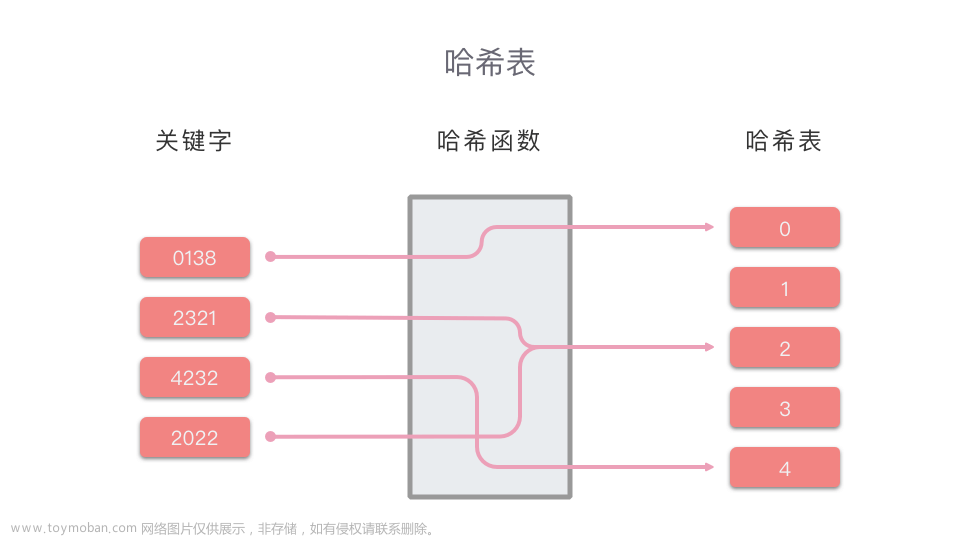
1、当需要快速判断某元素是否出现在序列中时,就要用到哈希表了。
2、本文针对的总结题型为给定两个及多个数组,求解它们的交集。接下来,按照由浅入深层层递进的顺序总结以下几道题目。
3、以下题目需要共同注意的是:对于两个数组,我们总是尽量把短数组转换为哈希表,以减少后续在哈希表中的元素查找时间。
349. 两个数组的交集
简单要求:交集结果不考虑重复情况
from typing import List
'''
349. 两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2]
题眼:交集(快速判断元素是否出现在序列中)+输出结果每个元素唯一的,不考虑结果中的重复情况
思路1、哈希表用set(),将两个数组全部转换为哈希表
思路2、哈希表用dict(),将短数组转换为哈希表
'''
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
# 思路1、哈希表用set()
# nums1hash = set(nums1) # 集合这种数据结构有点变态,直接去掉了重复元素,让遍历的计算量更小了
# nums2hash = set(nums2)
# result = []
# for n in nums2hash:
# if n in nums1hash:
# result.append(n)
# return result
# 思路2、哈希表用dict()
hashTable = {}
result = []
# 使得nums1指向短数组
if len(nums1) > len(nums2):
nums1, nums2 = nums2, nums1
# 将短数组转换为哈希表,以减少在哈希表中的元素查找时间
for n in nums1:
if n not in hashTable:
hashTable[n] = 1
for n in nums2:
if n in hashTable:
result.append(n)
hashTable.pop(n) # 避免重复,将添加过的key删除掉
return result
if __name__ == "__main__":
obj = Solution()
while True:
try:
in_line = input().strip().split('=')
nums1 = [int(n) for n in in_line[1].split(']')[0].split('[')[1].split(',')]
nums2 = [int(n) for n in in_line[2].split(']')[0].split('[')[1].split(',')]
print(nums1)
print(nums2)
print(obj.intersection(nums1, nums2))
except EOFError:
break
350. 两个数组的交集 II
简单要求提升:交集结果需要考虑重复情况,在“349. 两个数组的交集”上进行扩展。文章来源:https://www.toymoban.com/news/detail-680216.html
from typing import List
'''
350. 两个数组的交集 II
给你两个整数数组nums1 和 nums2 ,请你以数组形式返回两数组的交集。
返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结果的顺序。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
题眼:交集(快速判断元素是否出现在序列中)+输出结果每个元素按照最少的,考虑结果中的重复情况
思路2:两个数组全部转换成dict进行查找
'''
class Solution:
def intersect(self, nums1: List[int], nums2: List[int]) -> List[int]:
# 思路1:在“349. 两个数组的交集”上进行扩展
hashTable = {}
result = []
# 使得nums1指向短数组
if len(nums1) > len(nums2):
nums1, nums2 = nums2, nums1
# 将短数组转换为哈希表,以减少在哈希表中的元素查找时间
for n in nums1:
if n not in hashTable:
hashTable[n] = 1
else:
hashTable[n] += 1
for n in nums2:
if n in hashTable:
result.append(n)
hashTable[n] -= 1
if hashTable[n] == 0: # 将添加完的key删除掉
hashTable.pop(n)
return result
# # 思路2:两个数组全部转换成dict进行查找
# hashTable1, hashTable2 = {}, {}
# result = []
# # 使得nums1指向短数组
# if len(nums1) > len(nums2):
# nums1, nums2 = nums2, nums1
# # 先将两个数组转换为dict
# for n in nums1:
# if n not in hashTable1:
# hashTable1[n] = 1
# else:
# hashTable1[n] += 1
# for n in nums2:
# if n not in hashTable2:
# hashTable2[n] = 1
# else:
# hashTable2[n] += 1
# # 对两个dict进行遍历,并添加存在交集时的最少元素
# for key in hashTable2:
# if key in hashTable1: # 在短数组的哈希表中检索,以减少在哈希表中的元素查找时间
# for _ in range(min(hashTable1[key], hashTable2[key])):
# result.append(key)
# return result
if __name__ == "__main__":
obj = Solution()
while True:
try:
in_line = input().strip().split('=')
in_line1 = in_line[1].split('[')[1].split(']')[0]
nums1 = []
if in_line1 != '':
for n in in_line1.split(','):
nums1.append(int(n))
in_line2 = in_line[2].split('[')[1].split(']')[0]
nums2 = []
if in_line2 != '':
for n in in_line2.split(','):
nums2.append(int(n))
print(obj.intersect(nums1, nums2))
except EOFError:
break
1002. 查找共用字符
简单要求继续提升:交集结果需要考虑重复情况,同时给定的数组为N个了,在“350. 两个数组的交集 II”上进行扩展;需要注意 当出现一次两个字符串交集为空时,直接返回结果,结束代码运行文章来源地址https://www.toymoban.com/news/detail-680216.html
from typing import List
'''
1002. 查找共用字符
给你一个字符串数组 words ,请你找出所有在 words 的每个字符串中都出现的共用字符( 包括重复字符),
并以数组形式返回。你可以按 任意顺序 返回答案。
示例 1:
输入:words = ["bella","label","roller"]
输出:["e","l","l"]
思路:“350. 两个数组的交集 II”的扩展题型,由两个数组找交集扩展到N个数组找交集
'''
class Solution:
def commonChars(self, words: List[str]) -> List[str]:
# 情况1、字符串数组长度为1
if len(words) == 1:
return []
# 情况2、
result = self.commmon(words[0], words[1]) # 先求两个字符串达到交集
if result == '': # 当出现一次两个字符串交集为空时,直接返回结果,结束代码运行
return []
for i in range(2, len(words)): # 从第三个字符串开始比较
result = self.commmon(result, words[i])
if result == '': # 当出现一次两个字符串交集为空时,直接返回结果,结束代码运行
return []
return list(result)
# 返回两个字符串的交集,并将结果也设置为字符串:“350. 两个数组的交集 II”的实现过程
def commmon(self, str1: str, str2: str) -> str:
if len(str1) > len(str2):
str1, str2 = str2, str1
# 将短字符串转化为dict
hashTable = {}
for ch in str1:
if ch not in hashTable:
hashTable[ch] = 1
else:
hashTable[ch] += 1
# 遍历长字符串
result = []
for ch in str2:
if ch in hashTable:
result.append(ch)
hashTable[ch] -= 1
if hashTable[ch] == 0:
hashTable.pop(ch)
return ''.join(result)
if __name__ == "__main__":
obj = Solution()
while True:
try:
in_line = input().strip().split('=')[1].strip()[1: -1]
words = []
if in_line != '':
for s in in_line.split(','):
words.append(s[1: -1])
print(obj.commonChars(words))
except EOFError:
break
到了这里,关于leetcode分类刷题:哈希表(Hash Table)(一、数组交集问题)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!