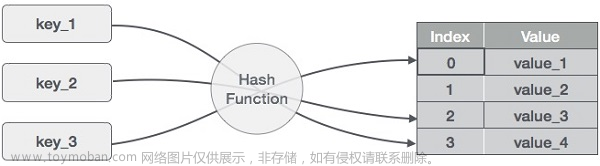
散列表(Hash Table)是一种用于存储和查找键值对的数据结构,也被称为哈希表、散列映射或字典。它通过将键转换成一个索引来加快查找速度,进而提高了数据处理的效率。
装填因子(Load Factor)是指散列表中已被占用桶(包含一个或多个键值对)的数量与散列表总桶数的比例。它是衡量散列表负载情况的重要指标,通常用于评估散列表的性能和可扩展性。
当装填因子接近 1 时,说明散列表已经非常拥挤,在这种情况下,如果再插入新的键值对,就可能导致碰撞概率增加,并且查询效率也会降低。因此,需要及时采取一些措施,如扩容,以保持散列表的高效性。
通常建议在装填因子达到某个阈值时进行扩容,具体阈值的选择与散列表大小、散列算法等因素有关,一般建议取值为 0.7 到 0.8 之间。
在散列表中,装填因子
的计算方式为:已占用桶数 / 总桶数。
平均查找长度(Average Search Length,ASL)是指在散列表中查找一个键的平均比较次数,也可以称为平均探测长度。它是衡量散列表性能的重要指标之一。
在散列表中查找一个键时,需要经历两个步骤:首先根据散列函数将该键映射到某个桶中,然后在该桶中对键进行比较,直到找到目标键或者确定目标键不存在。
因此,如果一个散列表有 n 个键值对,并且在查找目标键时需要比较 k 次才能找到或者确定不存在,则平均查找长度为:ASL = (k1 + k2 + ... + ki) / n,其中 ki 表示查找第 i 个键时需要的比较次数。
在散列表中,查找成功的平均查找长度(Average Search Length of Successful Search,ASL-S)是指在散列表中查找某个已存在键的平均比较次数。它通常用于评估散列表查找性能的好坏。
假设散列表中有 n 个键值对,在查找某个已存在键时需要比较 k 次才找到,则查找成功的平均查找长度为:
ASL-S = (k1 + k2 + ... + ki) / n
其中 ki 表示查找第 i 个已存在的键时需要的比较次数。
可以看出,查找成功的平均查找长度越小,说明散列表在查找已存在键时效率越高。因此,尽可能地减少散列冲突和提高散列表的装填因子等方法都可以有效地降低查找成功的平均查找长度,提高散列表查找性能。
在散列表中,查找失败的平均查找长度(
常考Average Search Length of Unsuccessful Search,ASL-U)是指在散列表中查找某个不存在键的平均比较次数。它也是评估散列表性能的一个重要参数。
假设散列表中有 n 个键值对,在查找某个不存在键时需要比较 k 次才确定不存在,则查找失败的平均查找长度为:
ASL-U = (k1 + k2 + ... + ki) / n
其中 ki 表示查找第 i 个不存在的键时需要的比较次数。
可以看出,查找失败的平均查找长度越小,说明在散列表中查找不存在键的效率越高。常见的提高散列表查找效率的方法包括:合理设计散列函数、使用开放地址法解决冲突、设置合适的装填因子等。
常考的处理冲突的平均查找长度


如上图所示,这是一道通过线性探测法解决冲突求查找失败的平均查找长度问题。
给定一个所要查找的键值k,若开始通过哈希函数定位到下标为0的位置,将98与k比较,不相等(比较一次)说明这个位置查找失败,继续下一个紧邻的下标为1的位置......直到比较到下标为8的位置为空,至此查找失败,这种情况一共比较了9次;若开始通过哈希函数定位到下标为1的位置,将22与k比较,不相等(比较一次)说明这个位置查找失败,继续下一个紧邻的下标为2的位置......直到比较到下标为8的位置为空,至此查找失败,这种情况一共比较了8次;若开始通过哈希函数定位到下标为2的位置,将30与k比较,不相等(比较一次)说明这个位置查找失败,继续下一个紧邻的下标为3的位置......直到比较到下标为8的位置为空,至此查找失败,这种情况一共比较了7次......若开始通过哈希函数定位到下标为6的位置,将6与k比较,不相等(比较一次)说明这个位置查找失败,继续下一个紧邻的下标为7的位置......直到比较到下标为8的位置为空,至此查找失败,这种情况一共比较了3次,综上所述,查找失败的平均查找长度=(9+8+7+6+5+4+3)/7=6。(分母是7是因为通过对7取余,只能定位到下标0到6的位置。

如上图所示,这是一道通过线性探测法解决冲突求查找成功的平均查找长度问题。
查找成功的平均查找长度=查找每一个存在的关键字比较的次数/关键字总个数。因为22%7=1(比较一次,所需位置是空的,将22放入这个位置),43%7=1(发现下标为1的位置有22,根据线性探测法放到下标为2的位置,比较了两次),15%7=1(发现下标为1和2的位置均有元素,于是放到下标为3的位置,比较了三次)。分母是3的原因是每个元素被成功查找的概率都是1/3。也就是说成功查找22只需要通过哈希函数定位到下标为1的位置,和22比较一次发现相等即成功,成功查找43通过哈希函数也定位到下标为1的位置,比较一次不相等,继续向后寻找,和43比较发现相等即查找成功,比较了两次。则成功查找15比较了3次。所以查找成功的平均查找长度=(1+2+3)/3=2.
可参考王道相关视频



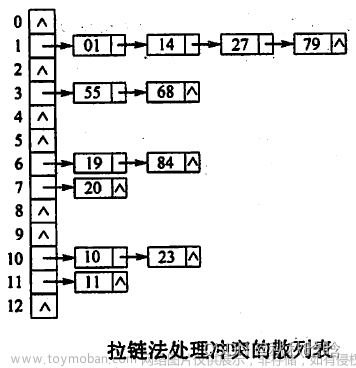
这是一道通过链接地址法解决冲突求查找平均查找长度问题。
查找成功的平均查找长度=(1*4+2*3+3*1)/8=13/8,查找33,1,13,38只需要通过哈希函数定位下标比较一次即成功(故1*4),查找22,12,27均需要比较两次才成功(故2*3),查找34需要比较三次才能成功。
查找失败的平均查找长度=(3+4+2+1+1+3+1+1+1+1+1)/11=19/11,通过哈希函数定位到下标为0的位置,与33比较,与22比较均不是关键值,再比较一次发现22后面为空,至此查找失败,一共比较了3次;通过哈希函数定位到下标为1的位置,与1比较,与12,与34比较均不是关键值,再比较一次发现34后面为空,至此查找失败,一共比较了4次;通过哈希函数定位到下标为2的位置,与13比较不是关键值,再比较一次发现13后面为空,至此查找失败,一共比较了2次;通过哈希函数定位到下标为3的位置,比较一次发现为空,至此查找失败,一共比较了1次,同理依次类推即得,分母11为所能定位到的所有的初始地址0到10。
文章来源地址https://www.toymoban.com/news/detail-677994.html
文章来源:https://www.toymoban.com/news/detail-677994.html
到了这里,关于散列表平均查找长度的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!