推荐阅读
AI文本 OCR识别最佳实践
AI Gamma一键生成PPT工具直达链接
玩转cloud Studio 在线编码神器
玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间
资源分享
史上最全文档AI绘画stablediffusion资料分享
AI绘画关于SD,MJ,GPT,SDXL百科全书
「java、python面试题」来自UC网盘app分享,打开手机app,额外获得1T空间
https://drive.uc.cn/s/2aeb6c2dcedd4
AIGC资料包
https://drive.uc.cn/s/6077fc42116d4
https://pan.xunlei.com/s/VN_qC7kwpKFgKLto4KgP4Do_A1?pwd=7kbv#
在分布式系统设计中,Redis是一个备受欢迎的内存数据库,而一致性哈希算法则是分布式系统中常用的数据分片和负载均衡技术。本文将深入探讨Redis的扩容机制以及一致性哈希算法的原理,同时提供示例代码以帮助读者更好地理解这两个重要概念。
引言
Redis是一种高性能的内存数据库,常用于缓存、会话管理和消息队列等场景。在处理大规模数据时,Redis的性能优势显著,但随之而来的挑战之一是如何进行扩容以应对不断增长的数据需求。一致性哈希算法是实现分布式缓存和负载均衡的关键技术之一,能够有效解决扩容时的数据迁移和负载分布问题。
Redis的扩容机制
1. 问题背景
在Redis中,数据通常分布在多个节点上,每个节点负责存储一部分数据。当系统需要扩容以容纳更多数据时,传统的数据库往往需要大规模的数据迁移,而这在Redis中是不切实际的,因为Redis的高性能建立在快速内存访问的基础上。因此,Redis采用了一种更加巧妙的扩容机制。
2. 虚拟槽
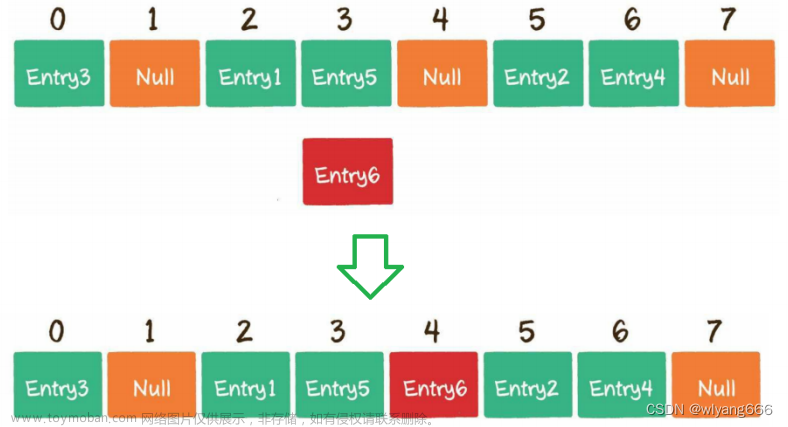
Redis将数据划分为16384个虚拟槽(slot),每个虚拟槽都有一个唯一的标识号(0到16383)。当Redis启动时,每个槽都没有数据,可以被任何节点负责。
3. 节点的加入和离开
当新的Redis节点加入集群时,它会从其他节点中获取一部分虚拟槽,这些槽将由新节点负责。同样,当节点离开集群时,它负责的槽将被其他节点接管。
4. 数据迁移
Redis采用数据迁移的方式来实现扩容。当新节点接管一些虚拟槽时,它会向其他节点请求这些槽的数据。其他节点将相应槽的数据发送给新节点,直到数据迁移完成。这种方式避免了大规模的数据迁移,因为只有少量槽的数据需要传输。
5. 容错性
Redis的扩容机制还具备容错性。如果某个节点离开了集群,其他节点会尽力接管它负责的槽,确保数据不会丢失。
一致性哈希算法
一致性哈希算法是一种用于数据分片和负载均衡的算法,它在分布式系统中广泛应用于缓存、分布式存储和负载均衡器等场景。下面我们将详细解释一致性哈希算法的原理。
1. 哈希环
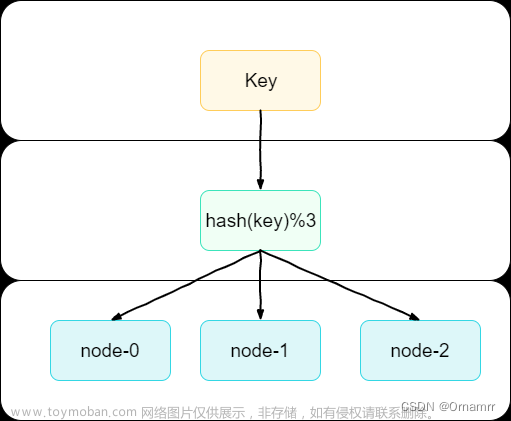
一致性哈希算法使用哈希环来表示所有可能的数据分片位置。哈希环是一个虚拟的圆环,其中每个数据节点和虚拟节点都在环上有唯一的位置。通常,通过计算节点的哈希值,可以确定节点在哈希环上的位置。
2. 数据分片
要将数据分布到节点上,首先将数据的键通过哈希函数映射到哈希环上的一个位置。然后,从这个位置开始,顺时针找到第一个节点,该节点即为数据的归属节点。这种方式保证了相同键的数据总是被映射到同一个节点上。
3. 负载均衡
一致性哈希算法的优点之一是,当节点加入或离开系统时,只有少量的数据需要重新分布,因此对系统的影响较小。当节点加入时,只需重新映射该节点负责的数据;当节点离开时,只需将其数据迁移到其他节点。
4. 节点故障容忍
一致性哈希算法还具备容错性。当某个节点故障时,只需将其数据迁移到下一个节点即可。这种方式避免了数据丢失和系统停机。
示例代码
为了更好地理解Redis的扩容机制和一致性哈希算法,下面提供示例代码。首先,我们来看一下如何使用Python实现一致性哈希算法。
import hashlib
class ConsistentHashing:
def __init__(self, nodes, replicas=3):
self.replicas = replicas
self.circle = {}
for node in nodes:
for i in range(replicas):
key = self._get_hash(f"{node}:{i}")
self.circle[key] = node
def _get_hash(self, key):
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def get_node(self, key):
if not self.circle:
return None
hash_val = self._get_hash(key)
sorted_keys = sorted(self.circle.keys())
for key in sorted_keys:
if hash_val <= key:
return self.circle[key]
return self.circle[sorted_keys[0]]
# 示例用法
nodes = ["node1", "node2", "node3"]
hash_ring = ConsistentHashing(nodes)
print(hash_ring.get_node("my_key"))
使用Python来模拟Redis集群的扩容过程。文章来源:https://www.toymoban.com/news/detail-678271.html
class RedisCluster:
def __init__(self, initial_nodes):
self.nodes = initial_nodes
def add_node(self, new_node):
self.nodes.append(new_node)
print(f"Node {new_node} added to the cluster.")
def remove_node(self, node_to_remove):
if node_to_remove in self.nodes:
self.nodes.remove(node_to_remove)
print(f"Node {node_to_remove} removed from the cluster.")
else:
print(f"Node {node_to_remove} not found in the cluster.")
# 示例用法
initial_nodes = ["node1", "node2", "node3"]
redis_cluster = RedisCluster(initial_nodes)
print("Current nodes:", redis_cluster.nodes)
redis_cluster.add_node("node4")
print("Updated nodes:", redis_cluster.nodes)
node_to_remove = "node2"
print("Current nodes:", redis_cluster.nodes)
redis_cluster.remove_node(node_to_remove)
print("Updated nodes:", redis_cluster.nodes)
结论
本文深入探讨了Redis的扩容机制和一致性哈希算法的原理。通过虚拟槽和数据迁移,Redis能够有效地实现扩容和节点间数据的平衡。一致性哈希算法则为分布式系统提供了数据分片和负载均衡的解决方案,通过哈希环和节点动态调整,实现了高效的数据分布和节点容错性。文章来源地址https://www.toymoban.com/news/detail-678271.html
到了这里,关于Redis扩容机制与一致性哈希算法解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!