scrapy概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
scrapy安装
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
最开始安装了低版本 报错builtins.AttributeError: module 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD' 升级到最新版本2.10.0 没有问题
scrapy使用
scrapy创建项目及结构
创建项目
scrapy startproject 项目名称

scrapy自定义爬虫类
创建爬虫文件
scrapy genspider 爬虫文件名称 网页地址
scrapy genspider MyTestSpider www.baidu.com
一般情况下不需要添加http协议, 因为start urls的值是根据allowed domains修改的 ,所以添加了http的话,那么start urls就需要我们手动去修改
import scrapy
class MytestSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'MyTestSpider'
# 允许访问的域名
allowed_domains = ['www.baidu.com']
# 起始的ur]地址 指的是第一次要访问的域名
start_urls = ['http://www.baidu.com/']
def parse(self, response):
pass
scrapy response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract 提取seletor对象的data属性值
response.extract_first 提取seletor列表的第一个值
scrapy启动爬虫程序
scrapy crawl 爬虫名称
scrapy crawl MyTestSpider

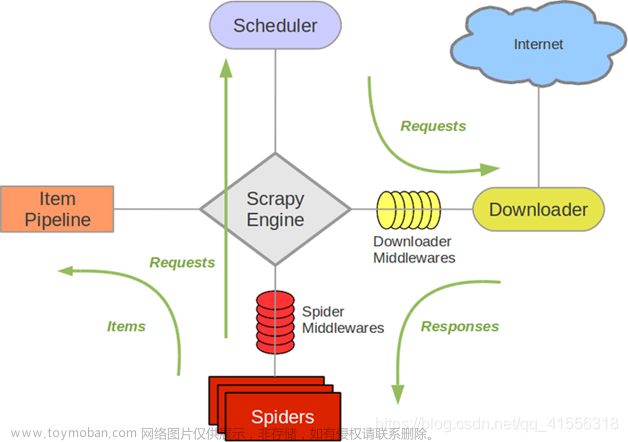
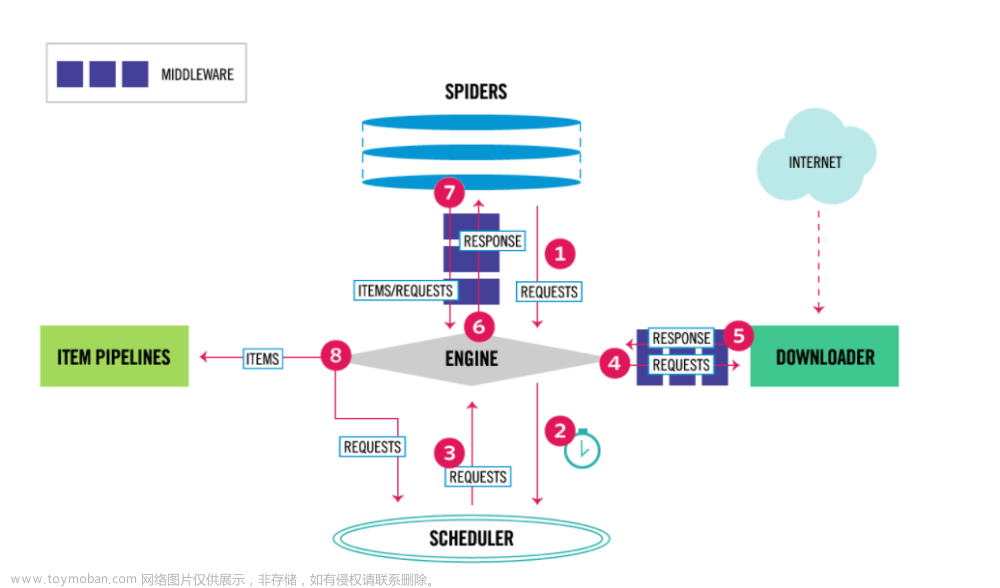
scrapy原理
1、引擎向spiders要url
2、引擎学将要爬取的url给调度器
3、调度器会将url生成请求对象放到指定的队列中,从队列中发起一个请求
4、引擎将请求交给下载器进行处理
5、下载器发送请求获取互联网数据
6、将数据返回给下载器
7、下载器将数据返回给引擎
8、引擎将数据给spiders
9、spiders解析数据,交给引擎,如果发起第二次请求,会再次交给调度器
10、引擎将数据交给管道
scrapy爬虫案例
创建项目
scrapy startproject movie
创建spider
scrapy genspider mv https://www.dytt8.net/html/gndy/china/index.html
import scrapy
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dytt8.net"]
start_urls = ["https://www.dytt8.net/html/gndy/china/index.html"]
def parse(self, response):
pass
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
编写管道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MoviePipeline:
# 执行之前执行
def open_spider(self, spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
# 执行之后执行
def close_spider(self,spider):
self.fp.close()settings.py开启管道
BOT_NAME = "movie"
SPIDER_MODULES = ["movie.spiders"]
NEWSPIDER_MODULE = "movie.spiders"
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
"movie.pipelines.MoviePipeline": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
编写爬虫程序
import scrapy
from movie.items import MovieItem
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dytt8.net"]
start_urls = ["https://www.dytt8.net/html/gndy/china/index.html"]
def parse(self, response):
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
#第二页的地址是
url = 'https://www.dytt8.net' + href
# 对第二页的链接发起访问
yield scrapy.Request(url=url, callback=self.parse_second,meta={'name':name})
def parse_second(self,response):
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name']
movie = MovieItem(src=src, name=name)
# 返回给管道
yield movie运行并查看结果
进入spider目录下,执行 scrapy crawl mv文章来源:https://www.toymoban.com/news/detail-683194.html
 文章来源地址https://www.toymoban.com/news/detail-683194.html
文章来源地址https://www.toymoban.com/news/detail-683194.html
到了这里,关于python scrapy框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!