python爬虫10:selenium库
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
1. 概述与安装
1.1 概述
selenium其实严格来说并不属于爬虫库,而是用于测试的库,不过这里我们就拿来当作爬虫库来用就行。
selenium相比于其他的爬虫库而言,更加综合,其既可以请求,也可以解析,并且过程是可视化的,即请求的时候,你可以看见程序打开浏览器,然后按照你设定的步骤进行。
1.2 安装
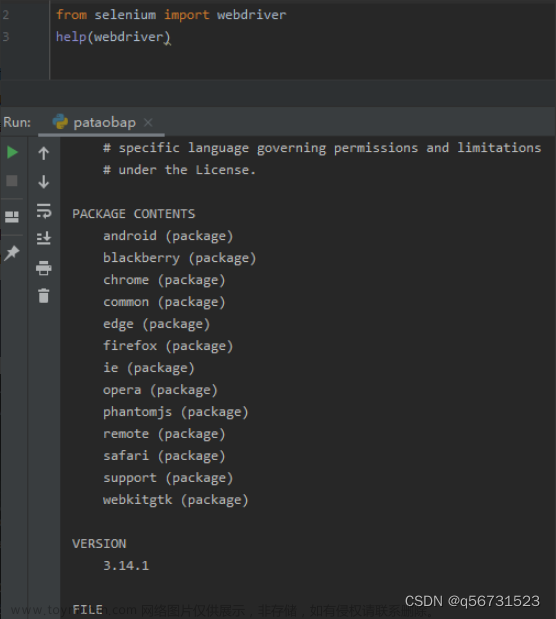
selenium的安装以前比较麻烦,需要自己去安装浏览器驱动,但是现在最新版本的selenium已经不需要我们自己装驱动了,当你运行代码的时候,会自动检测安装。
因此,只需要安装:
pip install selenium
可以用下面代码测试浏览器驱动是否安装(谷歌浏览器):
# 导包
from selenium import webdriver
# 浏览器初始化
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com')
# 打印源码
print(driver.page_source)
# 关闭
driver.quit()
其运行过程就是自动打开浏览器并打开百度搜索页面,然后返回源码。
2. 基本使用
2.1 声明浏览器对象
使用selenium,首先需要声明浏览器对象,除去我之前使用的chrome浏览器,还支持:Firefox、Edge等等,但是一般常用的是chrome浏览器,所以这里我只给出chrome浏览器的声明方法,其他的声明方法都类似,只需要修改浏览器名称即可。
# 导包
from selenium import webdriver
# 声明浏览器对象
driver = webdriver.Chrome()
2.2 访问页面
这里不分什么get或者post,统一的只有get方法。语法如下:
driver.get(url)
# 示例:
driver.get('https://www.baidu.com')
2.3 关闭访问页面和浏览器:
# 关闭访问页面和浏览器
driver.close()
# 关闭驱动
driver.quit()
2.4 查找节点方法:
查找单个节点:
作用:只返回第一个匹配的节点。
方法如下:driver.find_element()
常用参数:
1. by
需要导入from selenium.webdriver.common.by import By
指定获取元素的方式,常见的如:By.NAME(标签name属性获取)、By.ID(标签id属性获取)、By.CLASS_NAME(标签class属性获取)、By.TAG_NAME(标签名字获取)、By.XPATH(通过xpath语法获取)、By.CSS_SELECTOR(通过css选择器获取)......
2. value
配合上面的by参数,填写相应的值即可
查找多个节点
方法名只是多了一个s,变为了driver.find_elements(),参数都是一样的。
2.5 节点交互:
常用的节点交互有两种:输入与点击,这也是我们在浏览器中最常用的两种了。方法分别如下:
# 输入内容
xxx.send_keys('内容')# xxx代表着一个节点
xxx.clear() #清除输入的内容
# 点击
xxx.click()
下面给大家一个案例: 打开百度,输入python并且点击搜索按钮进行搜索,之后再删除python,搜索java
# 导包
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 浏览器声明
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com')
# 获取输入框节点
input_tag = driver.find_element(by=By.CLASS_NAME,value='s_ipt')
# 获取搜索按钮
search_tag = driver.find_element(by=By.XPATH,value='//input[@id="su"]')
# 输入python
input_tag.send_keys('python')
# 点击按钮
search_tag.click()
# 暂停2秒
time.sleep(2)
# 清楚python
input_tag.clear()
# 输入java
input_tag.send_keys('java')
# 搜索
search_tag.click()
# 暂停2秒
time.sleep(2)
# 退出
driver.close()
driver.quit()
运行结果如下动图所示:

2.6 动作链:
有些动作,如:拖拽、键盘按键等,没有具体的某个节点,这种方式就需要动作链来执行,你可以这样理解:你首先声明一个动作链对象,然后这个对象将一条一条的执行你写的代码。
这个方面需要大家自行查找官方文档,因为这个我日常用的不多,对于自己来说,也许只有破解验证码的时候才用得上,但是现在的验证码破解越来越难了,所以我基本上用不到这块。
2.7 获取网页信息和节点信息:
网页信息
网页源码:
方法: driver.page_source
作用:获取网页源码
网页标题:
方法:driver.title
作用:获取网页标题
节点信息:下面的xxx指的是的某个节点标签
获取属性:
方法: xxx.get_attribute('属性名字')
作用: 获取属性值
说明: xxx代表着节点
获取文本:
方法: xxx.text
作用: 获取文本值
获取其他信息:
获取id:
xxx.id
获取节点名称:
xxx.tag_name
获取节点在页面中的位置:
xxx.location (这个还是很有用的,对于滑动验证的验证码可以使用)
获取节点大小(宽和高):
xxx.size
2.8 执行js代码:
之前的功能,如:输入内容,点击按钮等,其他库可以使用其他方式实现,但是执行js代码确实selenium一个强大的功能。
比如:我们有时候爬取动态渲染的网页,如:百度图片,我们鼠标向下滑动,越来越多的图片加载出来,这就是动态渲染,或者我们有时候看见的“更多”(有些内容显示不全,点更多可以在当前页面查看全部内容)都是动态渲染,我们可以使用js代码模拟实现。
这个方面考察大家的js功底,如果不会的朋友也不用紧张,如果你需要啥功能可以在网上搜索,将网页的js代码拷贝下来即可。
语法如下:
driver.execute_script('js代码')
代码演示;(效果:直接滑动到网页底部)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 浏览器声明
driver = webdriver.Chrome()
# 打开一个网页
driver.get('https://tieba.baidu.com/f?kw=%B6%B7%CD%BC&fr=ala0&tpl=5')
# 执行js代码
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(5)
# 关闭
driver.close()
driver.quit()
结果演示:

2.9 切换Frame:
网页标签中有一个标签叫做frame标签,相当于一个子网页,而使用selenium打开网页默认在父级frame里面,因此想要获取子frame中的内容需要切换frame,方法如下:
driver.switch_to.frame(frame_reference=id或者name)
2.10 延时等待:
selenium打开网页,有时候需要注意网速是否良好,因为有时候你没有获取想要获取的信息就是因为网速不好。
除去使用time模块中的等待外,我们还可以使用selenium自带的延时等待。
隐式等待:
当查找的节点没有第一时间出现时,会等待指定时间后再来获取。
方法如下:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 浏览器声明
driver = webdriver.Chrome()
# 延时等待
driver.implicitly_wait(10) # 如果没有找到元素,等待10秒中
# 找元素
driver.find_element(by=By.TAG_NAME,value='div')
显示等待::
隐式等待效果并不好,因为如果在等待过程中加载出来了我们需要的标签,但是我们仍然得等待一定的时间。因此,我们需要更好的等待方式----显示等待。
作用:它指定最长等待时间,如果在这个时间内加载出来了节点,则直接获取节点,或则抛出超时异常。
方法如下:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 浏览器声明
driver = webdriver.Chrome()
# 显示等待
# 创建等待对象
wait = WebDriverWait(driver,10) #第二个参数是最大等待时间
tag = wait.until(EC.presence_of_element_located((By.ID,'q'))) # 这个作用:直到获取到id为q的节点
EC除去presence_of_element_located外,还有很多条件,具体的可以见官方库,但是使用方法都是这样。
2.11 切换窗口
有时候,我们用selenium请求了第一个网页后,又再次请求一个新的网页(或者你在第一个网页点击了某个按钮跳转到新网页),此时selenium权柄还停留在第一个网页,而我们想要获取第二个网页的信息,就需要切换权柄。
方法如下:
driver.window_handles # 查看所有的窗口权柄,返回一个列表,按照先后顺序出值
driver.current_window_handle # 当前的窗口权柄,和上面的可以对应看
driver.switch_to.window(xxx) # 切换窗口权柄,里面的xxx可以这么写 driver.window_handles[x](其中x为索引),具体的代码演示可以看下一篇的案例
3. 总结
本篇讲解了selenium的基础操作,由于selenium并不单单可以用于爬虫,还可以用于测试这个工作,因此其内容还有很多我们并没有涉及,这一点就需要靠大家根据自己的实际需求进行学习了。文章来源:https://www.toymoban.com/news/detail-678980.html
下一篇进行实战讲解。文章来源地址https://www.toymoban.com/news/detail-678980.html
到了这里,关于python爬虫10:selenium库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!