1. 均值、众数描述数据的集中趋势度量,四分位差、极差描述数据的离散程度。
2. 标准差、四分位差、异众比率度量离散程度,协方差是度量相关性。
期望值分别为E[X]与E[Y]的两个实随机变量X与Y之间的协方差Cov(X,Y)定义为:
 从直观上来看,协方差表示的是两个变量总体误差的期望。
从直观上来看,协方差表示的是两个变量总体误差的期望。
如果X与Y是统计独立的,那么二者之间的协方差就是0,因为两个独立的随机变量满足E[XY]=E[X]E[Y]。
但是,反过来并不成立。即如果X与Y的协方差为0,二者并不一定是统计独立的。
3. 卡方检验可以分析分类变量之间的相关性。http://t.csdn.cn/SZSy6
4. t检验:t检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。 只能分析数值型变量。
5. 皮尔逊相关系数是一种衡量变量之间线性关系强弱的统计量。它的取值范围在-1到1之间,可以反映出两个变量之间的相关程度。如果相关系数接近1,表明两个变量之间存在完全正向的线性关系;如果接近-1,则说明存在完全负向的线性关系;如果接近0,则表示两个变量之间没有线性关系。
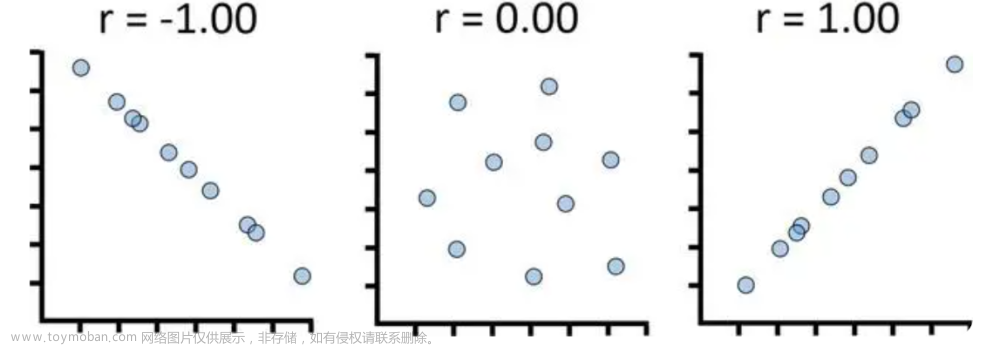
皮尔逊相关系数的计算方法如下:
r = Cov(X, Y) / (σX * σY)
其中,Cov(X, Y)表示变量X和Y的协方差,σX和σY分别表示变量X和Y的标准差。通过计算协方差和标准差,我们可以得到两个变量之间的相关系数。
只能分析数值型变量。
例子:百度安全验证
6. 列联相关:列联相关又称列联相关系数(contingencycorrelation)又称均方相依系数或接触系数,是指当两列数据中至少有一列是多分类资料时,描述变量之间的相互关系的品质相关系数。
可以分析分类变量之间的相关性。
7. SQL中的关键字:float浮点型、int 整数型、char 文本型、decimal 定点型
8. HAVING 子句中的筛选字段必须是可以出现在分组结果中的字段
9. 多维数据库——雪花模式
雪花模式是集中代表事实表的连接到多个层面 ,是类似星型模式 。
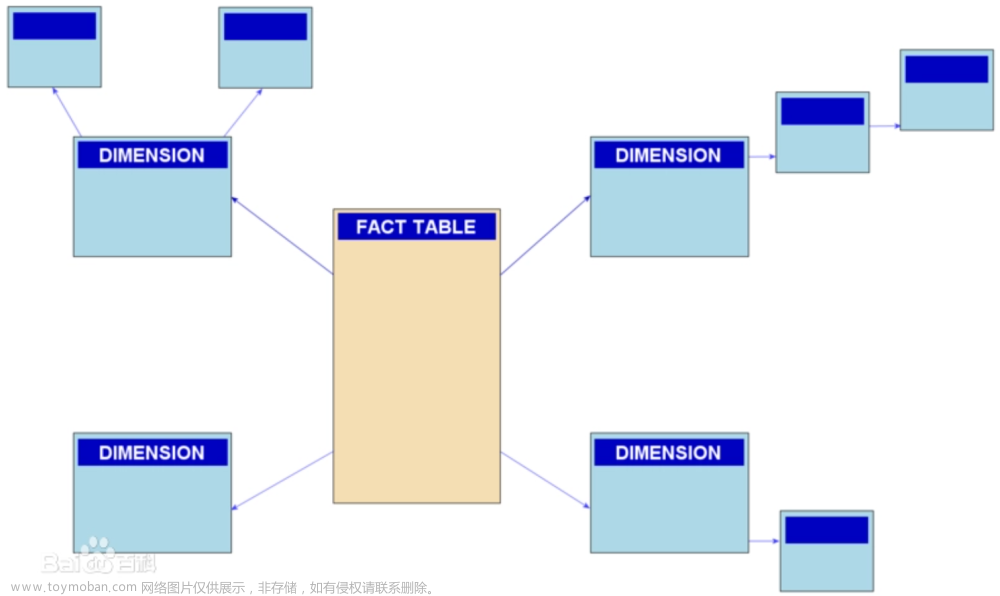
星型模型:星型模式是多维的数据关系,它由事实表(Fact Table)和维表(Dimension Table)组成。每个维表中都会有一个维作为主键,所有这些维的主键结合成事实表的主键。事实表的非主键属性称为事实,它们一般都是数值或其他可以进行计算的数据。

交叉模型:
 文章来源:https://www.toymoban.com/news/detail-679255.html
文章来源:https://www.toymoban.com/news/detail-679255.html
文章来源地址https://www.toymoban.com/news/detail-679255.html
到了这里,关于【数据分析】统计量的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!