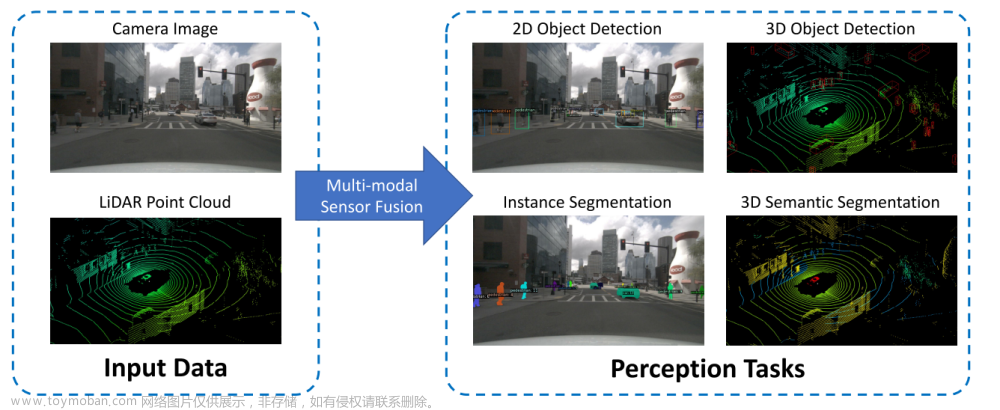
论文背景
自动驾驶(AD)任务通常分为感知、预测和规划。在传统范式中,AD中的每个学习模块分别使用自己的主干,独立地学习任务。
以前,基于端到端学习的方法通常基于透视视图相机和激光雷达信息直接输出控制命令或轨迹.
论文提出了基于BEV多模态的多任务端到端学习框架,专注于自动驾驶的预测和规划任务。
Bev 感知
基于相机的BEV方法将多视图相机图像特征转换到BEV空间中,从而实现端到端感知,而无需对重叠区域进行后处理。但是基于相机的感知方法距离感知精度不足,激光雷达可以提供准确的位置信息。将多模态特征转换到BEV空间中有助于融合这些特征。
BEV 融合将通过 LSS 方法获得的图像BEV特征与通过 Voxelnet 获得的 LiDAR BEV 特征连接起来,以获得融合的BEV特征,这提高了感知性能。SuperFusion 进一步提出了基于多模态地图感知的多阶段融合。
运动预测
继 VectorNet 之后,主流运动预测(或轨迹预测)方法通常利用 HD 地图和基于矢量的障碍表示来预测智能体的未来轨迹;在此基础上,LaneGCN 和 PAGA 通过细化的地图要素(如车道连接属性)增强轨迹地图匹配;此外,某些基于锚点的方法对地图附近的目标点进行采样,从而能够基于这些点进行轨迹预测。但是这些方法在很大程度上依赖于预先收集的高清地图,这使得它们不适合地图不可用的地区。矢量化预测方法往往缺乏高层语义信息,需要高清地图。
PnPNet 提出了一种新的跟踪模块,该模块从检测中在线生成对象轨迹,并利用轨迹级特征进行运动预测,但其整体框架基于CNN,运动预测模块相对简单,只有单模输出。由于 Transformer 被应用于检测和跟踪,VIP3D 成功地借鉴了以前的工作,并提出了第一个基于 transformer 的联合感知预测框架。Uniad 进一步整合了更多下游任务,提出了面向规划的端到端自动驾驶模型。在前人的基础上,对运动预测任务进行了更精细化的优化,引入了 refinement mechanism 和 mode-attention,使预测指标得到了很大的提高。
学习规划
模拟学习(IL)和强化学习(RL)已用于规划。IL和RL用于端到端方法(即,使用图像和/或激光雷达作为输入),或矢量化方法(即,使用矢量化感知结果作为输入)。
早期的端到端方法,如 ALVINN 和 PilotNet 通常直接输出控制命令或轨迹,而缺乏中间结果/任务。P3 ,MP3 ,UniAD 学习端到端可学习网络,该网络执行联合感知,预测和规划,这可以产生可解释的中间表示并提高最终规划性能。
尽管使用中间感知结果进行规划可以提高泛化性和透明度,但矢量化方法遭受后处理噪声和感知结果的变化。
这些方法要么只使用激光雷达输入,要么只使用相机输入,这限制了它们的性能。Transfuser 同时使用激光雷达和相机输入,但不在BEV空间中,而且仅执行少量AD学习任务作为辅助任务。
论文内容
首先,使用基于BEVFormer的图像编码器将相机图像映射到鸟瞰图(BEV)空间。然后将这些与BEV空间中的激光雷达特征相结合。在时间融合之后,融合后的BEV特征通过基于查询的方法用于检测、跟踪和映射任务。随后,tokens 被转发到运动和占用预测任务以及规划任务。
BEV编码器和感知
从 FusionFormer 获得灵感,论文提出了一个新的 3D 目标检测多模态时间融合框架的和一个基于Transformer的架构。为了提高效率,采用了类似于BEVFormer的复发性时间融合技术。与FusionFormer不同,论文使用BEV格式的特征作为LiDAR分支的输入,而不是体素特征。
多模态时间融合模块包括6个编码层。首先采用一组可学习的BEV查询器,分别使用点交叉注意和图像交叉注意来融合LiDAR特征和图像特征。然后,通过时间自我注意将所得特征与来自前一帧的历史BEV特征融合。查询在用作下一层的输入之前由前馈网络更新。在6层融合编码之后,生成最终的多模态时间融合BEV特征用于后续任务。
激光雷达
原始LiDAR点云数据首先被体素化,然后用于基于 SECOND 网络生成LiDAR BEV特征。
摄像机。多视点摄像机图像首先通过 backbone 网络进行处理以进行特征提取。然后,FPN 网络被用于生成多尺度图像特征。
交叉注意点
在点交叉注意过程中,每个BEV查询仅与其对应参考点周围的LiDAR BEV特征交互。这种互动是通过变形注意力来实现的:
P
C
A
(
Q
p
,
B
L
i
D
A
R
)
=
D
e
f
A
t
t
n
(
Q
p
,
P
,
B
L
i
D
A
R
)
(1)
\tag1 PCA(Q_p,B_{LiDAR})=DefAttn(Q_p,P,B_{LiDAR})
PCA(Qp,BLiDAR)=DefAttn(Qp,P,BLiDAR)(1)其中
Q
p
Q_p
Qp表示在点
p
=
(
x
,
y
)
p=(x,y)
p=(x,y)处的 BEV 查询,并且
B
L
i
D
A
R
B_{LiDAR}
BLiDAR表示从 LiDAR 分支输出的BEV 特征。P 是 BEV 空间中的坐标
p
=
(
x
,
y
)
p=(x,y)
p=(x,y)到 LiDAR BEV空间上的投影。
图像交叉注意
为了实现图像交叉注意,遵循与 BEVFormer 类似的方法。每个 BEV 查询都使用与支柱表示类似的高度尺寸展开。固定数量的
N
r
e
f
N_{ref}
Nref 3D参考点在每个柱中沿着其 Z 轴采样。图像交叉注意过程如下所示:
I
C
A
(
Q
p
,
F
)
=
1
V
h
i
t
∑
i
=
1
V
h
i
t
∑
j
=
1
N
r
e
f
D
e
f
A
t
t
n
(
Q
p
,
P
(
p
,
i
,
j
)
,
F
i
)
(2)
\tag2 ICA(Q_p, F) =\frac{1}{V_hit}\sum_{i=1}^{V_{hit}}\sum_{j=1}^{N_{ref}} DefAttn(Q_p, P(p, i, j), F_i)
ICA(Qp,F)=Vhit1i=1∑Vhitj=1∑NrefDefAttn(Qp,P(p,i,j),Fi)(2)其中
V
h
i
t
V_{hit}
Vhit 表示参考点可以投影到的相机视图的数量,
i
i
i 是相机视图的索引,
F
i
F_i
Fi 表示第
i
i
i 个相机的图像特征,并且
P
(
p
,
i
,
j
)
P(p,i,j)
P(p,i,j) 表示 BEV 查询
Q
p
Q_p
Qp 的3D参考点
(
x
,
y
,
z
i
)
(x,y,z_i)
(x,y,zi) 在第
i
i
i 个相机的图像坐标系上的投影。
时间自注意
仿照 BEVFormer 来实现时间自我注意。具体而言,基于车辆在帧之间的运动的历史帧BEV特征的时间对准。然后,利用时间自注意来融合历史帧BEV特征,如下所示:
T
S
A
(
Q
p
,
(
Q
,
B
t
−
1
′
)
)
=
∑
V
∈
{
Q
,
B
t
−
1
′
}
D
e
f
A
t
t
n
(
Q
p
,
p
,
V
)
(3)
\tag 3 TSA(Q_p,(Q,B_{t-1}^{'}))=\sum_{V\in \{ Q,B_{t-1}^{'}\}}DefAttn(Q_p,p,V)
TSA(Qp,(Q,Bt−1′))=V∈{Q,Bt−1′}∑DefAttn(Qp,p,V)(3)其中,
B
t
−
1
′
B_{t-1}^{'}
Bt−1′表示时间对齐后时间戳
t
−
1
t−1
t−1 处的 BEV 特征。
对于感知中的检测、跟踪和地图制作任务,论文主要遵循了 UniAD 的设置。
预测
由于更丰富的 BEV 特征,预测模块接收到更稳定和精细的信息。基于这一点,为了进一步捕获多模态分布并提高预测准确性,引入了模态自我关注(modality self-attention)和精炼网络(refinement net)。
 上下文感知模态关注
上下文感知模态关注
在 UniAD 中,数据集级统计锚被用于辅助多模态轨迹学习,锚间自注意被应用于提高锚的质量。然而,由于这些锚不考虑历史状态和地图信息,它们对多模态学习的贡献是有限的。
因此,我们正在考虑稍后添加此操作。在运动查询检索所有场景上下文以捕获 agent-agent, agent-map, and agent-goal 点信息之后,然后引入模态自注意以使各种模式之间的相互可见性,从而获得更好的质量和多样性。
Q
m
o
d
e
=
M
H
S
A
(
Q
u
)
(4)
\tag4 Q_{mode}=MHSA(Q_u)
Qmode=MHSA(Qu)(4)其中MHSA表示多头自注意。
Q
u
Q_u
Qu表示获得上下文信息的查询。
精细化网络
可变形注意力使用统计锚点作为参考轨迹与BEV特征进行交互。如前所述,这个参考轨迹增加了后续学习的难度,因为需要特定的场景信息。论文引入了一个精炼网络,利用由 Motionformer 生成的轨迹作为更准确的空间先验,查询场景背景,并预测地面真实轨迹与先验轨迹之间的偏移量。如下所示:
Q
R
=
D
e
f
A
t
t
n
(
A
n
c
h
o
r
p
,
x
^
m
,
B
)
(5)
\tag 5 Q_R = DefAttn(Anchor_p,\hat x_m,B)
QR=DefAttn(Anchorp,x^m,B)(5)其中
A
n
c
h
o
r
p
Anchor_p
Anchorp 表示空间先验。使用一个简单的 MLP 对 Motionformer 输出的轨迹进行编码,并在时间维上执行 maxpool 得到
A
n
c
h
o
r
p
Anchor_p
Anchorp。
x
^
m
\hat x_m
x^m 表示Motionformer输出轨迹的终点。
规划
在评估过程中,无法访问高清(HD)地图或预定义路线。因此论文依靠可学习的命令嵌入来表示导航信号(包括左转、右转和保持前进)来指引方向。为了获得周围的嵌入,输入的计划查询,其中包括自我查询和命令嵌入,到鸟瞰图(BEV)功能。
然后,将其与自我车辆的嵌入融合,该嵌入由MLP网络处理,以获得状态嵌入。然后将该状态嵌入解码到未来的路点中。

L
t
r
a
=
λ
c
o
l
L
c
o
l
(
τ
^
,
b
)
+
λ
i
m
i
L
i
m
i
(
τ
^
,
τ
˜
)
(6)
\tag 6\mathcal L_{tra} = \lambda_{col}\mathcal L_{col}(\hat \tau , b)+ \lambda_{imi}\mathcal L_{imi}(\hat \tau , \~\tau )
Ltra=λcolLcol(τ^,b)+λimiLimi(τ^,τ˜)(6)其中
λ
i
m
i
=
1
λ_{imi} = 1
λimi=1,
λ
c
o
l
=
2.5
λ_{col} = 2.5
λcol=2.5,
τ
^
\hat τ
τ^是原始规划结果,
τ
˜
\~τ
τ˜ 表示规划标签,并且
b
b
b表示场景中预测的代理。碰撞损失计算公式如下:
L
c
a
l
(
τ
^
,
b
)
=
1
N
2
∑
i
=
0
N
max
(
1
,
∑
t
=
0
P
L
p
a
i
r
(
τ
^
t
,
b
i
t
)
)
L
p
a
i
r
(
τ
^
t
,
b
i
t
)
=
{
1
−
d
r
i
+
r
j
,
if
d
≤
r
i
+
r
j
0
,
otherwise
(7)
\tag7 \mathcal L_{cal}(\hat \tau,b) = \frac{1}{N^2}\sum_{i=0}^{N}\max (1,\sum_{t=0}^{P}\mathcal L_{pair}(\hat \tau^t,b_i^t)) \\\mathcal L_{pair}(\hat \tau^t,b_i^t)=\begin{cases} 1-\frac{d}{r_i+r_j}, &\text{if } d\leq r_i+r_j \\ 0, &\text{otherwise} \end{cases}
Lcal(τ^,b)=N21i=0∑Nmax(1,t=0∑PLpair(τ^t,bit))Lpair(τ^t,bit)={1−ri+rjd,0,if d≤ri+rjotherwise(7)此外,在推理过程中,为了进一步确保轨迹的安全性和平滑性,使用 Newton’s method 执行轨迹优化,利用来自占用预测模型的占用预测结果。
训练
采用了三个阶段的培训来进行多传感器、多任务学习。
在第一阶段,只训练BEV编码器和感知任务;
在第二阶段,固定BEV编码器,然后训练感知、预测和规划任务;
在可选的第三阶段,进一步训练占据和规划任务,同时固定所有其他组件。
这种分阶段的培训方法有助于逐步构建和优化模型,以达到更好的性能和泛化能力。文章来源:https://www.toymoban.com/news/detail-679925.html
总结
FusionAD 是一种利用BEV融合来促进多感官,多任务,端到端学习的新方法,从而显着增强自动驾驶领域的预测和规划任务。所提出的方法强调了扩展一个统一的端到端的框架,以融合为基础的方法有效的潜力。文章来源地址https://www.toymoban.com/news/detail-679925.html
到了这里,关于FusionAD:用于自动驾驶预测和规划任务的多模态融合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[论文阅读]MV3D——用于自动驾驶的多视角3D目标检测网络](https://imgs.yssmx.com/Uploads/2024/02/721503-1.png)