摘要: 分享对论文的理解, 原文见 Gabriel Fabien-Ouellet and Rahul Sarkar, Seismic velocity estimation: A deep recurrent neural-network approach. Geophysics (2020) U21–U29. 作者应该是领域专家, 对地球科学的理解胜于深度学习. 为方便讨论, 等式编号保持与原文一致.文章来源地址https://www.toymoban.com/news/detail-682694.html
1. 术语
- common-midpoint gathers (共中心点道集): 在地面的一条直线上, 从 90m 处激发 110m 处接收, 80m 处激发 120m 处接收, …, 这些数据组成了共中心点道集, 可以看作是对中心点 (100m) 处的不同观测.
论文使用这类数据, 与我们常用的单炮数据不同. - common-short-point gathers: 共炮点 CSP 道集, 即单炮数据.
- common-receiver-point gathers: 共检波点道集.
- root-mean-square velocity: 均方根速度
v r m s = ∑ i = 1 N v i 2 Δ t i ∑ i = 1 N Δ t i (2) v_\mathrm{rms} = \sqrt{\frac{\sum_{i=1}^N v_i^2 \Delta t_i}{\sum_{i=1}^N \Delta t_i}} \tag{2} vrms=∑i=1NΔti∑i=1Nvi2Δti(2)
其中 N N N 是地层的层数, Δ t i \Delta t_i Δti 是在第 i i i 层传播的时间, v i v_i vi 是在第 i i i 层传播的速度. 可见仅有一层的时候, 就是传播速度. 有多层的时候, 相当于各层速度的加权和. 传播速度越快的层, 或传播时间越长的层, 对速度的贡献越大. 也可以解释为: 越厚的层贡献越大. - semblance estimation (相似性估计): 暂时没懂意思.
- recursive CNN: 哪里冒出这个技术? 不是 RNN? 没明白.
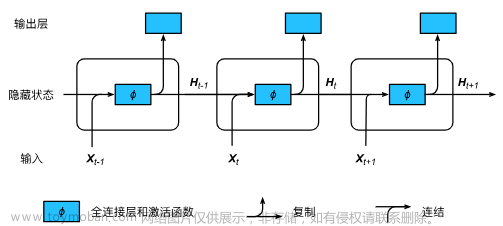
2. 主要方案
- 直接反演比较困难, 将问题简化为: 针对 1 维分层速度模型, 由共中心点道集估计时间上的均方根和区间速度. 这有点像反射系数反演, 不抛弃地球勘探已有的知识, 把两类方法结合起来.
- 用 CNN 编码, RCNN 和 LSTM 解码.
- normal moveout equation (正常时差方程), 勾股定理
t 2 = t 0 2 + x 2 / v r m s 2 (1) t^2 = t_0^2 + x^2 / v_\mathrm{rms}^2 \tag{1} t2=t02+x2/vrms2(1)
其中 t t t 是在偏移量为 x x x 位置的双向走时 (traveltime), t 0 = 2 z / v r m s t_0 = 2z/v_\mathrm{rms} t0=2z/vrms 是自激自收点的双向走时, z z z 是反射面的深度, r m s \mathrm{rms} rms 是 rms 速度.
但 x x x 不应该换成 2 x 2x 2x 吗? - NMO 校正定义为
d N M O ( t , x ) = d ( t 2 + x 2 / v r m s 2 , x ) (3) d^{\mathrm{NMO}}(t, x) = d \left(\sqrt{t^2 + x^2/v_{\mathrm{rms}}^2}, x \right) \tag{3} dNMO(t,x)=d(t2+x2/vrms2,x)(3)
其中 d d d 是原始的共炮点道集, d N M O d^{\mathrm{NMO}} dNMO 则为 NMO 校正后的道集. 进一步说明:- 考虑一个极端情况: t = 0 t = 0 t=0. 这时会把 x x x 炮点深度为 x / v r m s x/v_{\mathrm{rms}} x/vrms 的点拉到地面. 类似于常规方法的线性动校正.
- 这里的 d N M O d^{\mathrm{NMO}} dNMO 和 d d d 可以看作看作矩阵, 括号里面的参数实际上是下标.
- Semblance 定义为
S t = ∑ i = t − l t + l ( ∑ j = 1 N x d i j N M O ) 2 ∑ i = t − l t + l ∑ j = 1 N x ( d i j N M O ) 2 S_t = \frac{\sum_{i = t - l}^{t + l} \left(\sum_{j = 1}^{N_x} d_{ij}^{\mathrm{NMO}}\right)^2}{\sum_{i = t - l}^{t + l} \sum_{j = 1}^{N_x} \left(d_{ij}^{\mathrm{NMO}}\right)^2} St=∑i=t−lt+l∑j=1Nx(dijNMO)2∑i=t−lt+l(∑j=1NxdijNMO)2
其中 N x N_x Nx 是道数, l l l 为窗口长度, d i j N M O d_{ij}^{\mathrm{NMO}} dijNMO 则为 d N M O ( t , x ) d^{\mathrm{NMO}}(t, x) dNMO(t,x) 离散化的版本.
3. 主要结论
- 人造数据上训练的模型, 在实际数据上也好用 (仅限于本文简化后的问题: 均方根速度估计).
4. 其它可借鉴的地方
- Araya-Polo et al. (2018) directly predict gridded velocity models with deep NNs using semblance as input: 其实我们就是这样做的.
- Indeed, semblance is a lossy, non-invertible transform that removes the amplitude and phase information relevant for seismic inversion. This is why modern seismic inversion procedures, such as full waveform inversion (FWI), rely instead on the full recorded waveform, and why the full waveform should be the input to a neural network-based approach.
事实上,表象是一种有损的、不可逆的变换,它去除了与地震反演相关的振幅和相位信息。这就是为什么现代地震反演程序,如全波形反演(FWI),转而依赖于全记录波形,以及为什么全波形应该是神经网络方法的输入。
还是没明白“表象”是什么意思。
2.
3.
文章来源:https://www.toymoban.com/news/detail-682694.html
到了这里,关于论文笔记: 循环神经网络进行速度模型反演 (未完)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!