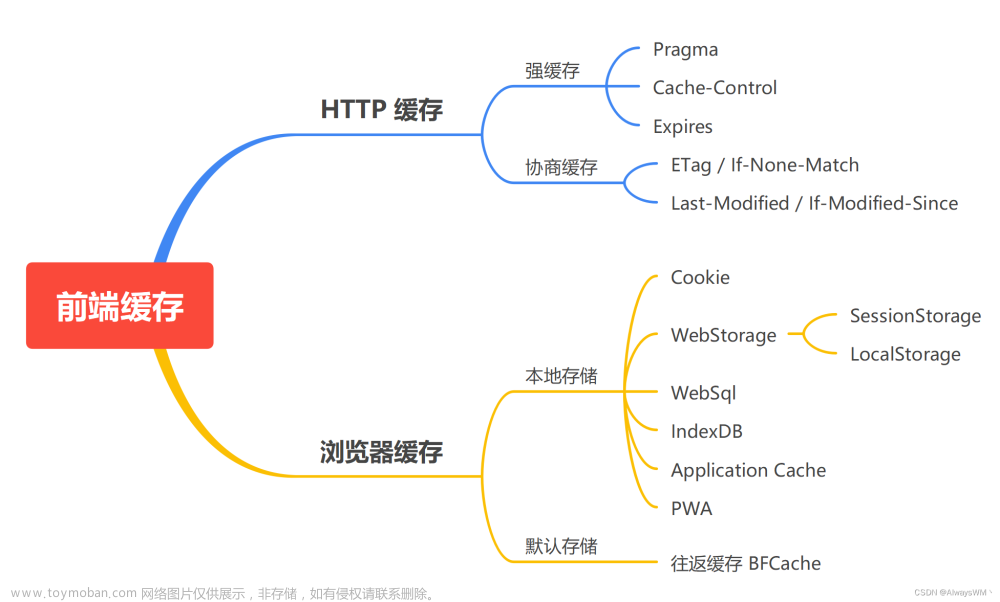
前面实现了一个 http-server,并且实现了 gzip 的压缩,下面通过前面几节学习的缓存知识来添加一下缓存。
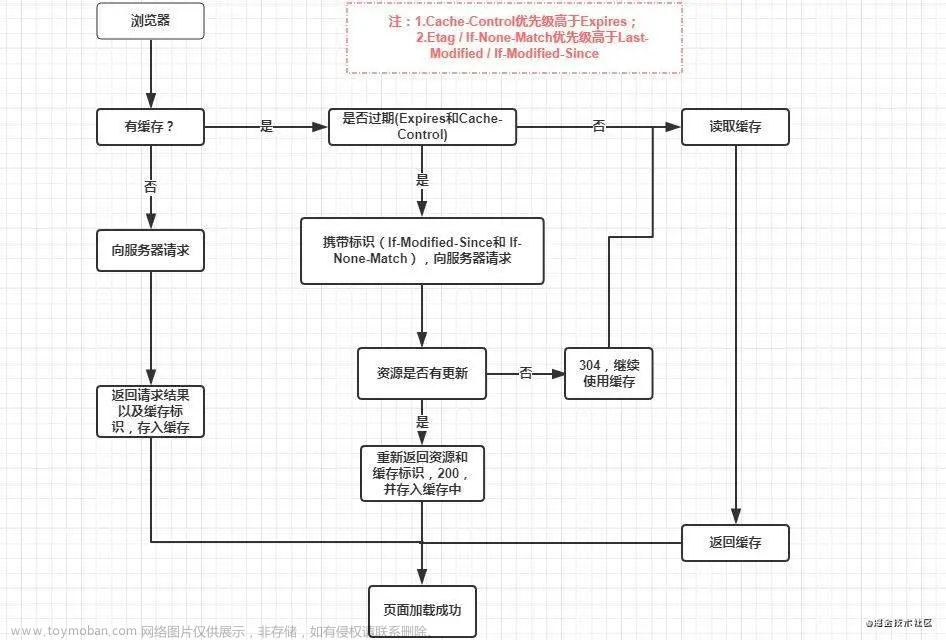
大致就是先强制缓存 10s,然后采用协商(对比)缓存,大致图如下
在之前的 http-server 的代码基础上添加 cache 方法的实现,实现如下:
// 核心模块
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs").promises;
const crypto = require("crypto");
const { createReadStream, createWriteStream, readFileSync } = require("fs");
// 第三方模块
const ejs = require("ejs"); // 服务端读取目录进行渲染
const mime = require("mime");
const chalk = require("chalk");
const debug = require("debug")("server");
// 根据环境变量来进行打印 process.env.EDBUG
debug("hello kaimo-http-server");
// 同步读取模板
const template = readFileSync(path.resolve(__dirname, "template.ejs"), "utf-8");
class Server {
constructor(config) {
this.host = config.host;
this.port = config.port;
this.directory = config.directory;
this.template = template;
}
async handleRequest(req, res) {
let { pathname } = url.parse(req.url);
// 需要对 pathname 进行一次转义,避免访问中文名称文件找不到问题
console.log(pathname);
pathname = decodeURIComponent(pathname);
console.log(pathname);
// 通过路径找到这个文件返回
let filePath = path.join(this.directory, pathname);
console.log(filePath);
try {
// 用流读取文件
let statObj = await fs.stat(filePath);
// 判断是否是文件
if (statObj.isFile()) {
this.sendFile(req, res, filePath, statObj);
} else {
// 文件夹的话就先尝试找找 index.html
let concatFilePath = path.join(filePath, "index.html");
try {
let statObj = await fs.stat(concatFilePath);
this.sendFile(req, res, concatFilePath, statObj);
} catch (e) {
// index.html 不存在就列出目录
this.showList(req, res, filePath, statObj, pathname);
}
}
} catch (e) {
this.sendError(req, res, e);
}
}
// 列出目录
async showList(req, res, filePath, statObj, pathname) {
// 读取目录包含的信息
let dirs = await fs.readdir(filePath);
console.log(dirs, "-------------dirs----------");
try {
let parseObj = dirs.map((item) => ({
dir: item,
href: path.join(pathname, item) // url路径拼接自己的路径
}));
// 渲染列表:这里采用异步渲染
let templateStr = await ejs.render(this.template, { dirs: parseObj }, { async: true });
console.log(templateStr, "-------------templateStr----------");
res.setHeader("Content-type", "text/html;charset=utf-8");
res.end(templateStr);
} catch (e) {
this.sendError(req, res, e);
}
}
gzip(req, res, filePath, statObj) {
if (req.headers["accept-encoding"] && req.headers["accept-encoding"].includes("gzip")) {
// 给响应头添加内容编码类型头,告诉浏览器内容是什么编码类型
res.setHeader("Content-Encoding", "gzip");
// 创建转化流
return require("zlib").createGzip();
} else {
return false;
}
}
// 设置缓存
async cache(req, res, filePath, statObj) {
// 先设置强制缓存
res.setHeader("Expires", new Date(Date.now() + 10 * 1000).toGMTString());
res.setHeader("Cache-Control", "max-age=10");
// 再设置协商缓存
let fileContent = await fs.readFile(filePath);
// 指纹
let ifNoneMatch = req.headers["if-none-match"];
let etag = crypto.createHash("md5").update(fileContent).digest("base64");
// 修改时间
let ifModifiedSince = req.headers["if-modified-since"];
let ctime = statObj.ctime.toGMTString();
res.setHeader("Last-Modified", ctime);
res.setHeader("ETag", etag);
// 文件变动了就不缓存,读取新文件
if (ifNoneMatch !== etag) {
return false;
}
if (ifModifiedSince !== ctime) {
return false;
}
return true;
}
// 读取文件返回
async sendFile(req, res, filePath, statObj) {
// 缓存
let cache = await this.cache(req, res, filePath, statObj);
// 有缓存直接让用户查找缓存即可
if (cache) {
res.statusCode = 304;
return res.end();
}
// 设置类型
res.setHeader("Content-type", mime.getType(filePath) + ";charset=utf-8");
// 读取文件进行响应
// 先判断浏览器是否支持 gzip 压缩
let gzip = this.gzip(req, res, filePath, statObj);
if (gzip) {
createReadStream(filePath).pipe(gzip).pipe(res);
} else {
createReadStream(filePath).pipe(res);
}
}
// 专门处理错误信息
sendError(req, res, e) {
debug(e);
res.statusCode = 404;
res.end("Not Found");
}
start() {
const server = http.createServer(this.handleRequest.bind(this));
server.listen(this.port, this.host, () => {
console.log(chalk.yellow(`Starting up kaimo-http-server, serving ./${this.directory.split("\\").pop()}\r\n`));
console.log(chalk.green(` http://${this.host}:${this.port}`));
});
}
}
module.exports = Server;
我们启动服务
kaimo-http-server

访问: http://localhost:3000/public/index.html

我们立即刷新,可以看到强制缓存

过了 10s 再次刷新我们可以看到变成协商缓存文章来源:https://www.toymoban.com/news/detail-679451.html
 文章来源地址https://www.toymoban.com/news/detail-679451.html
文章来源地址https://www.toymoban.com/news/detail-679451.html
到了这里,关于72 # http 缓存策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!