def weights_init(m):
class_name = m.__class__.__name__
if class_name.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif class_name.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def train_and_eval(model, epochs, loss_func, optimizer, train_loader, val_loader):
# 初始化参数
lst = []
t_start = time.time()
best_weights = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(epochs):
logs = "-" * 100 + "\n"
# train
model.train()
running_loss, running_acc = 0.0, 0.0
train_bar = tqdm(train_loader)
train_bar.desc = f"第{epoch + 1}次训练,Processing"
for inputs, labels in train_bar:
logs += "*" * 50 + "\n"
inputs = inputs.to(device) # 数据放到device中
optimizer.zero_grad()
outputs = model(inputs)
# 计算这个batch的损失值
# print(type(labels))
text, text_length = converter.ocr_encode(text=labels)
# print(text)
# print(text_length)
text, text_length = text.to(device), text_length.to(device) # 数据放到device中
outputs_length = torch.full(size=(outputs.size(1),), fill_value=outputs.size(0), device=device,
dtype=torch.long)
loss = loss_func(outputs, text, outputs_length, text_length)
running_loss += loss.item() * outputs.size(1)
# 计算这个batch正确识别的字符数
preds_size = torch.IntTensor([outputs.size(0)] * outputs.size(1))
_, preds = outputs.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
# print(preds.view(64, 22))
# print(preds_size)
sim_preds = converter.ocr_decode(preds.data, preds_size.data)
# print(len(sim_preds), sim_preds)
counter, lst = 0, []
for i in labels:
lst.append(i.decode("utf-8", "strict"))
# print(lst)
for pred, target in zip(sim_preds, lst):
# print(pred, target)
if pred == target:
counter += 1
logs += f"target:{lst}\n"
logs += f"pred:{sim_preds}\n"
logs += "*" * 50 + "\n"
running_acc = counter+running_acc
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 计算本epoch的损失值和正确率
train_loss = running_loss / len(train_dataset)
train_acc = running_acc / len(train_dataset)
train_state = f"第{epoch + 1}次训练,train_loss:{train_loss:.6f}, train_acc:{train_acc:.6f}\n"
logs += train_state
# eval
model.eval()
running_loss, running_acc = 0.0, 0.0
with torch.no_grad():
eval_bar = tqdm(val_loader)
eval_bar.desc = f"第{epoch + 1}次评估,Processing"
for inputs, labels in eval_bar:
inputs = inputs.to(device)
outputs = model(inputs).to(device)
# 计算这个batch的损失值
text, text_length = converter.ocr_encode(text=labels)
text, text_length = text.to(device), text_length.to(device) # 数据放到device中
outputs_length = torch.full(size=(outputs.size(1),), fill_value=outputs.size(0), device=device,
dtype=torch.long)
loss = loss_func(outputs, text, outputs_length, text_length)
running_loss += loss.item() * outputs.size(1)
# 计算这个batch正确识别的字符数
preds_size = torch.IntTensor([outputs.size(0)] * outputs.size(1))
_, preds = outputs.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
sim_preds = converter.ocr_decode(preds.data, preds_size.data)
counter, lst = 0, []
for i in labels:
lst.append(i.decode("utf-8", "strict"))
for pred, target in zip(sim_preds, lst):
if pred == target:
counter += 1
running_acc = counter+running_acc
# 计算本epoch的损失值和正确率
val_loss = running_loss / len(val_dataset)
val_acc = running_acc / len(val_dataset)
val_state = f"第{epoch + 1}次评估,val_loss:{val_loss:.6f}, val_acc:{val_acc:.6f}\n"
logs += val_state
logs += "-" * 100 + "\n"
print(logs)
lst.append(logs)
if val_acc > best_acc:
best_acc = val_acc
best_weights = copy.deepcopy(model.state_dict())
t_end = time.time()
total_time = t_end - t_start
result = f"{epochs}次训练与评估共计用时{total_time // 60:.0f}m{total_time % 60:.0f}s\n最高正确率是{best_acc:.6f}"
print(result)
lst.append(result)
# 加载最佳的模型权重
model.load_state_dict(best_weights)
return model, lst
if __name__ == "__main__":
opt = parse_opt()
print(type(opt.train_data))
if not os.path.exists(opt.project):
os.makedirs(opt.project)
print(opt.epochs)
if torch.cuda.is_available() and opt.using_cuda:
device = torch.device('cuda:0')
# torch.backends.cudnn.deterministic = True
print("使用单个gpu进行训练")
else:
device = torch.device('cpu')
print("使用cpu进行训练")
# 随机种子
random.seed(opt.random_seed)
np.random.seed(opt.random_seed)
torch.manual_seed(opt.random_seed)
# 数据增强
transformer = {"train": transforms.Compose([transforms.Resize((32, 100)),
transforms.ToTensor(),
transforms.Normalize(0.403, 0.154)]),
"val": transforms.Compose([transforms.Resize((32, 100)),
transforms.ToTensor(),
transforms.Normalize(0.387, 0.612)])}
# 制作数据集
train_dataset = dataset.LmdbDataset(root=opt.train_data, transform=transformer["train"])
train_loader = DataLoader(train_dataset, batch_size=opt.batch_size, shuffle=True, num_workers=opt.num_workers,
pin_memory=opt.pin_memory)
val_dataset = dataset.LmdbDataset(root=opt.val_data, transform=transformer["val"])
val_loader = DataLoader(val_dataset, batch_size=opt.batch_size, shuffle=True, num_workers=opt.num_workers,
pin_memory=opt.pin_memory)
n_class = len(opt.alphabet) + 1
print(f"字母表的长度是{n_class}") # 包含blank
# 字符与标签转换器
converter = convert.StrLabelConverter(opt.alphabet)
# crnn网络
net = CRNN(n_class)
net.apply(weights_init)
net = net.to(device)
if opt.load_weight:
net.load_state_dict(torch.load(opt.weight_path, map_location=device))
print(net)
# ctc损失函数
ctc = torch.nn.CTCLoss()
# 优化器
if opt.optimizer == "RMSprop":
optimizer = optim.RMSprop(net.parameters(), lr=opt.lr)
elif opt.optimizer == "Adadelta":
optimizer = optim.Adadelta(net.parameters(), lr=opt.lr)
elif opt.optimizer == "Adam":
optimizer = optim.Adam(net.parameters(), lr=opt.lr)
# 训练和评估
best_model, log = train_and_eval(net, opt.epochs, ctc, optimizer, train_loader, val_loader)
best_weights = best_model.state_dict()
torch.save(best_weights, opt.project + "best_weights.pth")
with open(opt.project + "logs.txt", "w") as f:
for i in log:
f.write(i)
6. 模型推理部分
由于在检测部分使用的是yolov5,而yolov5拥有一套完整的代码,因此我们可以在yolov5的.detect基础上调整得到需要的推理代码。下面是推理的核心代码:
import argparse
import os
import sys
from pathlib import Path
import numpy as np
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from torchvision import transforms
from my_utils import correction, box_label, Annotator
from crnn_ctc.net import CRNN_Net as ocr_net
from crnn_ctc.lib import convert, alphabets
from yolov5.utils.augmentations import letterbox
from yolov5.models.common import DetectMultiBackend
from yolov5.utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from yolov5.utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer,
xyxy2xywh)
from yolov5.utils.torch_utils import select_device, time_sync
@torch.no_grad()
def run(weights_vehicle=ROOT / 'weights/vehicle_yolov5s.pt',
weights_ccpd=ROOT / 'weights/ccpd_yolov5s.pt',
weights_plate=ROOT / 'weights/plate_crnn.pth',
source=ROOT / 'test/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'test/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
save_txt=False, # save results to *.txt
save_img=True,
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
project=ROOT / 'test/runs', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# 加载vehicle模型
device = select_device(device)
model = DetectMultiBackend(weights_vehicle, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
imgsz = check_img_size(imgsz, s=stride) # check image size
# 加载ccpd模型
model_ccpd = DetectMultiBackend(weights_ccpd, device=device, dnn=dnn, data=data)
# 加载ocr模型
model_ocr = ocr_net.CRNN(class_num=67)
model_ocr.load_state_dict(torch.load(weights_plate, map_location=device))
model_ocr.eval()
# Half
half &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if half else model.model.float()
# Dataloader
if webcam:
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# 开始推理
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz), half=half) # warmup
model_ccpd.warmup(imgsz=(1, 3, 320, 320), half=half)
dt, seen = [0.0, 0.0, 0.0], 0
# 七种边界框的颜色,六类车辆、一类车牌
np.random.seed(1)
colors = np.random.randint(0, 255, size=(len(names)+1, 3))
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
for i, det in enumerate(pred): # 每张图片
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
s += '%gx%g ' % im.shape[2:] # print string
annotator = Annotator(im0, line_width=3, pil=True, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det): # 在图片中检测到的车辆边界框
pt1 = (int(xyxy[0]), int(xyxy[1]))
pt2 = (int(xyxy[2]), int(xyxy[3]))
# 截取锚框内的图像,源图像的拷贝是im0,锚框左上坐标是pt1,右下坐标是pt2
im0_vehicle = im0[pt1[1]:pt2[1], pt1[0]:pt2[0]]
im_vehicle = letterbox(im0_vehicle, new_shape=(320, 320))[0]
im_vehicle = im_vehicle.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im_vehicle = np.ascontiguousarray(im_vehicle)
im_vehicle = torch.from_numpy(im_vehicle).to(device)
im_vehicle = im_vehicle.half() if half else im_vehicle.float() # uint8 to fp16/32
im_vehicle /= 255 # 0 - 255 to 0.0 - 1.0
if len(im_vehicle.shape) == 3:
im_vehicle = im_vehicle[None] # expand for batch dim
pred_ccpd = model_ccpd(im_vehicle, augment=augment, visualize=visualize)
pred_ccpd = non_max_suppression(pred_ccpd, conf_thres, iou_thres, classes, agnostic_nms,
max_det=max_det)
for ii, det_ccpd in enumerate(pred_ccpd): # 每个车牌
if len(det_ccpd):
# Rescale boxes from 320*320 to im0_vehicle size
det_ccpd[:, :4] = scale_coords(im_vehicle.shape[2:], det_ccpd[:, :4],
im0_vehicle.shape).round()
# Write results
for *xyxy, conf, clss in reversed(det_ccpd): # 每个车牌的边界框
pt11 = (int(xyxy[0]), int(xyxy[1]))
pt22 = (int(xyxy[2]), int(xyxy[3]))
# 截取且矫正车牌
im0_plate = im0_vehicle[pt11[1]:pt22[1], pt11[0]:pt22[0]]
# im0_plate = correction(im0_plate)
# 图像灰度化且转为张量
im0_plate = cv2.cvtColor(im0_plate, cv2.COLOR_BGR2GRAY)
im0_plate = cv2.resize(im0_plate, (100, 32))
im0_plate = transforms.ToTensor()(im0_plate).to(device)
im0_plate = im0_plate.view(1, 1, 32, 100)
result = model_ocr(im0_plate)
converter = convert.StrLabelConverter(alphabets.alphabets)
preds_size = torch.IntTensor([result.size(0)] * result.size(1))
_, preds = result.max(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
plate = converter.ocr_decode(preds.data, preds_size.data)
# plate标签、ccpd边界框在源图中的 坐标
color = colors[6]
target = str(plate)
pt1_ccpd, pt2_ccpd = (pt1[0] + pt11[0], pt1[1] + pt11[1]), (
pt1[0] + pt22[0], pt1[1] + pt22[1])
# 可视化
annotator.box_label(pt1_ccpd+pt2_ccpd, target, color=tuple(color))
# vehicle标签、边界框坐标
c = int(cls)
color = colors[c]
label = f'{names[c]} {conf:.2f}'
pt1_vehicle, pt2_vehicle = pt1, pt2
annotator.box_label(pt1_vehicle + pt2_vehicle, label, color=tuple(color))
# 保存每一张测试结果
im0 = annotator.result()
if save_img:
# cv2.imshow("111", im0)
# cv2.waitKey()
# cv2.destroyAllWindows()
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(
f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights_vehicle', nargs='+', type=str, default=ROOT / 'weights/vehicle_yolov5s.pt',
help='model path(s)')
parser.add_argument('--weights_ccpd', nargs='+', type=str, default=ROOT / 'weights/ccpd_yolov5s.pt',
help='model path(s)')
parser.add_argument('--weights_plate', nargs='+', type=str, default=ROOT / 'weights/plate_crnn.pth',
help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'test/video', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'test/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
return run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
points = main(opt)
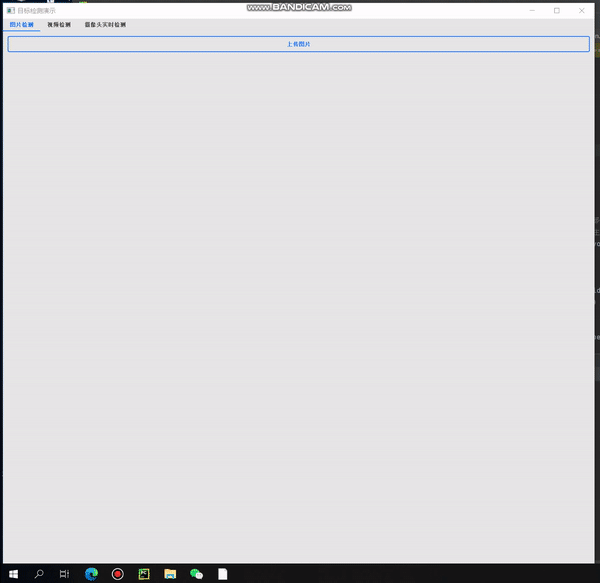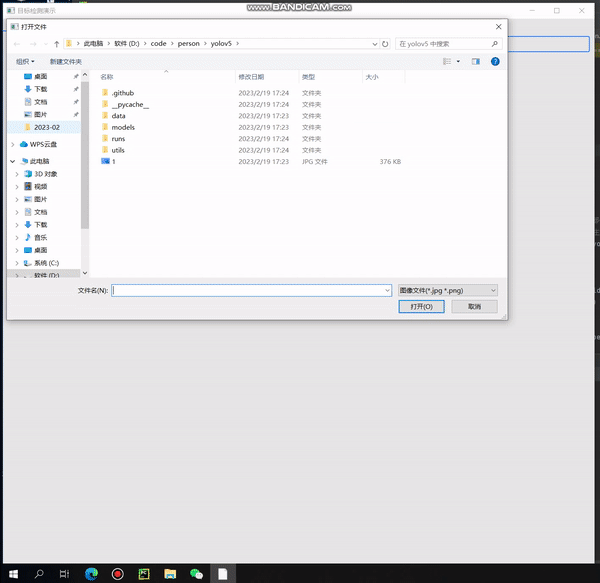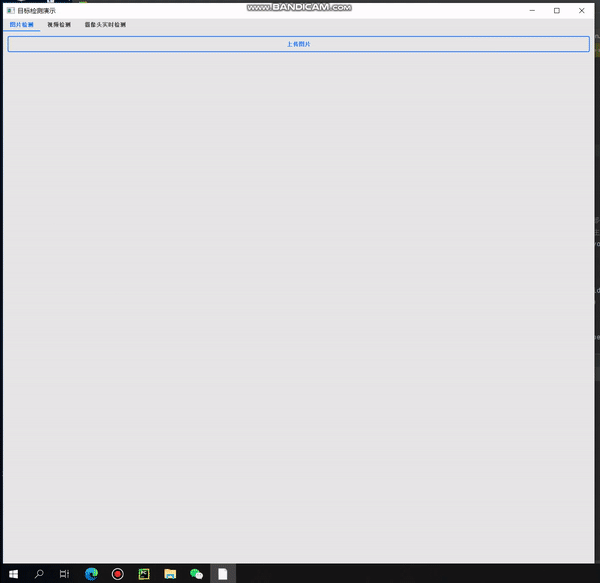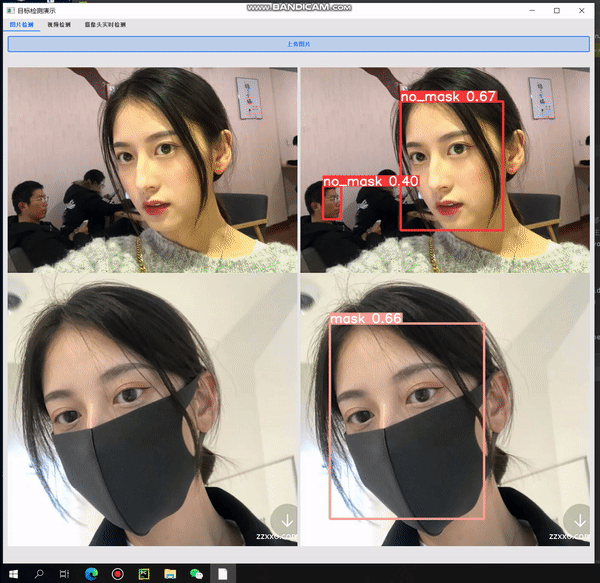
7. 效果展示与项目总结
7.1. 效果展示
图片
文章来源:https://www.toymoban.com/news/detail-677896.html
7.2. 项目总结
由于1)收集的数据集较为单一,如车辆检测仅有俯瞰正视角度、车牌检测无双层牌照图片、车牌识别80%以上是安徽牌照;2)场景不够丰富,如车辆检测中最多也才有三四辆车、天气、地理环境等单一;3)数据集体量小。以上原因导致模型的鲁棒性较差,只有在监控视角、车辆较少、且车辆是正视角度才能达到理想效果,其他场景下较为拉跨。
本次项目由于数据集的原因导致成果十分不理想,建议读者重新寻找合适的数据集进行实战!
以上是本次车牌识别实战的简单记录,如果本项目对您能有所启发,不要忘了点赞哦!文章来源地址https://www.toymoban.com/news/detail-677896.html
到了这里,关于【pytorch】从零开始,利用yolov5、crnn+ctc进行车牌识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!