Deep learning methods for medical image fusion: A review
摘要
基于深度学习的图像融合方法是近年来计算机视觉领域的研究热点。
本文从五个方面对这些方法进行了综述:
首先,阐述了基于深度学习的图像融合方法的原理和优点;
其次,从端到端和非端到端两方面对图像融合方法进行了总结,根据深度学习在特征处理阶段的不同任务,将非端到端图像融合方法分为决策映射深度学习和特征提取深度学习两大类。
根据网络类型的不同,将端到端图像融合方法分为三类:
基于卷积神经网络的图像融合方法、基于生成对抗网络的图像融合方法和基于编码器-解码器网络的图像融合方法;
第三,从方法和数据集两个方面总结了基于深度学习的图像融合方法在医学图像领域的应用;
第四,从14个方面对医学图像融合领域常用的评价指标进行了梳理;
第五,从数据集和融合方法两个方面讨论了医学图像融合面临的主要挑战。
并对未来的发展方向进行了展望。本文系统总结了基于深度学习的图像融合方法,对多模态医学图像的深入研究具有积极的指导意义。
引言
图像融合算法可分为两类:变换域算法和空间域算法。
基于变换域的算法通常基于多尺度变换(MST)理论,如拉普拉斯金字塔变换(LP)、小波变换(WT)、曲线波变换(CVT)和非下采样Contourlet变换(NSCT)。这些方法的步骤如下:首先将源图像分解为系数,然后通过融合规则对系数进行融合,最后通过变换逆重构融合后的图像。除了MST方法外,近年来还提出了一些基于特征空间的方法,如独立分量分析(ICA)和稀疏表示(SR)。然而,这些方法都存在一些缺点:融合规则由开发者设计,融合图像需要配准,图像重建也会导致图像质量下降。
基于空间域的算法不需要将源图像转换为另一个特征域,它具有很好的应用前景,可分为基于块的、基于区域的和基于像素的融合算法。基于分块的算法通常将图像分割成块,测量其空间频率,求和并修改拉普拉斯,然后融合图像块,在这些算法中,图像块的大小对结果影响很大,难以分割;基于区域的算法根据一定的准则将输入图像分解成区域,然后测量相应区域的显著性,最后将最显著的区域组合成融合图像。但是图像分割的准确性对算法的效率有很大的影响。基于像素的算法直接通过活动水平度量策略生成融合决策图,并提出了一些基于像素的空间域方法,如多尺度加权梯度融合(MWGF)、带引导滤波的图像融合(GFF)和密集SIFT,这些方法在融合过程中基于单个像素,忽略了信息的相似性。
近年来,深度学习的发展推动了图像融合的进步,深度学习强大的特征提取和数据表达能力使得图像融合的发展非常有前景。深度学习方法从大量数据中学习具有良好泛化能力的融合模型,可以使融合过程更具鲁棒性,克服人工特征选择耗时、成本高、容易出现人为错误等缺点,显示出强大的发展潜力。
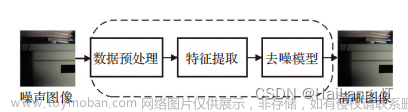
基于深度学习的图像融合分为三个阶段:特征处理阶段、特征融合阶段和特征重构阶段。
具体过程如下:首先,通过深度学习网络获取特征信息或决策图;然后,它们通过融合策略进行融合。最后,通过特征处理反变换得到融合图像。由于深度学习网络在特征提取和信息表达方面的强大能力,可以显著提高融合图像的质量。
本文将基于深度学习的融合方法分为两类:非端到端图像融合方法和端到端图像融合方法。
非端到端的融合方法
非端到端图像融合方法是指深度学习网络在融合阶段之前的特征处理阶段的应用。其过程如下:首先,通过深度学习网络对源图像进行处理,得到特征信息或决策图;然后,根据融合规则对特征进行融合;最后,对融合后的特征进行重构,得到最终的融合图像。
有效的特征处理方法是高质量融合方法的前提,图像表示理论的发展对图像融合的进展有很大的影响,促进了融合规则的进一步完善。本节将从两个方面进行介绍:基于深度学习的决策映射和基于深度学习的特征提取。
基于深度学习的决策映射
首先,将源图像分成块,将这些块作为网络的输入,并构造分类任务来判断每个块的类别;其次,通过对特征图进行线性卷积、非线性激活和空间池化,对不同阶段的特征图进行合并,输出包含源图像特征信息的决策图;第三,对决策图进行处理;最后,利用融合规则对决策映射进行融合,得到最终的融合图像。
第一类是基于CNN的决策映射。Wang等人将分解后的高频子带输入到CNN中生成决策图,并将CNN作为频率子带的融合规则,该规则不仅具有自适应性,而且取代了需要人工设计的传统规则,然后分别对低频子带和高频子带的决策图进行融合,最后对融合系数进行逆变换,得到最终的融合图像。
第二类是基于ResNet的决策映射。为了解决边界模糊水平估计困难的问题,提出将源图像输入到卷积块和残差块组成的CNN中,提取浅特征和深特征,得到其对应的加权映射,对其进行点积和加权和运算,得到融合图像。该方法可以利用源图像中存在的互补信息
第三类是基于DenseNet的决策映射。Gai等人将源图像块输入到DenseNet中得到评分图,然后通过二值化得到决策图,最后利用融合规则得到融合图像。在特征处理阶段,DenseNet可以充分利用图像的特征信息,有效地解决融合图像决策图的分类问题
第四类是基于U-Net的决策映射,为了提高U-Net的全局特征编码能力,引入全局特征金字塔提取模块(GFPE)和全局注意力连接上采样模块(GACU),有效地提取和利用全局语义和边缘信息,通过特征图中像素间的上下文关系估计最终的决策图,最后采用逐像素加权平均策略获得融合图像
第五类是基于GAN的决策映射。Guo等人提出了一种基于cGAN的图像融合方法,称为融合GAN。该方法将图像融合任务视为从源图像到决策图的转换问题,并利用最小二乘GAN目标提高融合GAN的训练稳定性,得到准确的置信图用于焦点区域检测
基于深度学习的特征提取

深度学习中特征提取的过程是:首先将源图像输入深度学习网络进行特征提取,然后将各输出层的特征信息通过融合规则进行融合,最后通过重构过程得到融合后的图像。网络的输入是源图像,输出是特征信息。这些过程如图3所示。深度学习方法具有比传统方法更强的特征提取能力,被广泛应用于图像融合领域。
第一类是基于CNN,提取源图像的低级和高级特征,得到候选融合图像,利用最大值策略从候选融合图像生成最终融合图像,完成融合图像的重建。
第二类是基于ResNet的特征提取。使用ResNet50作为特征提取模块,从源图像中提取深度特征,然后将深度特征归一化得到初始权值图,最后采用加权平均策略重构融合后的图像。
第三类是基于DenseNet的提取。Zhang等人使用DenseNet通过密集连接提取特征并重用特征,以更少的参数和计算成本取得了比CNN更好的性能,最后通过平均融合策略重建融合后的图像。用更少的网络层保留了更多的融合图像细节
第四节课是基于注意机制的特征抽取。提出了多尺度剩余金字塔注意网络(MSRPAN),与剩余注意机制相比,MSRPAN增加了多尺度信息,与金字塔注意机制相比,MSRPAN增强了特征提取能力,具有更好的特征提取和表达能力
端到端图像融合方法
在非端到端图像融合方法中,有时特征提取阶段的最优特征并不是最终的最佳结果
端到端图像融合是指网络的输入是源图像,输出是融合后的图像。整个学习过程不划分子过程,深度学习模型学习从源图像到融合图像的映射。端到端图像融合方法包括基于CNN的图像融合方法、基于GAN的图像融合方法和基于编码器-解码器网络的图像融合方法。对端到端图像融合方法进行了综述。
基于卷积神经网络(CNN)的图像融合方法
通过设计网络结构和损失函数实现隐式特征提取、特征融合和图像重建,避免了人工设计融合规则的局限性。基于CNN的图像融合方法的过程是:首先将源图像输入CNN进行处理,然后对处理后的特征进行融合,最后对融合后的图像进行反卷积重构。在这个过程中,不需要中间结果的输出,CNN学习了从输入到输出的直接映射。与传统的图像融合算法相比,CNN可以通过学习卷积滤波器的适当参数来适应图像融合任务,并且可以通过端到端训练来优化CNN模型的参数。本节从单级特征融合方法、多级特征融合方法、基于ResNet的图像融合方法和基于DenseNet的图像融合方法四个方面对基于CNN的图像融合方法进行了总结,这些过程如图4所示
单级特征融合方法
首先通过多个卷积块提取源图像的特征,然后对最后一个卷积层输出的特征进行融合,最后通过多个反卷积块对特征进行重构,得到最终的融合图像。
UFA-FUSE利用卷积块从源图像中提取图像特征,然后通过注意机制进行特征融合,最后将融合后的图像特征输入级联卷积块中重建融合后的图像,该方法通过后处理细化决策图,避免中间决策图的生成,实现图像融合
为了提高图像融合的质量,在基于多尺度MobileNet的融合(Multi-scale MobileNet based fusion, MMF)中,通过多尺度移动块(Multi-scale Mobile Block, MMB)提取输入图像的高维特征,结合高维特征生成融合图像
多级特征融合
首先通过卷积块提取源图像的特征,然后将每一卷积层提取的对应层的特征进行融合,将每一层的融合特征进行融合,生成最终的融合图像。多层次特征融合可以使图像特征得到更充分的利用。
在HPCFNet中,首先将配对图像输入到Siamese CNN中,然后通过配对通道融合(paired Channel Fusion, PCF)模块对卷积层的特征映射进行层次化集成,生成逐通道融合特征映射,再通过反向空间注意(Reverse Spatial Attention, RSA)模块对融合特征映射进行调整。PCF首先通过交叉特征堆栈(Cross feature Stack, CFS)组合同一级别的特征映射,然后通过并行群卷积(Parallel Atrous Group Convolution, PAGC)模块融合通道对,获取多尺度特征表示
基于残差神经网络的图像融合方法
在基于CNN的融合方法中,浅层特征随着网络层数的增加而松散,降低了融合效果。基于ResNet的融合方法可以更好地利用提取的特征信息,融合后的图像可以保留更多的源图像细节。这些方法可以分为两类:用于图像融合的全局残差连接和用于图像融合的残差块。

第三类是多尺度残差块。接收野较小的卷积层可以提取低频特征,但不能提取高频特征,而接收野较大的卷积层可以提取更重要的图像特征。Song等人设计了多尺度扩展残差块(MDRB),通过两个并行卷积核提取多尺度特征,并将特征输入到两个不同扩展率的卷积核中,扩大接收场,计算成本较低
残差注意块是通过在残差块上添加一个注意机制来实现的,残差块根据源特征映射的重要性给出其权重,残差连接使注意机制能够全局学习每个通道的权重,大大增强了注意块的通用性。Mustafa等人引入残差自注意块来融合和细化特征,残差自注意块的输出是原始局部特征和注意图的加权和,其中还包含自注意信息和全局上下文信息
基于密集神经网络(DenseNet)的图像融合方法

基于DenseNet的图像融合方法是指在CNN中加入密集连接,或者用密集块代替卷积块。这些过程如图7所示。DenseNet能够利用浅层的低复杂度信息获得更平滑的决策函数,因此具有更好的泛化性能[42]。与残块相比,致密块具有更强的致密连接机制。通过密集连接,可以充分利用每一层的特征,保证融合后的图像包含更多源图像的多尺度、多层次特征,缓解梯度消失的问题。
基于生成对抗网络的图像融合方法
自2014年GAN[46]被提出以来,由于其灵活性和优异的性能,在成像领域得到了广泛的应用。基于GAN的图像融合过程可以看作是源图像与融合图像之间的对抗博弈,更具体地说,基于GAN的图像融合方法使用鉴别器迫使生成器生成在概率分布上与目标分布一致的融合结果,从而隐含地实现了特征提取、融合和图像重建。这使得融合图像能够同时获得两个源图像的特征信息。这些过程如图8所示。基于GAN的图像融合方法可分为三类:基于经典GAN的图像融合方法、基于双鉴别器GAN的图像融合方法和基于多GAN的图像融合方法。
基于编码器-解码器网络的图像融合方法

基于单编码器-解码器网络的图像融合方法是指包含一个编码器的融合网络,其过程为:将拼接后的图像输入到编码器中提取特征;然后,对编码特征进行融合;最后对融合特征进行解码,得到最终的融合图像。
DenseFuse是一个典型的编码器-解码器图像融合网络,其中编码器由卷积块和密集块组成,密集块可以更好地保留编码器的深度特征,从而保证融合规则可以使用更重要的特征,融合层的输出是解码器的输入,解码器由四个卷积层完成
基于双编码器-解码器网络的图像融合方法源图像在单编码器-解码器融合网络的输入端进行拼接,但不同模态的图像具有不同的细节信息,需要以不同的方式提取特征,因此提出了双编码器-解码器融合网络。每个编码器的目的都是提取图像的视觉特征,其优点是保证两幅模态图像的不同信息能够得到充分利用。文章来源:https://www.toymoban.com/news/detail-683181.html
由于在图像融合任务中往往需要融合两幅以上的图像,现有的方法大多以两幅图像的融合为目标,为了在融合多模态医学图像的同时保留各种图像类型的更详细信息,提出了多编码器-解码器融合网络,通过信息共享获得更好的融合结果。文章来源地址https://www.toymoban.com/news/detail-683181.html
到了这里,关于医学图像融合的深度学习方法综述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!