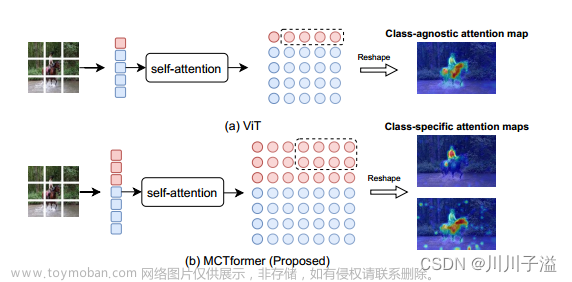
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models(2020的论文)
本文方法
代码地址
卷积什么的就不说了,主要看融合策略
下面是他的计算公式,大概就是结合空间注意力和通道注意力的一种算法
LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images
本文方法
基于深度学习的融合方法在图像融合任务中取得了可喜的性能。这归因于网络架构在融合过程中发挥着非常重要的作用。然而,总的来说,很难指定一个好的融合架构,因此,融合网络的设计仍然是一门黑术,而不是科学。为了解决这个问题,我们以数学方式制定融合任务,并在其最优解和可以实现它的网络架构之间建立联系。
这种方法导致论文中提出了一种构建轻量级融合网络的新方法。它通过尝试和测试策略避免了耗时的经验网络设计。特别是,我们采用可学习的表示方法来完成融合任务,其中融合网络架构的构建由产生可学习模型的优化算法指导。
低秩表示(LRR)目标是我们可学习模型的基础。作为解决方案核心的矩阵乘法被转换为卷积运算,并且优化的迭代过程被特殊的前馈网络取代。
基于这种新颖的网络架构,构建了端到端的轻量级融合网络来融合红外和可见光图像。它的成功训练得益于细节到语义信息损失函数的提出,该函数旨在保留图像细节并增强源图像的显着特征。我们的实验表明,所提出的融合网络比公共数据集上最先进的融合方法表现出更好的融合性能。有趣的是,我们的网络比其他现有方法需要更少的训练参数。
代码地址
学习低秩表征模型(LLRR)

X为输入数据
L为低秩系数
S为稀疏系数
D1和D2相当于对应base part and the salient part
换种表述形式,等价于上面那个
作者说这个可以加快收敛速度
最后的公式
然后就需要对这个公式进行求解,这一步不知道怎么得到的,偏导吗?

最后的结果
网络
 文章来源:https://www.toymoban.com/news/detail-679567.html
文章来源:https://www.toymoban.com/news/detail-679567.html
损失函数
作者说很重要




 文章来源地址https://www.toymoban.com/news/detail-679567.html
文章来源地址https://www.toymoban.com/news/detail-679567.html
到了这里,关于2023.8.28日论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!