目录
AJAX 简介
任务目标
创建Ajax网站
创建服务器程序
编写爬虫程序
AJAX 简介
AJAX(Asynchronous JavaScript And XML,异步 JavaScript 及 XML)
- Asynchronous 一种创建交互式、快速动态网页应用的网页开发技术
- 通过在后台与服务器进行少量数据交换,无需重新加载整个网页的情况下,能够异步更新部分网页的技术。
- AJAX是一种新的技术组合,即基于因特网标准,组合以下技术:
- XMLHttpRequest 对象(与服务器异步交互数据)
- JavaScript/DOM(显示/取回信息)
- CSS(设置数据的样式)
- XML(常用作数据传输的格式)

任务目标
- 现在的网页中大量使用了Ajax技术,通过JavaScript在客户端向服务器发出请求,服务器返回数据给客户端,客户端再把数据展现出来,这样做可以减少网页的闪动, 让用户有更好的体验。
- 我们先设计一个这样的网页,然后使用 Selenium 编写爬虫程序爬取网页的数据。
创建Ajax网站
phone.html 如下:
注:phone.html 文件要位于 templates 这个目录下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body onload="init()">
<div>选择品牌<select id="marks" onchange="display()"></select></div>
<div id="phones"></div>
</body>
<script>
function init() {
var marks = new Array("华为", "苹果", "三星");
var selm = document.getElementById("marks");
for (var i = 0; i < marks.length; i++) {
selm.options.add(new Option(marks[i], marks[i]));
}
selm.selectedIndex = 0;
display();
}
function display() {
try {
var http = new XMLHttpRequest();
var selm = document.getElementById("marks");
var m = selm.options[selm.selectedIndex].text;
http.open("get", "/phones?mark=" + m, false);
http.send(null);
msg = http.responseText; //传递参数,一般post方法使用,get不传参数
obj = eval("(" + msg + ")"); //eval(”(执行的内容)”);加上圆括号的目的是迫使eval函数在运行JavaScript代码的时候强制将括号内的表达式转化为JavaScript对象。
// JS中将JSON的字符串解析成JSON数据格式
s = "<table width='200' border='1'><tr><td>型号</td><td>价格</td></tr>"
for (var i = 0; i < obj.phones.length; i++) {
s = s + "<tr><td>" + obj.phones[i].model + "</td><td>" + obj.phones[i].price + "</td></tr>";
}
s = s + "</table>";
document.getElementById("phones").innerHTML = s;
} catch (e) {
alert(e);
}
}
</script>
</html>创建服务器程序
服务器server.py程序如下:
import flask
import json
app = flask.Flask(__name__)
@app.route("/")
def index():
return flask.render_template("phone.html")
@app.route("/phones")
def getPhones():
mark = flask.request.values.get("mark")
phones = []
if mark == "华为":
phones.append({"model": "P9", "mark": "华为", "price": 3800})
phones.append({"model": "P10", "mark": "华为", "price": 4000})
elif mark == "苹果":
phones.append({"model": "iPhone5", "mark": "苹果", "price": 5800})
phones.append({"model": "iPhone6", "mark": "苹果", "price": 6800})
elif mark == "三星":
phones.append({"model": "Galaxy A9", "price": 2800})
s = json.dumps({"phones": phones}) # python对象转化为json字符串
return s
app.run()
网站结果如下:

编写爬虫程序
(1) 创建一个浏览器对象driver,使用这个driver对象模拟浏览器。
(2) 访问http://127.0.0.1:5000网站,爬取第一个页面的手机数据。
(3) 从第一个页面中获取<select>中所有的选择项目options。
(4) 循环options中的每个option,并模拟这个option的click点击动作,触发 onchange
爬虫程序 WebScraper.py 如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
def spider(index):
trs = driver.find_elements(By.TAG_NAME, "tr")
for i in range(1, len(trs)): # 从第二行开始查找和提取
# print(i)
tds = trs[i].find_elements(By.TAG_NAME, "td")
model = tds[0].text
price = tds[1].text
print("%-16s%-16s" % (model, price))
select = driver.find_element(By.ID, "marks")
options = select.find_elements(By.TAG_NAME, "option")
if index < len(options) - 1:
index += 1
options[index].click()
time.sleep(3)
spider(index)
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome()
driver.get("http://127.0.0.1:5000")
spider(0) # 从option=0开始
driver.close()
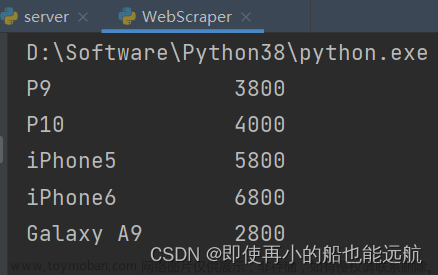
运行结果:
 文章来源:https://www.toymoban.com/news/detail-683052.html
文章来源:https://www.toymoban.com/news/detail-683052.html
下一篇文章:5.6 Selenium等待HTML元素文章来源地址https://www.toymoban.com/news/detail-683052.html
到了这里,关于【爬虫】5.5 Selenium 爬取Ajax网页数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!