- ResponseProcessor如何处理datanode侧发过来的packet ack的
- 客户端侧backoff逻辑。
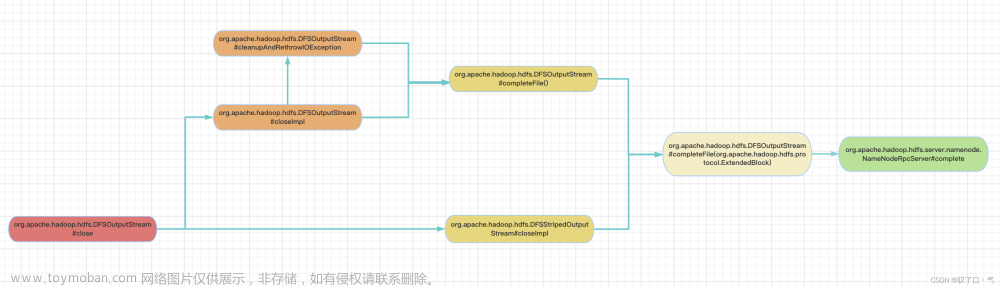
ResponseProcessor:主要功能是处理来自datanode的响应。当一个packet的响应到达时,会把这个packet从ackQueue里移除。文章来源地址https://www.toymoban.com/news/detail-681281.html
@Override
public void run() {
// 设置 ResponseProcessor 线程的名字
setName("ResponseProcessor for block " + block);
// new一个PipelineAck对象
文章来源:https://www.toymoban.com/news/detail-681281.html
到了这里,关于【HDFS】ResponseProcessor线程详解以及客户端backoff反压的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!