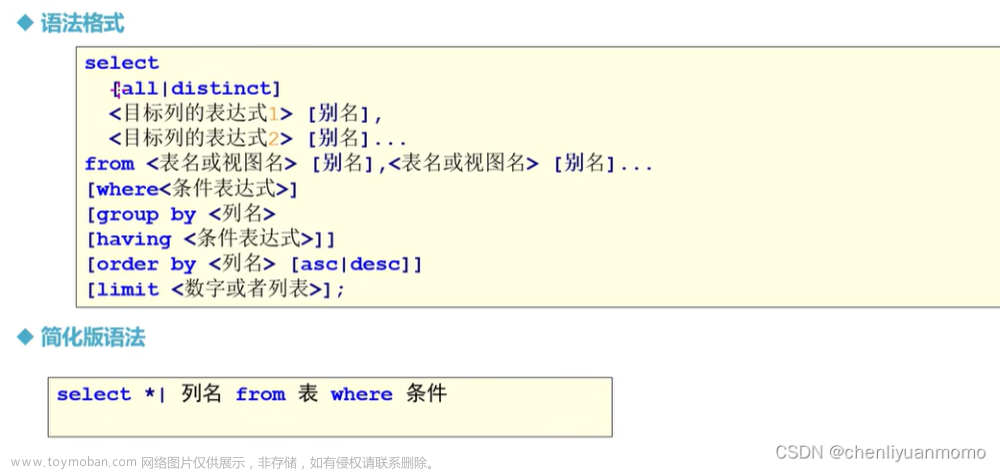
目录
Update
将小白龙的数学成绩跟新为 80 分
将总成绩后三名的数学成绩+30分
Delete
删除沙悟净的成绩
删除倒数第一名的成绩
Truncate
聚合函数
count
查看员工表里面的人数
查看男女员工的个数
查看男员工占所有员工个数的比例
sum
计算所有员工的工资和
计算各个部门的工资和
MAX
计算所有员工的最大工资
计算各个部门的最大的工资
MIN
计算工资的最小值
计算各个部门的最小工资
AVG
计算工资的平均值
计算各部的平均工资
计算出平均工资小于5000的部门,并计算出该部门的平均工资
最后我们看一下,还是上面的那个查询,但是多了个条件,不包括女儿国王
Update
update table_name set 列名=value [oeder by ...][where ...][limit ...];下面我们将该表的数据进行跟新:
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 20 | 19 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)将小白龙的数学成绩跟新为 80 分
mysql> update exam_result set math=80 where name='小白龙';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 60 | 56 |
| 6 | 沙悟净 | 77 | 87 | 72 |
| 7 | 小白龙 | 99 | 80 | 19 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)上面就是跟新时实用 where 子句,下面看一下使用其他的可选项。
将总成绩后三名的数学成绩+30分
1.首先查出所有人的总成绩
mysql> select name, chinese+english+math 总分 from exam_result order by 总分;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 唐三藏 | 188 |
| 小白龙 | 198 |
| 沙悟净 | 236 |
| 赵姨娘 | 262 |
| 薛宝钗 | 266 |
| 林黛玉 | 287 |
+-----------+--------+
6 rows in set (0.00 sec)2.通过 limit 查出后三名
mysql> select name, chinese+english+math 总分 from exam_result order by 总分 limit 3;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 唐三藏 | 188 |
| 小白龙 | 198 |
| 沙悟净 | 236 |
+-----------+--------+
3 rows in set (0.00 sec)3.将他们的数学成绩加30
mysql> update exam_result set math=math+30 order by chinese+english+math limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0上面就将总成绩的后三名的数学成绩加了三十分,在加的是 math=math+30 这是因为在 mysql 里面没有 += ,送一就只能这样写。
order by 那里没有显示的写 asc 是因为 order by 默认就是升序。
这里强调一下其实 update 如果后面没有限制的话,就会把所有的数据都会修改,所以 uodate 还是需要注意一点使用的。
Delete
delete from table_name [order by ...] [where ...] [limit ...];删除沙悟净的成绩
mysql> delete from exam_result where name='沙悟净';
Query OK, 1 row affected (0.01 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 5 | 唐三藏 | 72 | 90 | 56 |
| 7 | 小白龙 | 99 | 110 | 19 |
+----+-----------+---------+------+---------+
5 rows in set (0.00 sec)删除倒数第一名的成绩
1.查找处倒数第一名
mysql> select *, chinese+english+math 总分 from exam_result order by 总分 limit 1;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | 总分 |
+----+-----------+---------+------+---------+--------+
| 5 | 唐三藏 | 72 | 90 | 56 | 218 |
+----+-----------+---------+------+---------+--------+
1 row in set (0.00 sec)2.删除倒数第一名
mysql> delete from exam_result order by chinese+math+english limit 1;
Query OK, 1 row affected (0.01 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 林黛玉 | 98 | 90 | 99 |
| 3 | 薛宝钗 | 88 | 90 | 88 |
| 4 | 赵姨娘 | 79 | 90 | 93 |
| 7 | 小白龙 | 99 | 110 | 19 |
+----+-----------+---------+------+---------+
4 rows in set (0.00 sec)下面创建一个拥有自增值的一个表,然后测试 delete:
mysql> create table test_delete(
-> id int auto_increment primary key,
-> name varchar(12));
Query OK, 0 rows affected (0.00 sec)
mysql> desc test_delete;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(12) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)插入数据:
mysql> insert into test_delete(name) values('A');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test_delete(name) values('B');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test_delete(name) values('C');
Query OK, 1 row affected (0.00 sec)
mysql> select* from test_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)有 zuto_increment 字段的数据,查看表创建的时候还会有一个 auto_increment 的值:
mysql> show create table test_delete\G
*************************** 1. row ***************************
Table: test_delete
Create Table: CREATE TABLE `test_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)下面 delete 删除掉该表数据:
mysql> delete from test_delete;
Query OK, 3 rows affected (0.00 sec)
mysql> select * from test_delete;
Empty set (0.00 sec)删除后,下面查看表的创建:
mysql> show create table test_delete\G
*************************** 1. row ***************************
Table: test_delete
Create Table: CREATE TABLE `test_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)查看后发现 auto_increment 的默认值并没有发生改变,下面继续插入数据查看:
mysql> insert into test_delete(name) values('D');
Query OK, 1 row affected (0.01 sec)
mysql> select * from test_delete;
+----+------+
| id | name |
+----+------+
| 4 | D |
+----+------+
1 row in set (0.00 sec)auto_increment 的默认值每日有发生变化。
Truncate
truncate [table] table_name;truncate 也是一种删除,只不过 delete 可以对某一记录进行删除,而 truncate 只能对整表进行删除。
除了上面的区别,实际上 truncate 还可以对 auto_increment 的默认值进行清空,truncate 这样的操作也不会通过事务:
mysql> create table test_truncate(
-> id int primary key auto_increment,
-> name varchar(12));
Query OK, 0 rows affected (0.01 sec)
mysql> desc test_truncate;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(12) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)下面同样插入数据:
mysql> insert into test_truncate(name) values('A');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test_truncate(name) values('B');
Query OK, 1 row affected (0.00 sec)
mysql> insert into test_truncate(name) values('C');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)插入数据后进行 teuncate 删除:
mysql> truncate table test_truncate;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_truncate;
Empty set (0.00 sec)闪出成功后查看表的创建:
mysql> show create table test_truncate\G
*************************** 1. row ***************************
Table: test_truncate
Create Table: CREATE TABLE `test_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)这里的 auto_increment 没有了,但是这里的没有表示从新开始:
mysql> insert into test_truncate(name) values('D');
Query OK, 1 row affected (0.01 sec)
mysql> select * from test_truncate;
+----+------+
| id | name |
+----+------+
| 1 | D |
+----+------+
1 row in set (0.00 sec)上面插入数据后查看 auto_increment 确实是重新开始了。
在 mysql 中还是可以使用函数的,其中mysql 也给我们提供了一下聚合函数,首先看一下聚合函数:
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
上面是 mysql 中比较常用的聚合函数。下面可以看一下如何使用。
下面创建一个表:
mysql> create table employee(
-> id int primary key auto_increment,
-> name varchar(12),
-> gender varchar(2),
-> dept varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc employee;
+--------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(12) | YES | | NULL | |
| gender | varchar(2) | YES | | NULL | |
| dept | varchar(20) | YES | | NULL | |
+--------+-------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)对员工表里面插入数据:
mysql> insert into employee(name, gender, dept) values('孙悟空','男', '安全部门');
Query OK, 1 row affected (0.01 sec)
mysql> insert into employee(name, gender, dept) values('玉皇大帝','男', '政治部门');
Query OK, 1 row affected (0.01 sec)
mysql> insert into employee(name, gender, dept) values('女儿国王','女', '辅助部门');
Query OK, 1 row affected (0.00 sec)
mysql> insert into employee(name, gender, dept) values('白骨精','女', '辅助部门');
Query OK, 1 row affected (0.01 sec)
mysql> insert into employee(name, gender, dept) values('猪八戒','男', '安全部门');
Query OK, 1 row affected (0.00 sec)
mysql> insert into employee(name, gender, dept) values('白龙马','男', '交通部门');
Query OK, 1 row affected (0.00 sec)
mysql> insert into employee(name, gender, dept) values('观音菩萨','女', '政治部门');
Query OK, 1 row affected (0.00 sec)
mysql> select * from employee;
+----+--------------+--------+--------------+
| id | name | gender | dept |
+----+--------------+--------+--------------+
| 1 | 孙悟空 | 男 | 安全部门 |
| 2 | 玉皇大帝 | 男 | 政治部门 |
| 3 | 女儿国王 | 女 | 辅助部门 |
| 4 | 白骨精 | 女 | 辅助部门 |
| 5 | 猪八戒 | 男 | 安全部门 |
| 6 | 白龙马 | 男 | 交通部门 |
| 8 | 观音菩萨 | 女 | 政治部门 |
+----+--------------+--------+--------------+
7 rows in set (0.00 sec)count
查看员工表里面的人数
mysql> select count(*) from employee;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.01 seccount 既可以用 * 也可以用 1
mysql> select count(1) from employee;
+----------+
| count(1) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)下面为该表加一个工资列:
mysql> alter table employee add sal decimal(7,2);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc employee;
+--------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(12) | YES | | NULL | |
| gender | varchar(2) | YES | | NULL | |
| dept | varchar(20) | YES | | NULL | |
| sal | decimal(7,2) | YES | | NULL | |
+--------+--------------+------+-----+---------+----------------+
5 rows in set (0.01 sec)为该列插入数据:
mysql> select * from employee;
+----+--------------+--------+--------------+----------+
| id | name | gender | dept | sal |
+----+--------------+--------+--------------+----------+
| 1 | 孙悟空 | 男 | 安全部门 | 13000.00 |
| 2 | 玉皇大帝 | 男 | 政治部门 | 8000.00 |
| 3 | 女儿国王 | 女 | 辅助部门 | 5000.00 |
| 4 | 白骨精 | 女 | 辅助部门 | 4500.00 |
| 5 | 猪八戒 | 男 | 安全部门 | 10000.00 |
| 6 | 白龙马 | 男 | 交通部门 | 5500.00 |
| 8 | 观音菩萨 | 女 | 政治部门 | 15000.00 |
+----+--------------+--------+--------------+----------+
7 rows in set (0.00 sec)下面可不可以查看员工表里面的人的个数,然后在查看名字呢?
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'CURD.employee.name'; this is incompatible with sql_mode=only_full_group_by不可以,这是为什么?
因为这里需要的是聚合函数,而 count 聚合所有值之后会变成一个值,但是名字是多个,所以无法聚合,只有分组之后才可以。
group by 列名上面就是分组的语法,可以分组后查看。
查看男女员工的个数
mysql> select gender,count(1) from employee group by gender;
+--------+----------+
| gender | count(1) |
+--------+----------+
| 女 | 3 |
| 男 | 4 |
+--------+----------+
2 rows in set (0.00 sec)查看男员工占所有员工个数的比例
mysql> select (select count(1) from employee where gender='男')/((select count(*) from employee) + 0.0) 男生占比;
+--------------+
| 男生占比 |
+--------------+
| 0.5714 |
+--------------+
1 row in set (0.00 sec)sum
计算所有员工的工资和
mysql> select sum(sal) from employee;
+----------+
| sum(sal) |
+----------+
| 61000.00 |
+----------+
1 row in set (0.00 sec)计算各个部门的工资和
mysql> select dept, sum(sal) from employee group by dept;
+--------------+----------+
| dept | sum(sal) |
+--------------+----------+
| 交通部门 | 5500.00 |
| 安全部门 | 23000.00 |
| 政治部门 | 23000.00 |
| 辅助部门 | 9500.00 |
+--------------+----------+
4 rows in set (0.00 sec)MAX
计算所有员工的最大工资
mysql> select max(sal) 最大 from employee;
+----------+
| 最大 |
+----------+
| 15000.00 |
+----------+
1 row in set (0.01 sec)计算各个部门的最大的工资
mysql> select dept,max(sal) 最大工资 from employee group by dept;
+--------------+--------------+
| dept | 最大工资 |
+--------------+--------------+
| 交通部门 | 5500.00 |
| 安全部门 | 13000.00 |
| 政治部门 | 15000.00 |
| 辅助部门 | 5000.00 |
+--------------+--------------+
4 rows in set (0.00 sec)MIN
计算工资的最小值
mysql> select min(sal) 最小工资 from employee;
+--------------+
| 最小工资 |
+--------------+
| 4500.00 |
+--------------+
1 row in set (0.01 sec)计算各个部门的最小工资
mysql> select dept,min(sal) 最小工资 from employee group by dept;
+--------------+--------------+
| dept | 最小工资 |
+--------------+--------------+
| 交通部门 | 5500.00 |
| 安全部门 | 10000.00 |
| 政治部门 | 8000.00 |
| 辅助部门 | 4500.00 |
+--------------+--------------+
4 rows in set (0.00 sec)AVG
计算工资的平均值
mysql> select avg(sal) 平均工资 from employee;
+--------------+
| 平均工资 |
+--------------+
| 8714.285714 |
+--------------+
1 row in set (0.00 sec)计算各部的平均工资
mysql> select dept,avg(sal) 平均工资 from employee group by dept;
+--------------+--------------+
| dept | 平均工资 |
+--------------+--------------+
| 交通部门 | 5500.000000 |
| 安全部门 | 11500.000000 |
| 政治部门 | 11500.000000 |
| 辅助部门 | 4750.000000 |
+--------------+--------------+
4 rows in set (0.00 sec)计算出平均工资小于5000的部门,并计算出该部门的平均工资
mysql> select dept,avg(sal) 平均工资 from employee group by dept having 平均工资 < 5000;
+--------------+--------------+
| dept | 平均工资 |
+--------------+--------------+
| 辅助部门 | 4750.000000 |
+--------------+--------------+
1 row in set (0.00 sec)这里使用了 having ,having 就是在聚合后使用的。
下面看一下 having 和 where 的区别:
mysql> select * from employee having dept != '安全部门';
+----+--------------+--------+--------------+----------+
| id | name | gender | dept | sal |
+----+--------------+--------+--------------+----------+
| 2 | 玉皇大帝 | 男 | 政治部门 | 8000.00 |
| 3 | 女儿国王 | 女 | 辅助部门 | 5000.00 |
| 4 | 白骨精 | 女 | 辅助部门 | 4500.00 |
| 6 | 白龙马 | 男 | 交通部门 | 5500.00 |
| 8 | 观音菩萨 | 女 | 政治部门 | 15000.00 |
+----+--------------+--------+--------------+----------+
5 rows in set (0.00 sec)这里呢看到 having 还可以像 where 一样,那么看一下刚才的那一句查询可不可以使用 where:
mysql> select dept,avg(sal) 平均工资 from employee group by dept where 平均工资 < 5000;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'where 平均工资 < 5000' at line 1上面不能那样使用,实际上 having 也是有执行顺序的,下面我们先简单的说一下他们的执行顺序。
-
首先需要有表,也就是 from table_name
-
有了表之后就要开始筛选数据也就是 where 筛选数据
-
筛选出来数据后,就得到了 select 后面的那些数据
-
得到哪些数据后,开始分组等
-
分组完成后 having 进行最后的筛选
最后我们看一下,还是上面的那个查询,但是多了个条件,不包括女儿国王
mysql> select dept,avg(sal) 平均工资 from employee where name != '女儿国王' group by dept having 平均工资 < 5000;
+--------------+--------------+
| dept | 平均工资 |
+--------------+--------------+
| 辅助部门 | 4500.000000 |
+--------------+--------------+
1 row in set (0.00 sec)这里详细的看一下执行顺序
-
from employee
-
where name != '女儿国王'
-
dept,avg(sal) 平均工资
-
group by dept文章来源:https://www.toymoban.com/news/detail-680079.html
-
having 平均工资 < 5000文章来源地址https://www.toymoban.com/news/detail-680079.html
到了这里,关于mysql 基本操作2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[MySQL]基本数据类型及表的基本操作](https://imgs.yssmx.com/Uploads/2024/02/781101-1.gif)