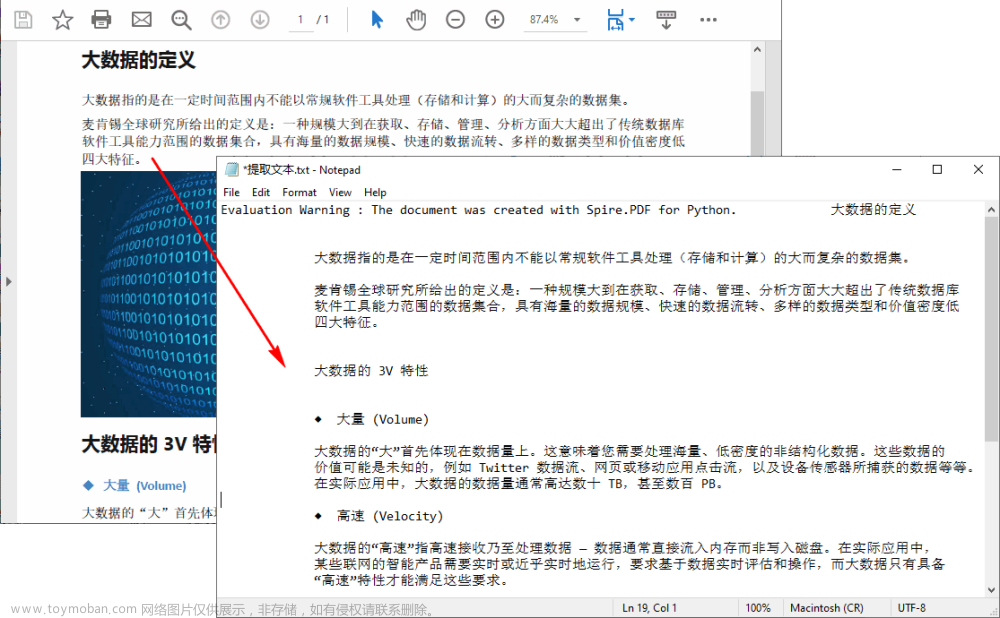
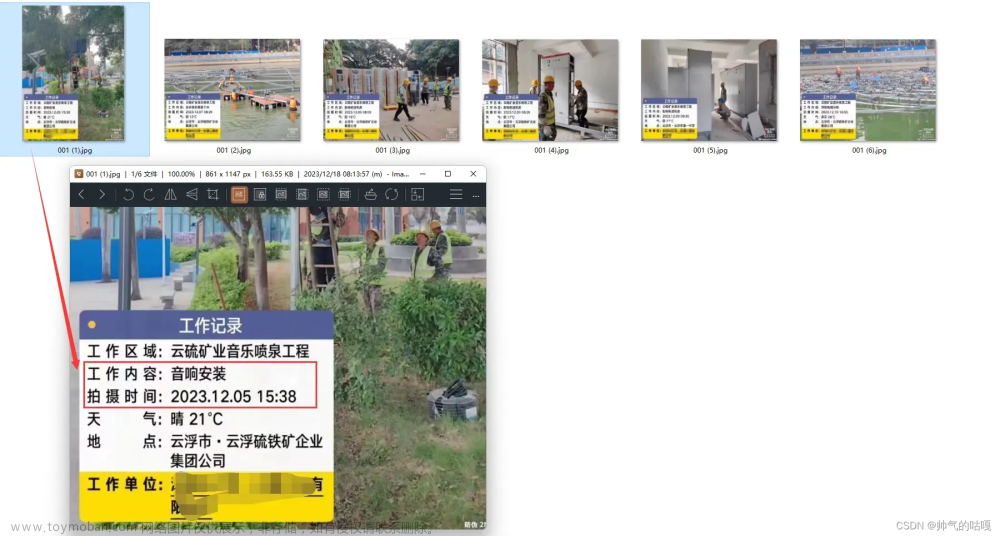
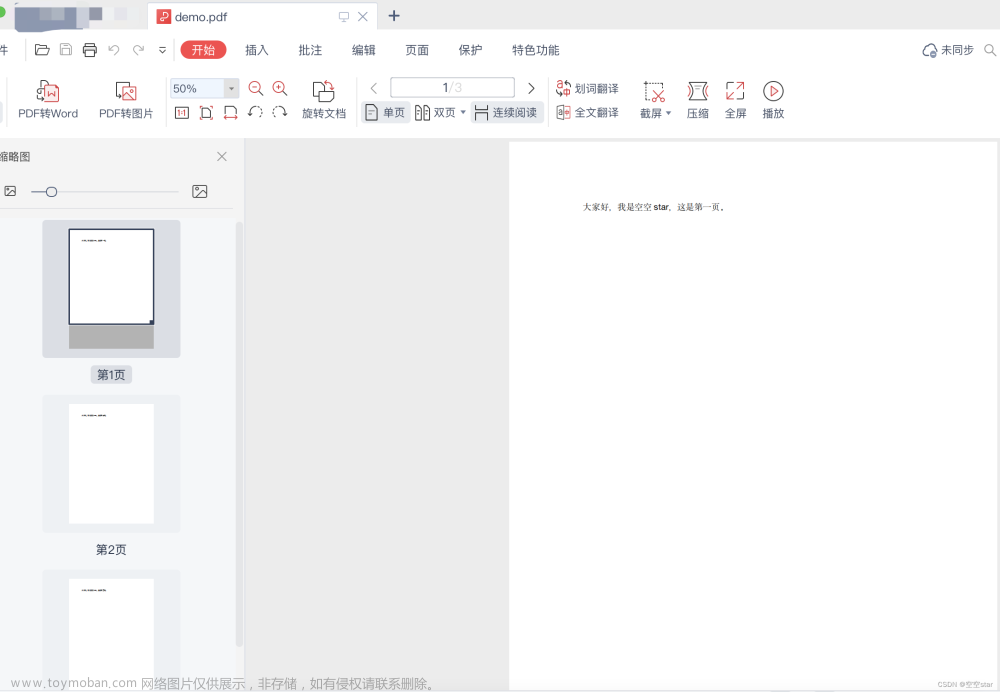
import fitz
import os
from PIL import Image
path1 = "D:/桌面/xxxxxx.pdf"
path2 = "D:/桌面/111"
def pdf2image1(path1, path2):
pdfDoc = fitz.open(path1)
for pg in range(pdfDoc.page_count):
page = pdfDoc.load_page(pg)
# 获取页面的图像对象
# matrix = fitz.Matrix(1.0, 1.0) # 1.0 表示原始尺寸
# pix = page.get_pixmap(matrix=matrix,dpi=200)
pix = page.get_pixmap(matrix=fitz.Matrix(4, 4))
print(pix.width, pix.height)
# 将图像转换为Pillow的Image对象
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
if not os.path.exists(path2): # 判断存放图片的文件夹是否存在
os.makedirs(path2) # 若图片文件夹不存在就创建
# 保存图像为PNG格式,不进行压缩
# dpi = 96 # 设置所需的 DPI 值
img.save(path2 + '/' + f'images_{pg}.jpg', )
# img.save(f'output_{page_number}.png',)
# pix.save(path2 + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内
if __name__ == "__main__":
pdf2image1(path1, path2)
文章来源地址https://www.toymoban.com/news/detail-681918.html
文章来源:https://www.toymoban.com/news/detail-681918.html
到了这里,关于python提取pdf文件中的图片并输出到本地的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!