Stable Diffusion是一套基于Diffusion扩散模型生成技术的图片生成方案,随着技术的不断发展以及工业界对这套工程细节的不断优化,使其终于能在个人电脑上运行,本文将从github下载开始讲一讲如何使用Stable Diffusion Web UI进行AI图像的生成。
1.聊聊Diffusion
1.1 概念简介
StableDiffusion是基于扩散模型的应用,那就先来讲一讲什么是扩散模型。
我们知道在扩散模型出现之前,比较火的是GAN(对抗生成网络),GAN由生成器和判别器组成,两者相互博弈训练,最终产生较理想的输出。
但是GAN也有缺点,首先生成器和判别器不断进化的中间N个步骤完全是黑盒,无法调试。其次还有难以训练、模式坍缩等许多问题。
Diffusion模型并非新技术,而是更像是在另一个技术方向上的不断前进,相比GAN,Diffusion会将生成的每一个步骤都拆解出来进行反复训练。
好比绘制一幅简笔画,GAN是生成器和判别器不断进化,最终绘制完成简笔画。而Diffusion是将绘画的每一步拆解出来不断训练,最后完整的将所有步骤绘制出来:
1.2 讲讲原理
Duffsion是一个在图像加噪去噪过程中进行生成的模型,假设一张完全没有噪点的图像到一张充满噪点无法辨认的图像会经过1000个步骤:
那么在训练阶段,Diffusion模型首先会在这1000个步骤中随机选一步,先加噪,再通过网络去噪,反向传播时用该阶段的原始图片作为Loss。而这个加噪去噪的具体步骤,也并非直接加减,需要通过网络求出噪声变化值再减回去等,这里不做过多讲解。
这个去噪声的操作通过的就是Unet网络,这是一个残差卷积网络,因为结构呈U形所以得名。而我们输入的提示词也会先通过CLIP模型再编码进噪声中。
再后来出现了Latent Diffusion Models,即通过VAE这样的压缩技术,将原图通过VAE网络编码成一张尺寸比较小、包含潜空间数据的图片,再进行扩散处理,最终图像再通过VAE网络解码成原始图片。这项技术大大降低了显存的占用,也为后来的Stable Diffusion打下了基础。
2.Stable Diffusion Web UI
接下来讲讲实用的,关于Stable Diffusion与第三方开源的Web UI仓库。
2.1 Web UI简介
在github上直接查找StableDiffusion可以看到排名最靠前的有3个仓库:
实际上Stable Diffusion 是由 CompVis、Stability AI 和 LAION一起开发的,因此CompVis和Stability-AI的仓库地址理论上都是官方仓库。
而stable diffusion web ui实际上是一个非官方开源项目,但这个才是我么一会要用的仓库,这个仓库真正做到了开箱即用,不需要配置Cuda、不会有奇怪的报错、连基础模型都会帮你自动下载好。
2.2下载与配置
2.2.1 启动Stable Diffusion
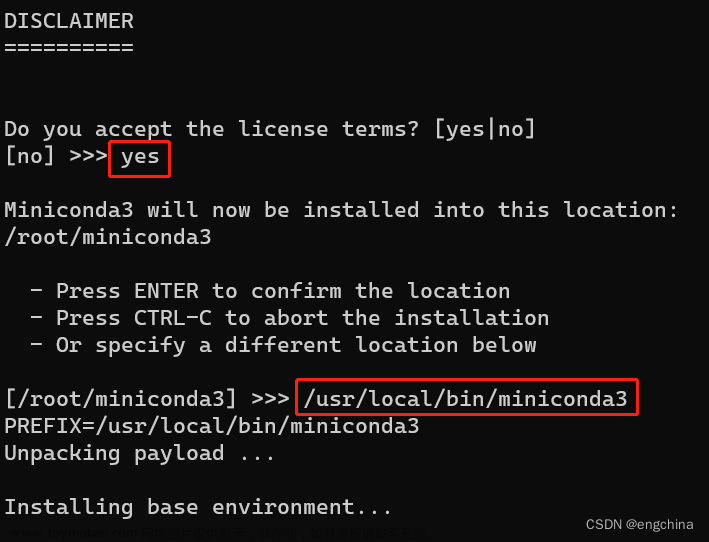
首先从AUTOMATIC1111仓库的Stable Diffusion Web UI进行下载,该仓库会自动下载StableDiffusion以及基础模型:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
根据该仓库的教程说明,最后运行webui-user.bat即可。
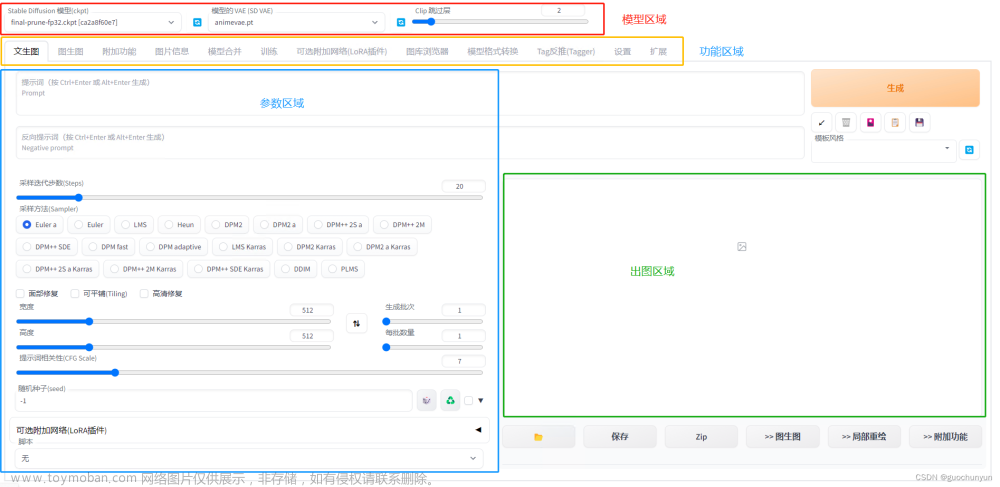
安装好并且webui-user.bat内的内容下载好后,在ip:127.0.0.1:7860可以打开StableDiffusion界面:
左上角显示的是基础模型。
2.2.2 安装大模型
像SDXL这类算作大模型,像Lora、ControlNet算小模型,小模型需要依赖大模型的版本,大模型版本改变的话小模型就会失效报错。
下载大模型需要去另外2个github仓库查找。
不想折腾,也可以在这里下载大模型:
https://rentry.org/sdmodels
https://civitai.pro/
2.2.3 安装插件
使用Stable Diffusion web ui还可以进行插件的拓展,像较流行的Lora、Control Net这些最早都不是作为SD的插件开发的,而是有正经论文的学术内容,后来才拓展的StableDiffusion插件版本。
Control Net1.1全家桶可以在hugging face上下载:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main文章来源:https://www.toymoban.com/news/detail-681448.html
还有最近短视频平台比较火的小和尚,嘴型生成SadTalker插件:
https://github.com/OpenTalker/SadTalker文章来源地址https://www.toymoban.com/news/detail-681448.html
到了这里,关于Stable Diffusion Web UI的原理与使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!