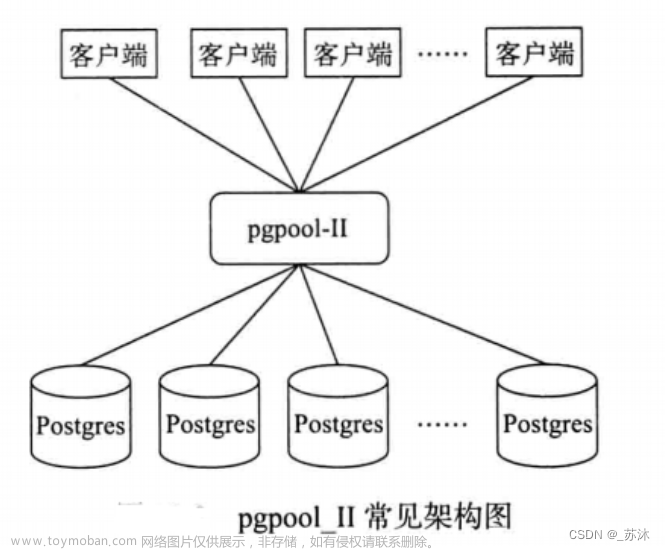
服务器点位
| NODE | IP |
|---|---|
| mgr_node0 | 192.165.26.200 |
| mgr_node1 | 192.165.25.201 |
| mgr_node2 | 192.165.26.202 |
| proxysql | 192.165.26.199 |
修改主机名
# 登录192.165.26.200
hostnamectl set-hostname mgr_node0
# 登录192.165.26.201
hostnamectl set-hostname mgr_node1
# 登录192.165.26.202
hostnamectl set-hostname mgr_node2
# 登录192.165.26.199
hostnamectl set-hostname proxysql
在所有节点修改/etc/hosts
192.165.26.200 mgr_node0
192.165.26.201 mgr_node1
192.165.26.202 mgr_node2
192.165.26.199 proxysql
运行uuidgen获取uuid
uuidgen
修改所有节点的my.cnf
[mysqld]
user=mysql
port=3306
basedir=/usr/local/mysql
datadir=/data
max_connections=200
character-set-server=utf8mb4
default-storage-engine=INNODB
# 开启binlog和relaylog
# 服务器Id(存在且唯一)
server_id=200
# 开启binlog日志
log-bin=/usr/local/mysql/log/mysql-bin.log
# 开启log_slave_update(从库会将收到的数据变更事件重新写入其自己的二进制日志中,从而保证主从同步的可靠性)
log_slave_updates=ON
# 开启reley_log
relay_log=relay-log
# Group Replication只支持Row格式的Binlog
binlog_format=ROW
# 禁用binlog_checksum
binlog_checksum=NONE
# GTID setting
# 开启gtid模式
gtid_mode=ON
# MGR setting
# Group Replication要使用到多源复制的功能,多源复制要求必须将Slave通道的状态信息存储到系统表中
master_info_repository=TABLE
relay_log_info_repository=TABLE
slave_preserve_commit_order=ON
# 除binlog外,Group Replication还需要Server层帮助采集被更新数据的主键信息。
# 该参数告诉Server层是否采集主键信息,主键信息被哈希后存储起来,目前支持两种哈希算法:XXHASH64、MURMUR32
# 该参数是专门给Group Replication准备的,默认为OFF,不采集,主键信息是Group Replication非常重要的信息,Group Replication要求每个表必须有主键,否则在更新数据时会失败
transaction_write_set_extraction=XXHASH64
# 插件的参数只能在插件加载之后设置,如果想设置这些参数到配置文件中,可以在参数前加"loose-"前缀
# 在主节点运行uuidgen生成的<a uuid>
# 每个Group Replication都需要有名字,这个名字唯一识别一个组。在初始化或加入组时,必须要设置名字,如果名字不同则不能加入
# UUID会用来标记组内所有成员产生的Binlog Event,任何成员上生成的GTID都会使用这个UUID
loose-group_replication_group_name=<a uuid>
# 在服务器启动时不启动组复制
loose-group_replication_start_on_boot=off
# 设置成员的本地地址
# 例:若本机Ip为192.168.1.200,通过20000端口来进行主从同步,格式如下:
# loose-group_replication_local_address="192.165.26.200:20000"
loose-group_replication_local_address=<ip:port>
# 设置种子成员的地址
# 当加入一个组时,新成员首先必须要和组内的成员进行通信来完成加入步骤,因此需要知道至少一个当前组内成员的地址。格式如下:
# 例:loose-group_replication_group_seeds="192.165.26.200:20000,192.165.26.201:20001,192.165.26.202:20002"
loose-group_replication_group_seeds=<ip:port,ip:port>
# Group Replication通过白名单来控制哪些IP可以加入到组里来,白名单是一个地址列表,地址可以是具体IP,也可以是网段,地址之间用逗号分隔
# loose-group_replication_ip_whitelist="192.165.26.200,192.165.26.201,192.165.26.202"
loose-group_replication_ip_whitelist=<ip,net,...>
# 初始化特有的参数
# Group Replication组的初始化是在启用第一个成员时完成的。
# 在启用第一个成员时,需要设置下面的参数,告诉Group Replication它是第一个成员:
# set GLOBAL group_replication_bootstrap_group=ON;
# 注意:这个参数只在初始化第一个成员时使用,所以不要将这个参数设置到配置文件中,并且在初始化完成后要将该变量设置为OFF
loose-group_replication_bootstrap_group=off
loose-group_replication_single_primary_mode=ture
loose-group_replication_enforce_update_everywhere_checks=false
loose-group_replication_single_primary_mode=ture
loose-group_replication_enforce_update_everywhere_checks=false
多主运行
每个mysql节点均运行
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
mysql> create user 'repl'@'%' identified by 'p@ssw0rd';
mysql> grant replication slave on *.* to 'repl'@'%';
在第一个节点执行
mysql> change master to master_user='repl',master_password='p@ssw0rd' for channel 'group_replication_recovery';
mysql> set global group_replication_bootstrap_group=on;
mysql> start group_replication;
mysql> set global group_replication_bootstrap_group=off;
在其他节点执行
mysql> change master to master_user='repl',master_password='p@ssw0rd' for channel 'group_replication_recovery';
mysql> set global group_replication_allow_local_disjoint_gtids_join=on;
mysql> start group_replication;
查看是否搭建成功
mysql> select * from performance_schema.replication_group_members;
单主运行
每个MySQL节点运行
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
mysql> create user 'repl'@'%' identified by 'p@ssw0rd';
mysql> grant replication slave on *.* to 'repl'@'%';
mysql> group_replication_enforce_update_everywhere_checks=off;
mysql> set global group_replication_single_primary_mode=on;
在主节点运行
mysql> change master to master_user='repl',master_password='p@ssw0rd' for channel 'group_replication_recovery';
mysql> set global group_replication_bootstrap_group=on;
mysql> start group_replication;
mysql> set global group_replication_bootstrap_group=off;
在从节点运行
mysql> change master to master_user='repl',master_password='p@ssw0rd' for channel 'group_replication_recovery';
mysql> set global group_replication_allow_local_disjoint_gtids_join=on;
mysql> start group_replication;
查询主节点
mysql> show variables like 'server_uuid';
mysql> show status like 'group_replication_primary_member';
group_replication_primary_member如果返回结果为空则为多主,如果不为空则显示的id的设备为主文章来源地址https://www.toymoban.com/news/detail-682181.html
ProxySQL配置(读写分离)
在集群主节点运行
-- proxysql的监控账户
mysql> create user monitor@'%' identified by 'p@ssw0rd';
mysql> grant all privileges on *.* to monitor@'%' with grant option;
-- proxysql的对外访问用户
mysql> create user proxysql@'%' identified by 'p@ssw0rd';
mysql> grant all privileges on *.* to proxysql@'%' with grant option;
配置主写从读
主节点:
mysql> set global read_only=0;
从节点
mysql> set global read_only=1;
下载proxysql的rpm包后利用yum安装
启动ProxySQL
$ systemctl start proxysql
$ netstat -anlp|grep proxysql
# 6032是管理端口
# 6033是对外服务端口
# 默认用户密码都是admin
利用MySQL客户端登录proxysql
mysql -uadmin -padmin -h 127.0.0.1 -P 6032 --prompt 'proxysql>'
配置监控账号
proxysql> set mysql-monitor_username='monitor';
proxysql> set mysql-monitor_password='p@ssw0rd';
或者
proxysql> UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username';
proxysql> UPDATE global_variables SET variable_value='p@ssw0rd' WHERE variable_name='mysql-monitor_password';
配置默认组信息
| 组名 | id |
|---|---|
| writer_hostgroup | 10 |
| backup_writer_hostgroup | 20 |
| reader_hostgroup | 30 |
| offline_hostgroup | 40 |
proxysql> insert into mysql_group_replication_hostgourps(writer_hostgroup,backup_writer_hostgroup,reader_hostgroup,offline_hostgroup,active,writer_is_also_reader)values(10,20,30,40,1,1);
配置写组用户
insert into mysql_users(username,password,default_hostgroup)values('proxysql','p@ssw0rd',10);
主节点定义为写组10,从节点定义为只读组30
insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)values (10,'192.165.26.200',3306,1,3000,10,'mgr_node0');
insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)values (30,'192.165.26.201',3306,2,3000,10,'mgr_node1');
insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)values (30,'192.165.26.202',3306,2,3000,10,'mgr_node2');
insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment)values (30,'192.165.26.200',3306,1,3000,10,'mgr_node0');
配置分离参数
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(1,1,'^SELECT.*FOR UPDATE$',10,1);
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(2,1,'^SELECT',30,1);
生效
save mysql users to disk;
save mysql servers to disk;
save mysql query rules to disk;
save mysql variables to disk;
save admin variables to disk;
load mysql users to runtime;
load mysql servers to runtime;
load mysql query rules to runtime;
load mysql variables to runtime;
load admin variables to runtime;
在MGR主节点执行 addition_to_sys.sql
USE sys;
DELIMITER $$
CREATE FUNCTION IFZERO(a INT, b INT)
RETURNS INT
DETERMINISTIC
RETURN IF(a = 0, b, a)$$
CREATE FUNCTION LOCATE2(needle TEXT(10000), haystack TEXT(10000), offset INT)
RETURNS INT
DETERMINISTIC
RETURN IFZERO(LOCATE(needle, haystack, offset), LENGTH(haystack) + 1)$$
CREATE FUNCTION GTID_NORMALIZE(g TEXT(10000))
RETURNS TEXT(10000)
DETERMINISTIC
RETURN GTID_SUBTRACT(g, '')$$
CREATE FUNCTION GTID_COUNT(gtid_set TEXT(10000))
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE result BIGINT DEFAULT 0;
DECLARE colon_pos INT;
DECLARE next_dash_pos INT;
DECLARE next_colon_pos INT;
DECLARE next_comma_pos INT;
SET gtid_set = GTID_NORMALIZE(gtid_set);
SET colon_pos = LOCATE2(':', gtid_set, 1);
WHILE colon_pos != LENGTH(gtid_set) + 1 DO
SET next_dash_pos = LOCATE2('-', gtid_set, colon_pos + 1);
SET next_colon_pos = LOCATE2(':', gtid_set, colon_pos + 1);
SET next_comma_pos = LOCATE2(',', gtid_set, colon_pos + 1);
IF next_dash_pos < next_colon_pos AND next_dash_pos < next_comma_pos THEN
SET result = result +
SUBSTR(gtid_set, next_dash_pos + 1,
LEAST(next_colon_pos, next_comma_pos) - (next_dash_pos + 1)) -
SUBSTR(gtid_set, colon_pos + 1, next_dash_pos - (colon_pos + 1)) + 1;
ELSE
SET result = result + 1;
END IF;
SET colon_pos = next_colon_pos;
END WHILE;
RETURN result;
END$$
CREATE FUNCTION gr_applier_queue_length()
RETURNS INT
DETERMINISTIC
BEGIN
RETURN (SELECT sys.gtid_count( GTID_SUBTRACT( (SELECT
Received_transaction_set FROM performance_schema.replication_connection_status
WHERE Channel_name = 'group_replication_applier' ), (SELECT
@@global.GTID_EXECUTED) )));
END$$
CREATE FUNCTION gr_member_in_primary_partition()
RETURNS VARCHAR(3)
DETERMINISTIC
BEGIN
RETURN (SELECT IF( MEMBER_STATE='ONLINE' AND ((SELECT COUNT(*) FROM
performance_schema.replication_group_members WHERE MEMBER_STATE != 'ONLINE') >=
((SELECT COUNT(*) FROM performance_schema.replication_group_members)/2) = 0),
'YES', 'NO' ) FROM performance_schema.replication_group_members JOIN
performance_schema.replication_group_member_stats USING(member_id));
END$$
CREATE VIEW gr_member_routing_candidate_status AS SELECT
sys.gr_member_in_primary_partition() as viable_candidate,
IF( (SELECT (SELECT GROUP_CONCAT(variable_value) FROM
performance_schema.global_variables WHERE variable_name IN ('read_only',
'super_read_only')) != 'OFF,OFF'), 'YES', 'NO') as read_only,
sys.gr_applier_queue_length() as transactions_behind, Count_Transactions_in_queue as 'transactions_to_cert' from performance_schema.replication_group_member_stats;$$
DELIMITER ;
查看各节点状态
mysql> SELECT * FROM sys.gr_member_routing_candidate_status;
proxysql> select * from mysql_server_group_replication_log order by time_start_us desc limit 6\G;
proxysql> SELECT * FROM monitor.mysql_server_connect_log ORDER BY time_start_us DESC LIMIT 10\G;
proxysql> SELECT* FROM monitor.mysql_server_ping_log ORDER BY time_start_us DESC LIMIT 10;
文章来源:https://www.toymoban.com/news/detail-682181.html
到了这里,关于ProxySQL+MGR高可用搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!