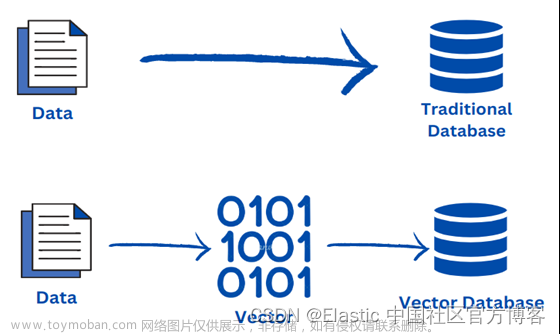
首先要理解es的存储结构:
一个index的数据,分散在多个shard(分片),一个分片又有很多segment(段),es是数据不可变模型,更新数据只是新增一个版本。
es是怎么写数据的?
每次写的时候,首先会写到es的内存(每个分片的内存),这时写的数据是不可搜索的;然后每个分片默认每秒钟会从内存里读写入的数据,然后新建一个段将数据写到段里(这个操作在es里就叫refresh),只有写到段里,数据才是可搜索的。也就是只有refresh了数据才能被搜索到,refresh的间隔默认是一秒,理论上es可以保证写入的数据,一秒后是可以被搜索到的,所以说es是近实时搜索。
将数据写到段里的时候,是如何保证磁盘io效率的?
我们知道磁盘io 要通过fsync系统调用,他的代价是很高的,那es是如何保证高效的写入效率呢?在es内存和磁盘文件之间的文件系统缓存,es是先将新段写入文件系统缓存(万一这时程度挂了呢,数据还没有持久化呢,怎么保证数据的一致性),这一步就快了很多了,稍后在将数据刷到磁盘,新段一旦写入文件系统缓存,就可以被打开和读取了,这样es就实现了新段还没有提交完(es中有提交点的概念),就可以进行查询了。
如何保证持久化
其实各类数据库都基本上是一种思路,同时将数据写入log,万一挂了从log里往回补数据,这里es的日志叫做translog,translog被提交的过程就叫做flush。
这里有的小伙伴可能会疑惑:写log不也是往写磁盘吗,难道就快了?因为这类写都是顺序io,非随机io,不用寻址的,效率堪比内存。
段的优化文章来源:https://www.toymoban.com/news/detail-678425.html
每秒钟都会refresh产生新的段,这么多是不是会影响查询效率,答案是毋庸置疑的,那怎么办?es还有一个段合并的机制,会定时的将小段合成大段。文章来源地址https://www.toymoban.com/news/detail-678425.html
到了这里,关于为什么说es是近实时搜索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!